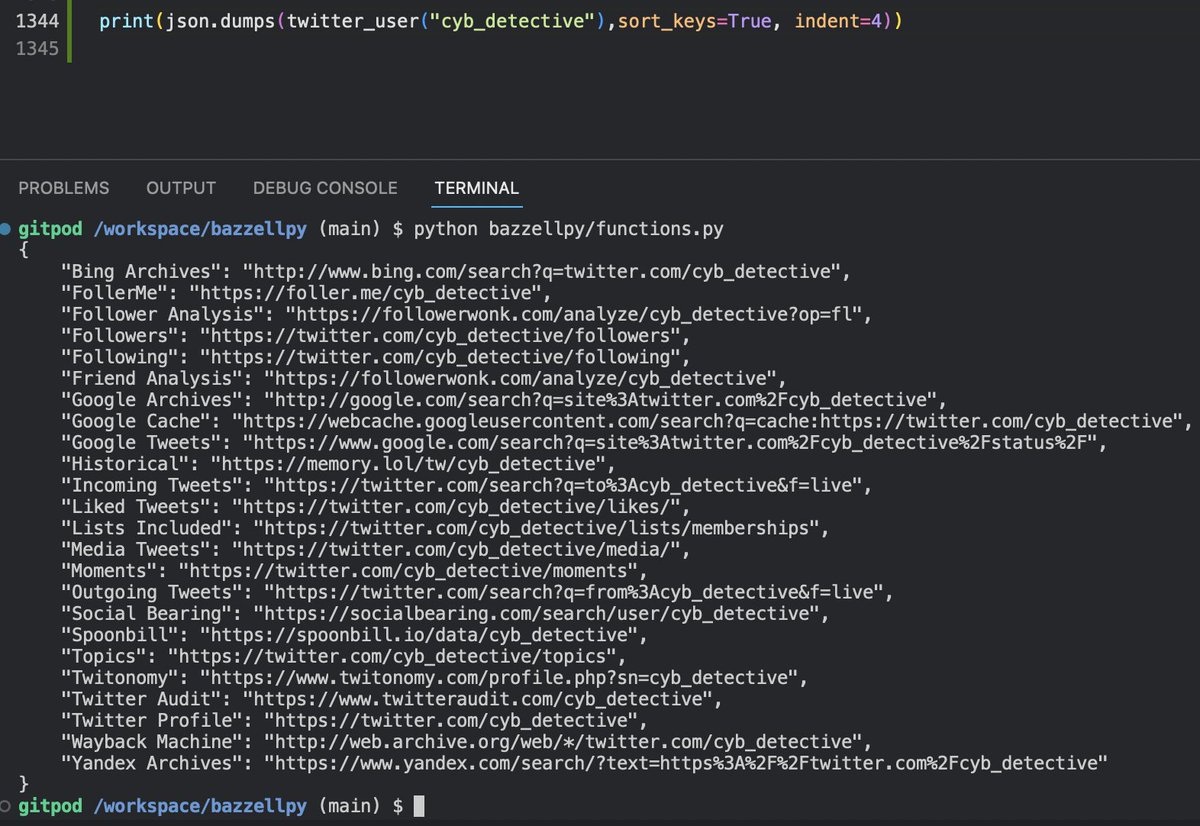
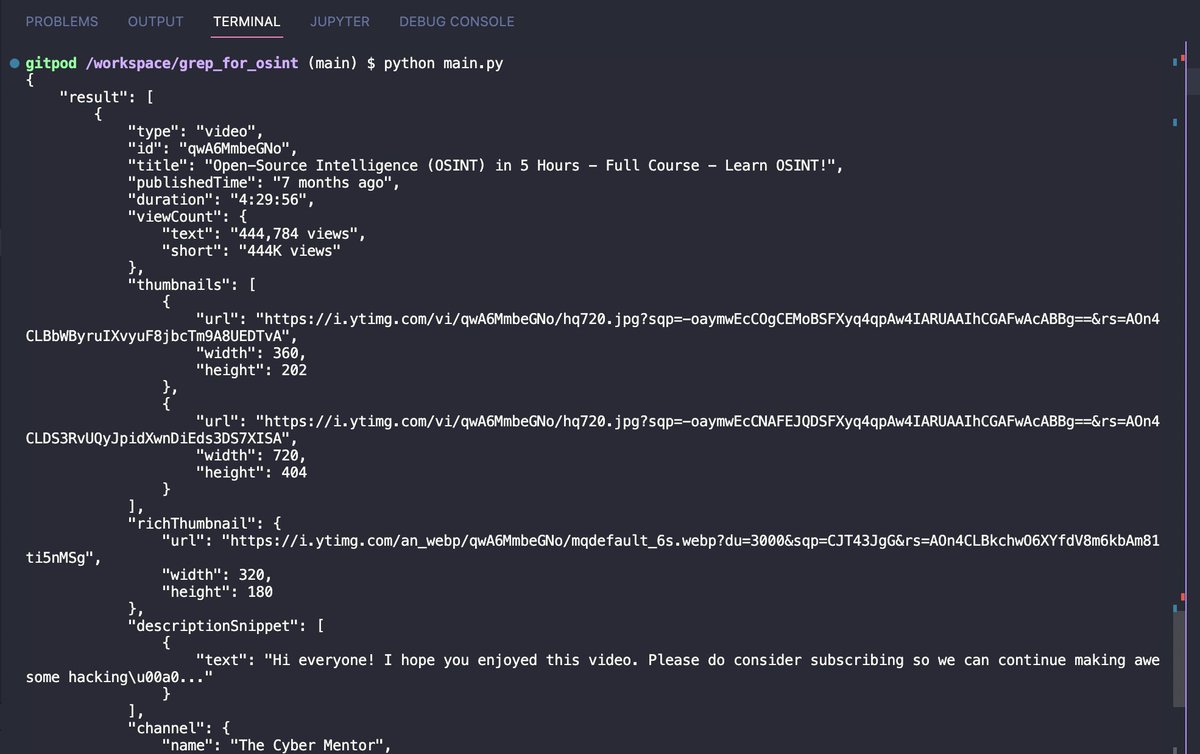
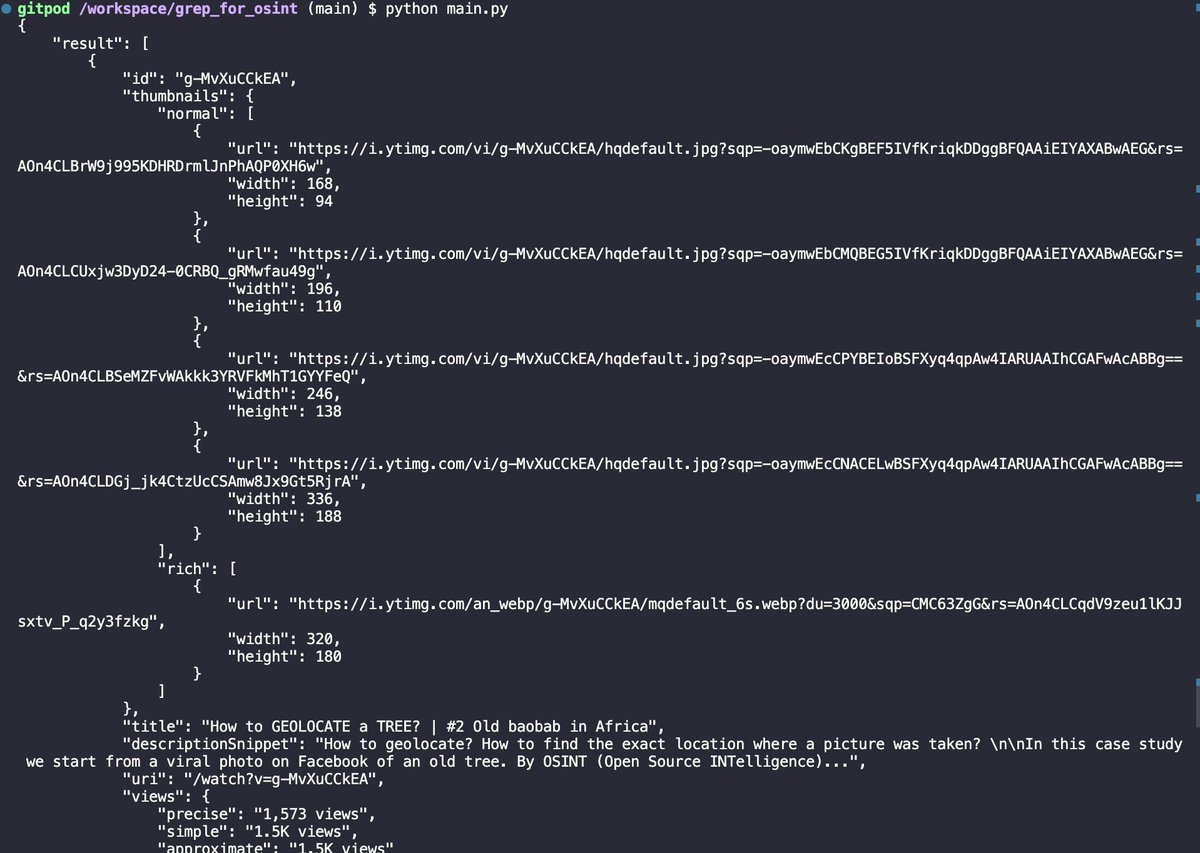
How to automated search YouTube videos with Python without using API key?
Use this package pypi.org/project/youtub…
#osintautomation
⬇️🧵
Use this package pypi.org/project/youtub…
#osintautomation
⬇️🧵



And here are pictures of the results of the 3 code samples above.
If you want to run these examples yourself, you can copy them from this repository on Github
github.com/cipher387/Pyth…
🧵⬆️⬇️ #osintautomation
If you want to run these examples yourself, you can copy them from this repository on Github
github.com/cipher387/Pyth…
🧵⬆️⬇️ #osintautomation

@threader compile
@threadreaderapp unroll
@threadRip unroll
@PingThread unroll
@ThreadReaders unroll
@TurnipSocial save
@Readwiseio save thread
@tresselapp save thread
@rattibha unroll
@getnaked_bot unroll
@threadreaderapp unroll
@threadRip unroll
@PingThread unroll
@ThreadReaders unroll
@TurnipSocial save
@Readwiseio save thread
@tresselapp save thread
@rattibha unroll
@getnaked_bot unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh