
What is a 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗦𝘁𝗼𝗿𝗲 and why is it such an important element in 𝗠𝗟𝗢𝗽𝘀 𝗦𝘁𝗮𝗰𝗸?
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
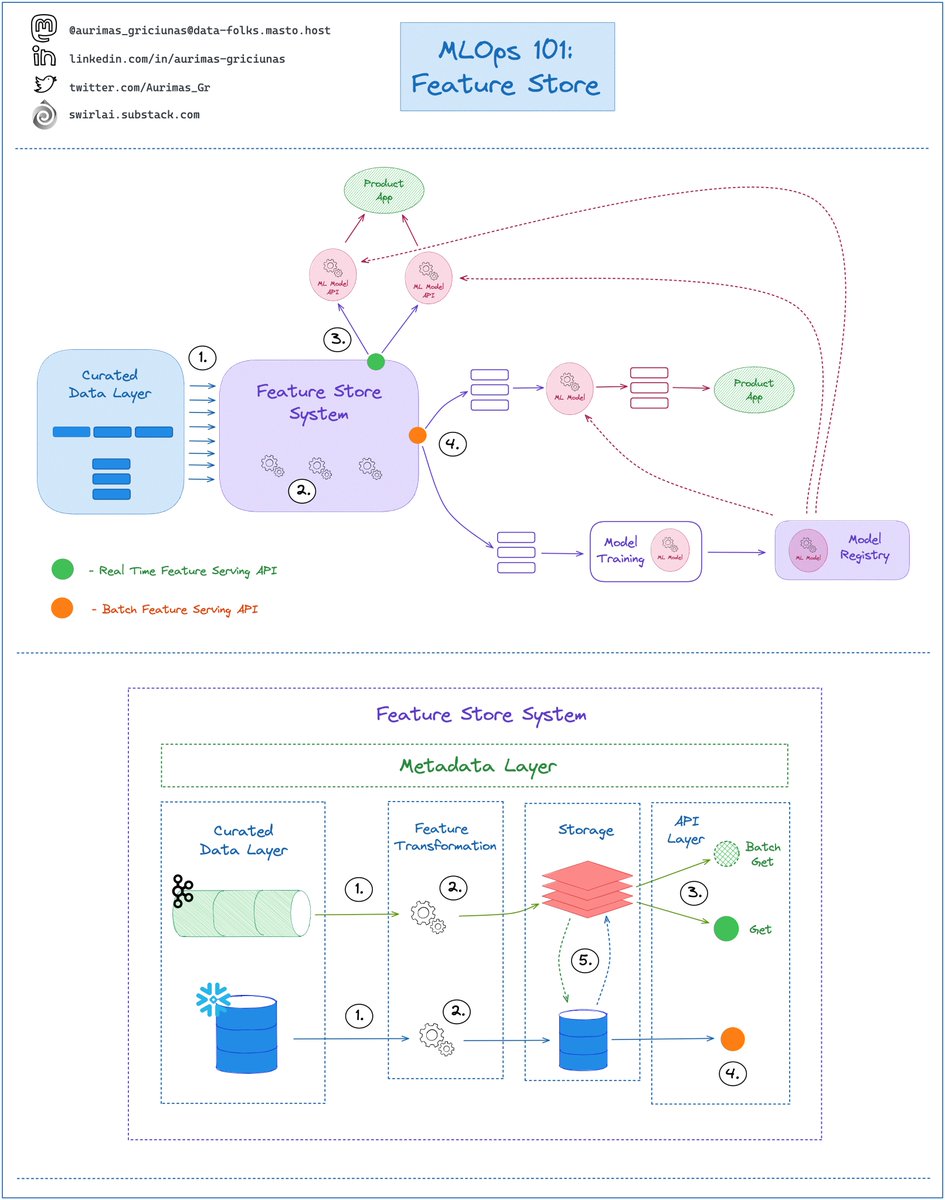
Feature Store System sits between Data Engineering and Machine Learning Pipelines and it solves the following issues:
➡️ Eliminates Training/Serving skew by syncing Batch and Online Serving Storages (5)
👇
➡️ Eliminates Training/Serving skew by syncing Batch and Online Serving Storages (5)
👇
➡️ Enables Feature Sharing and Discoverability through the Metadata Layer - you define the Feature Transformations once, enable discoverability through the Feature Catalog and then serve Feature Sets for training and inference purposes trough unified interface (4️,3).
👇
👇
The ideal Feature Store System should have these properties:
1️⃣ It should be mounted on top of the Curated Data Layer
👇
1️⃣ It should be mounted on top of the Curated Data Layer
👇
👉 the Data that is being pushed into the Feature Store System should be of High Quality and meet SLAs, trying to Curate Data inside of the Feature Store System is a recipe for disaster.
👉 Curated Data could be coming in Real Time or Batch.
👇
👉 Curated Data could be coming in Real Time or Batch.
👇
2️⃣ Feature Store Systems should have a Feature Transformation Layer with its own compute.
👉 This element could be provided by the vendor or you might need to implement it yourself.
👇
👉 This element could be provided by the vendor or you might need to implement it yourself.
👇
👉 The industry is moving towards a state where it becomes normal for vendors to include Feature Transformation part into their offering.
👇
👇
3️⃣ Real Time Feature Serving API - this is where you retrieve Features for low latency inference. The System should provide two types of APIs:
👉 Get - you fetch a single Feature Vector.
👉 Batch Get - you fetch multiple Feature Vectors at the same time with Low Latency.
👇
👉 Get - you fetch a single Feature Vector.
👉 Batch Get - you fetch multiple Feature Vectors at the same time with Low Latency.
👇
4️⃣ Batch Feature Serving API - this is where you fetch Features for Batch inference and Model Training. The API should provide:
👇
👇
👉 Point in time Feature Retrieval - you need to be able to time travel. A Feature view fetched for a certain timestamp should always return its state at that point in time.
👇
👇
👉 Point in time Joins - you should be able to combine several feature sets in a specific point in time easily.
👇
👇
5️⃣ Feature Sync - whether the Data was ingested in Real Time or Batch, the Data being Served should always be synced. Implementation of this part can vary, an example could be:
👇
👇
👉 Data is ingested in Real Time -> Feature Transformation Applied -> Data pushed to Low Latency Read capable Storage like Redis -> Data is Change Data Captured to Cold Storage like S3.
👇
👇
👉 Data is ingested in Batch -> Feature Transformation Applied -> Data is pushed to Cold Storage like S3 -> Data is made available for Real Time Serving by syncing it with Low Latency Read capable Storage like Redis.
👇
👇
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 3000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: swirlai.substack.com/p/sai-10-airfl…
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 3000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: swirlai.substack.com/p/sai-10-airfl…
• • •
Missing some Tweet in this thread? You can try to
force a refresh






