
🔨 Founder & CEO @ SwirlAI
📖 Writing about #LLM, #AI, #DataEngineering, #MachineLearning and #Data
✍️ Author of SwirlAI Newsletter.
 I believe that the following is a correct order to start in 𝗬𝗼𝘂𝗿 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗮𝘁𝗵:
I believe that the following is a correct order to start in 𝗬𝗼𝘂𝗿 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗮𝘁𝗵: Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.
Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.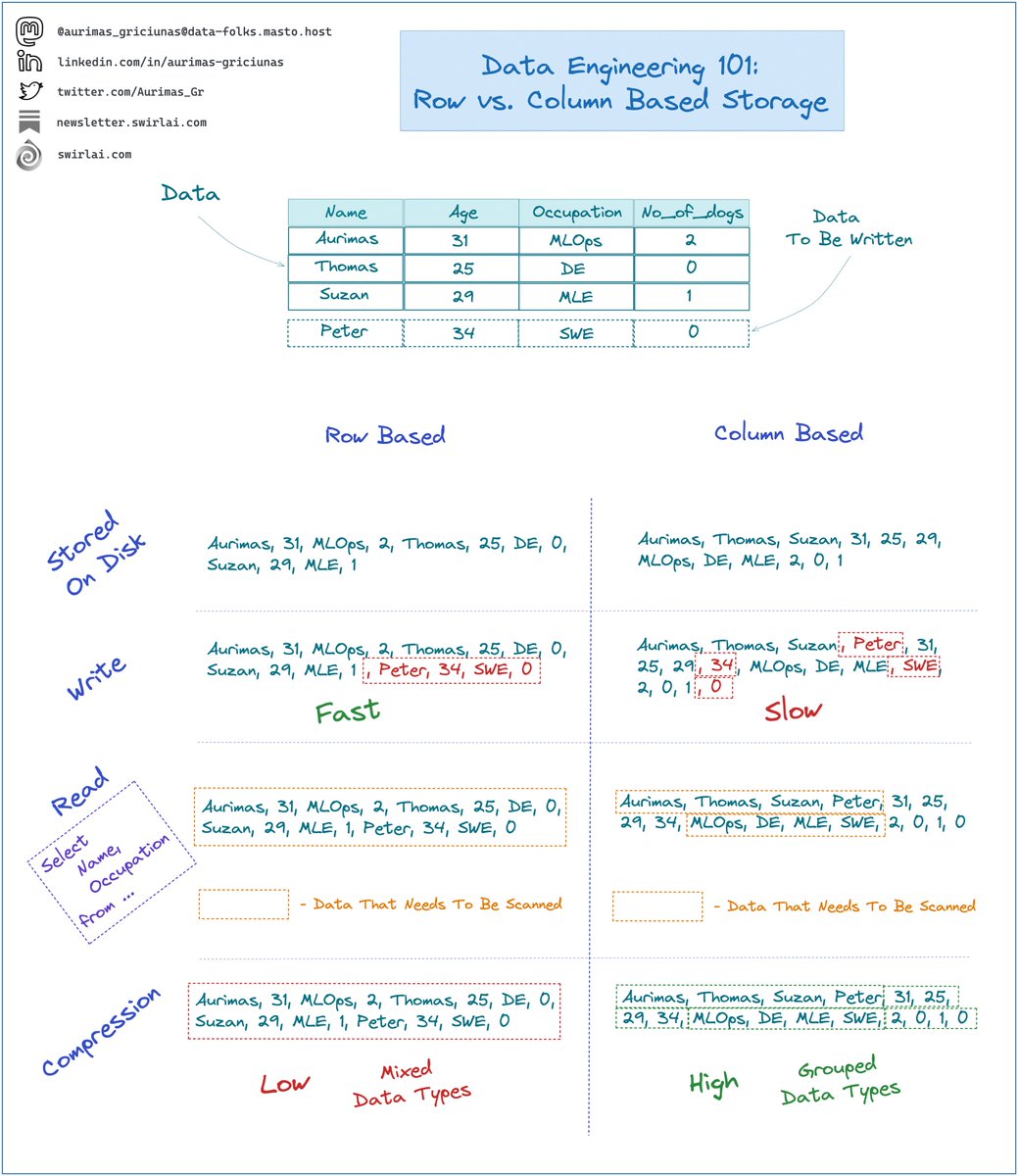 𝗥𝗼𝘄 𝗕𝗮𝘀𝗲𝗱:
𝗥𝗼𝘄 𝗕𝗮𝘀𝗲𝗱: We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer?
We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer? Usually MLOps Engineers are professionals tasked with building out the ML Platform in the organization.
Usually MLOps Engineers are professionals tasked with building out the ML Platform in the organization.  You are very likely to run into a 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗼𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 in your career. It could be 𝗦𝗽𝗮𝗿𝗸, 𝗛𝗶𝘃𝗲, 𝗣𝗿𝗲𝘀𝘁𝗼 or any other.
You are very likely to run into a 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗼𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 in your career. It could be 𝗦𝗽𝗮𝗿𝗸, 𝗛𝗶𝘃𝗲, 𝗣𝗿𝗲𝘀𝘁𝗼 or any other. 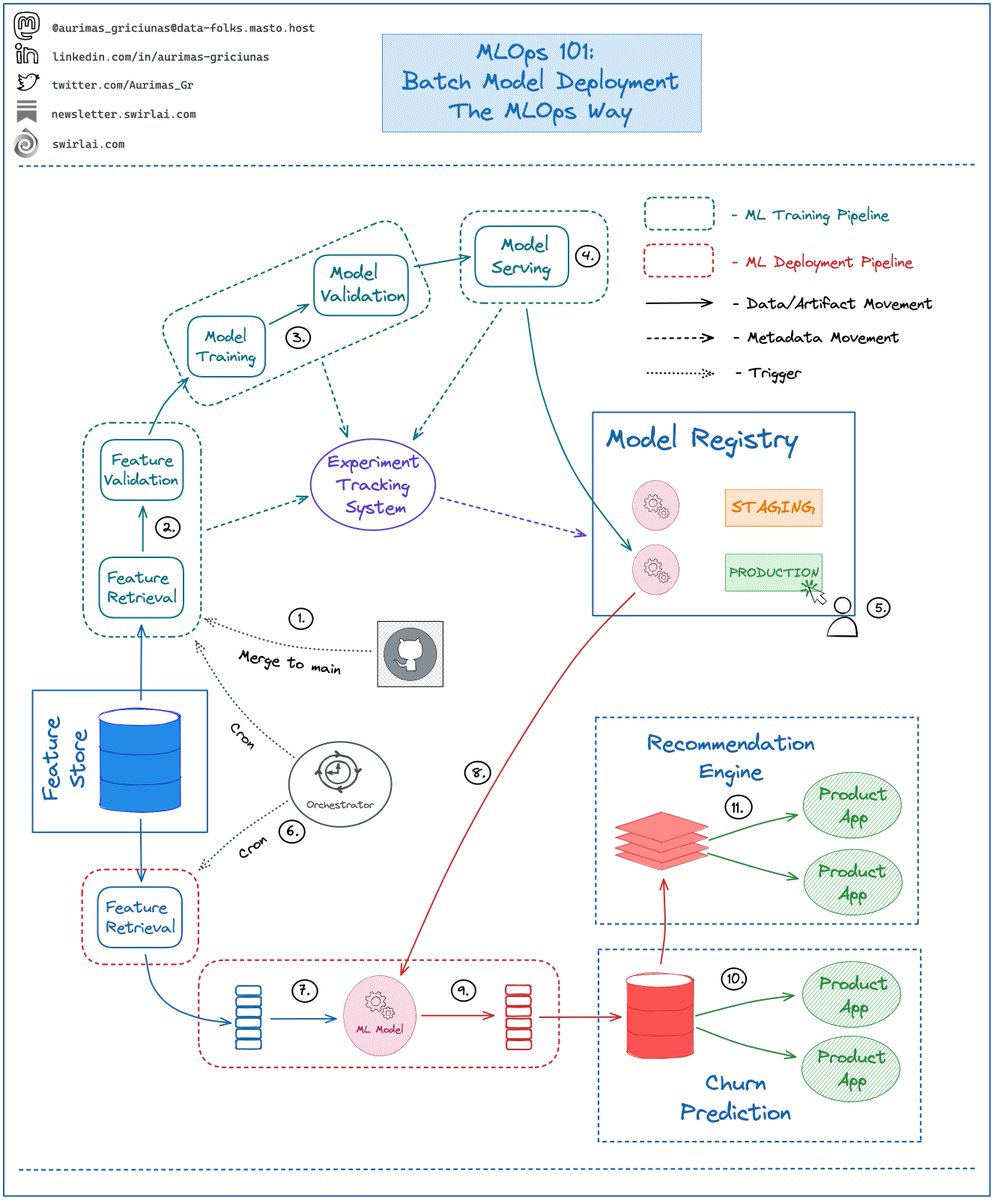 Let’s zoom in:
Let’s zoom in: Usually, what is cared about by the users of your Machine Learning Service is the total endpoint latency - the time difference between when a request is performed (1.) against the Service till when the response is received (6.).
Usually, what is cared about by the users of your Machine Learning Service is the total endpoint latency - the time difference between when a request is performed (1.) against the Service till when the response is received (6.). 𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 is an extremely popular distributed processing framework utilizing in-memory processing to speed up task execution. Most of its libraries are contained in the Spark Core layer.
𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 is an extremely popular distributed processing framework utilizing in-memory processing to speed up task execution. Most of its libraries are contained in the Spark Core layer.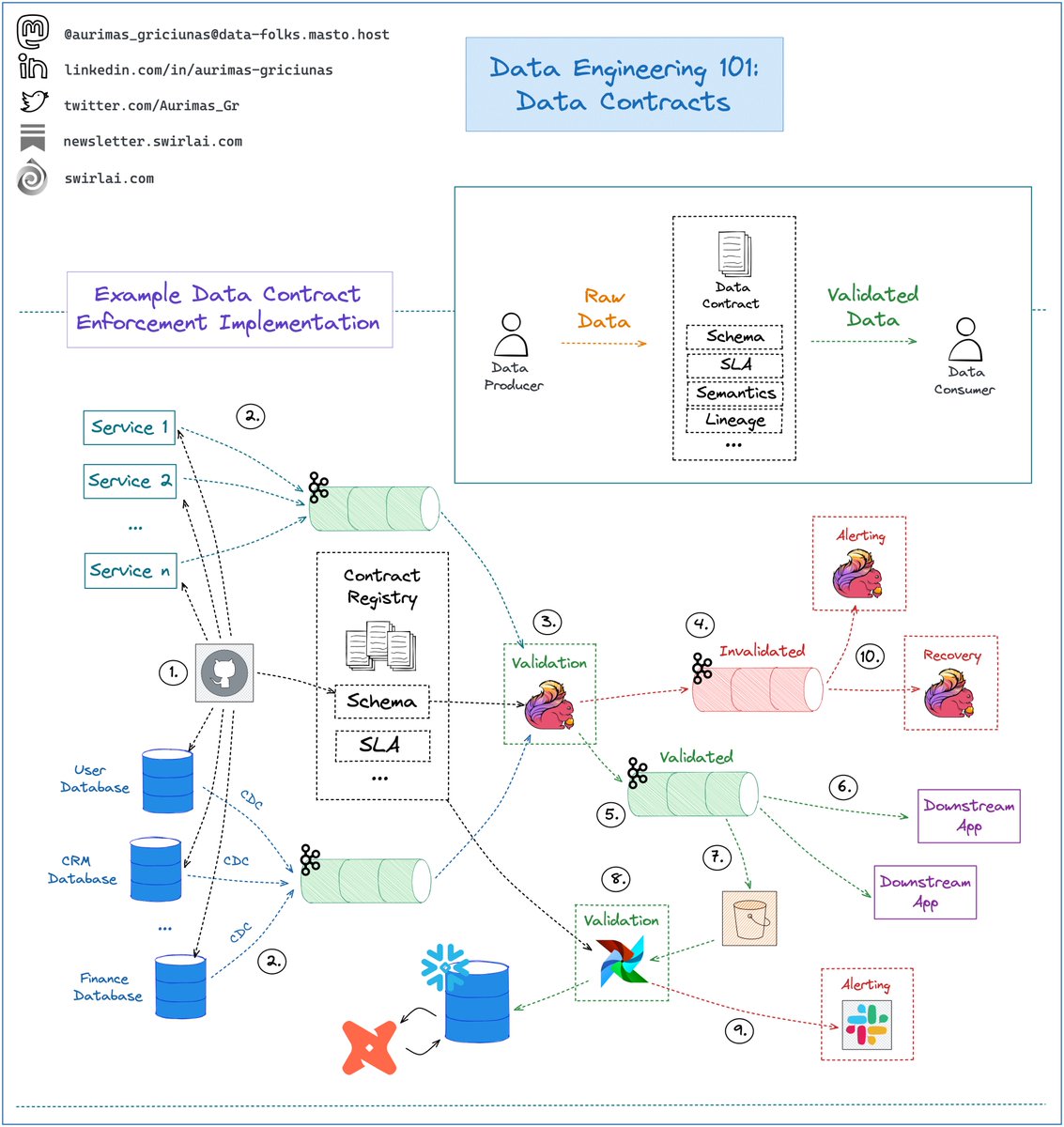 In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it. Recommender and Search Systems are one of the biggest money makers for most companies when it comes to Machine Learning.
Recommender and Search Systems are one of the biggest money makers for most companies when it comes to Machine Learning. It could be that you are taking ACID Properties for granted when you are using transactional databases.
It could be that you are taking ACID Properties for granted when you are using transactional databases. Today - let’s review it once more. It is super helpful as these kind of Data Architectures are what you will find in real life situations.
Today - let’s review it once more. It is super helpful as these kind of Data Architectures are what you will find in real life situations. Lambda and Kappa are both Data architectures proposed to solve movement of large amounts of data for reliable Online access.
Lambda and Kappa are both Data architectures proposed to solve movement of large amounts of data for reliable Online access. You will find this type of model deployment to be the most popular when it comes to Online Machine Learning Systems.
You will find this type of model deployment to be the most popular when it comes to Online Machine Learning Systems. 1️⃣ ”𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴” - A book that I wish I had 5 years ago. After reading it you will understand the entire Data Engineering workflow. It will prepare you for further deep dives.
1️⃣ ”𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴” - A book that I wish I had 5 years ago. After reading it you will understand the entire Data Engineering workflow. It will prepare you for further deep dives.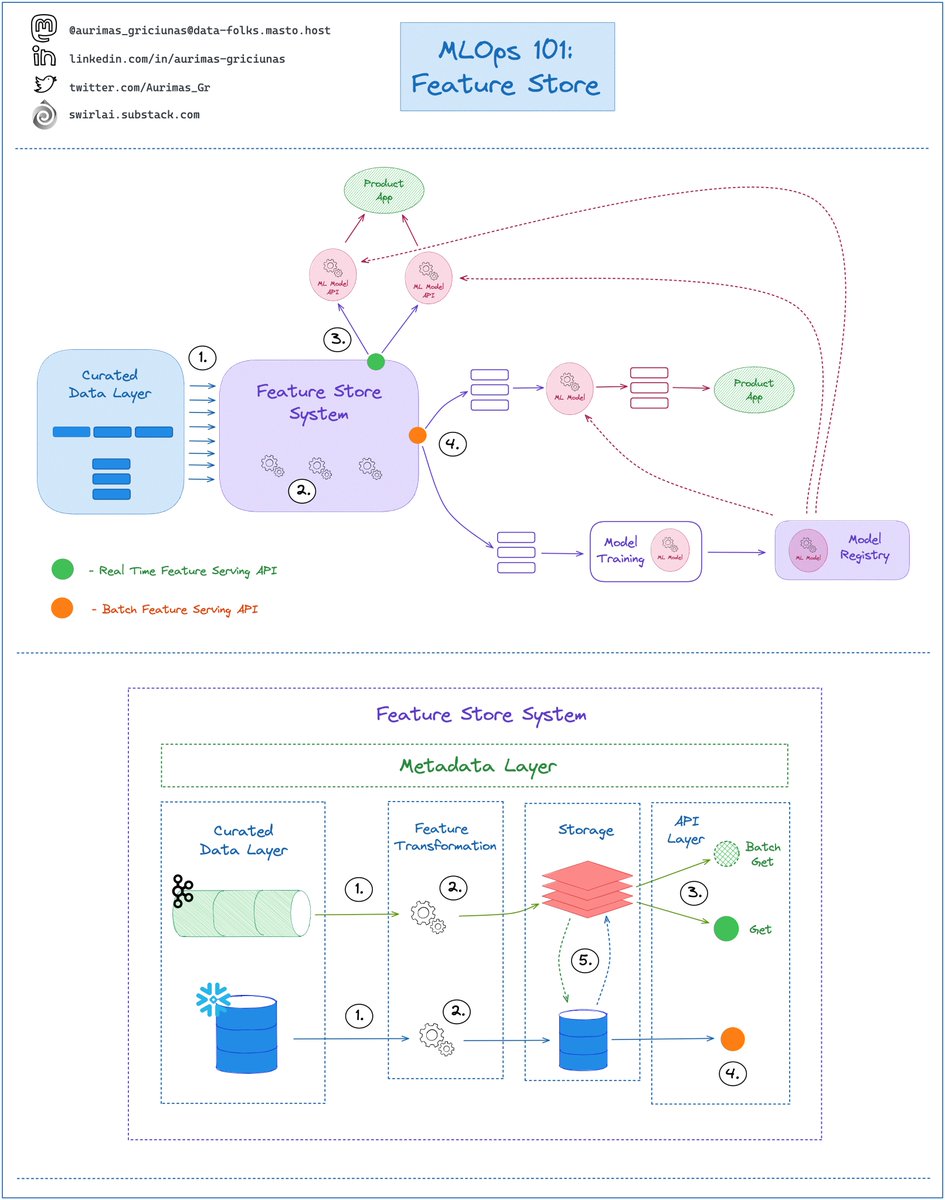 Feature Store System sits between Data Engineering and Machine Learning Pipelines and it solves the following issues:
Feature Store System sits between Data Engineering and Machine Learning Pipelines and it solves the following issues: 𝗖𝗵𝗮𝗻𝗴𝗲 𝗗𝗮𝘁𝗮 𝗖𝗮𝗽𝘁𝘂𝗿𝗲 is a software process used to replicate actions performed against Operational Databases for use in downstream applications.
𝗖𝗵𝗮𝗻𝗴𝗲 𝗗𝗮𝘁𝗮 𝗖𝗮𝗽𝘁𝘂𝗿𝗲 is a software process used to replicate actions performed against Operational Databases for use in downstream applications.  It should be composed of two integrated parts: Experiment Tracking System and a Model Registry.
It should be composed of two integrated parts: Experiment Tracking System and a Model Registry.