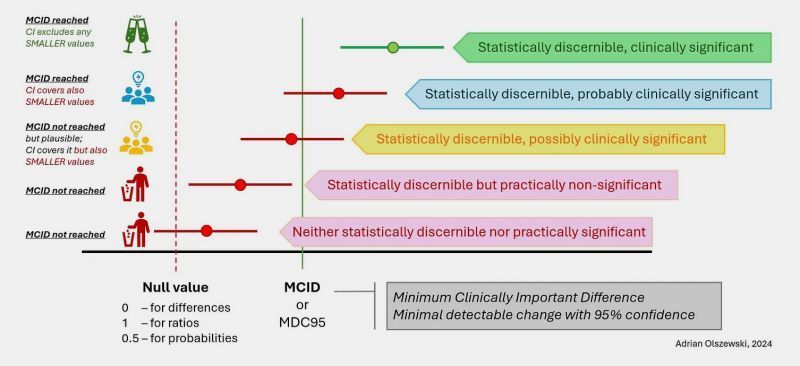
🤯¡Los datos ausentes están por todas partes!😜
👉Pueden invalidar los resultados de tu estudio
👉Muchas funciones utilizan métodos automáticos que pueden no ser óptimos
👉El impacto de la falta de datos es un tema que la mayoría quiere evitar, pero hoy no
¿Qué hacer con los NA?:
👉Pueden invalidar los resultados de tu estudio
👉Muchas funciones utilizan métodos automáticos que pueden no ser óptimos
👉El impacto de la falta de datos es un tema que la mayoría quiere evitar, pero hoy no
¿Qué hacer con los NA?:
🎯Necesitas identificar los datos ausentes, averiguar por qué y cómo faltan:
- errores humanos
- interrupciones del flujo de datos (e.g. meses)
- problemas de privacidad
- sesgo (e.g. tipos de participantes del estudio que tienen >NA)
¡Es info clave para intentar solucionarlo!
- errores humanos
- interrupciones del flujo de datos (e.g. meses)
- problemas de privacidad
- sesgo (e.g. tipos de participantes del estudio que tienen >NA)
¡Es info clave para intentar solucionarlo!
Explora los datos con los paquetes:
✅ visdat github.com/ropensci/visdat
✅ naniar naniar.njtierney.com
✅ VIM github.com/statistikat/VIM
Un ejemplo con los 3: mtor.sci.yorku.ca/MATH4330/files…
✅ visdat github.com/ropensci/visdat
✅ naniar naniar.njtierney.com
✅ VIM github.com/statistikat/VIM
Un ejemplo con los 3: mtor.sci.yorku.ca/MATH4330/files…

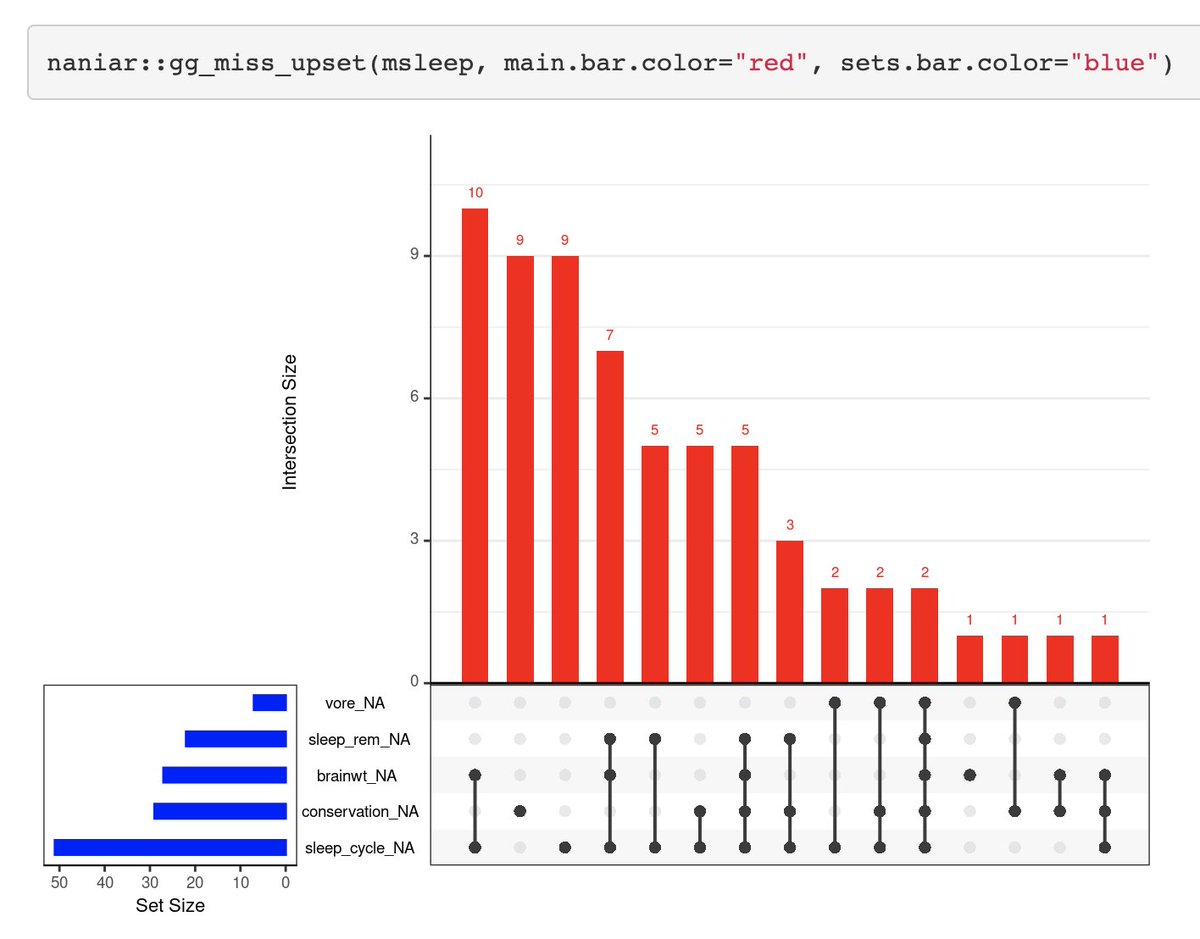


😱¿Qué se hacer con los NA?
👉Si no puedes obtener el registro original, si <10-20% de los datos y si faltan completamente al azar, puedes sustituirlos/imputar por otros valores
🤦🏻♀️Existen muchos métodos y no hay garantía de que produzcan los mismos resultados
👇Te dejo mi resumen
👉Si no puedes obtener el registro original, si <10-20% de los datos y si faltan completamente al azar, puedes sustituirlos/imputar por otros valores
🤦🏻♀️Existen muchos métodos y no hay garantía de que produzcan los mismos resultados
👇Te dejo mi resumen

1️⃣ Eliminación/exclusión de datos faltantes
👉Es útil SOLO si las ausencias son al azar y la subsiguiente reducción del tamaño de la muestra no afecta seriamente la potencia de las pruebas estadísticas.
(Imagen de ReNom)
👉Es útil SOLO si las ausencias son al azar y la subsiguiente reducción del tamaño de la muestra no afecta seriamente la potencia de las pruebas estadísticas.
(Imagen de ReNom)

2️⃣ Imputación simple (e.g. sustituir por la media de la variable)
👉No es muy recomendable
Esto puede afectar la forma de la distribución -varianza, covarianza, quantiles, sesgo, kurtosis, etc., atenuar la correlación con el resto de las variables, y más.
repositorio.cepal.org/bitstream/hand…
👉No es muy recomendable
Esto puede afectar la forma de la distribución -varianza, covarianza, quantiles, sesgo, kurtosis, etc., atenuar la correlación con el resto de las variables, y más.
repositorio.cepal.org/bitstream/hand…

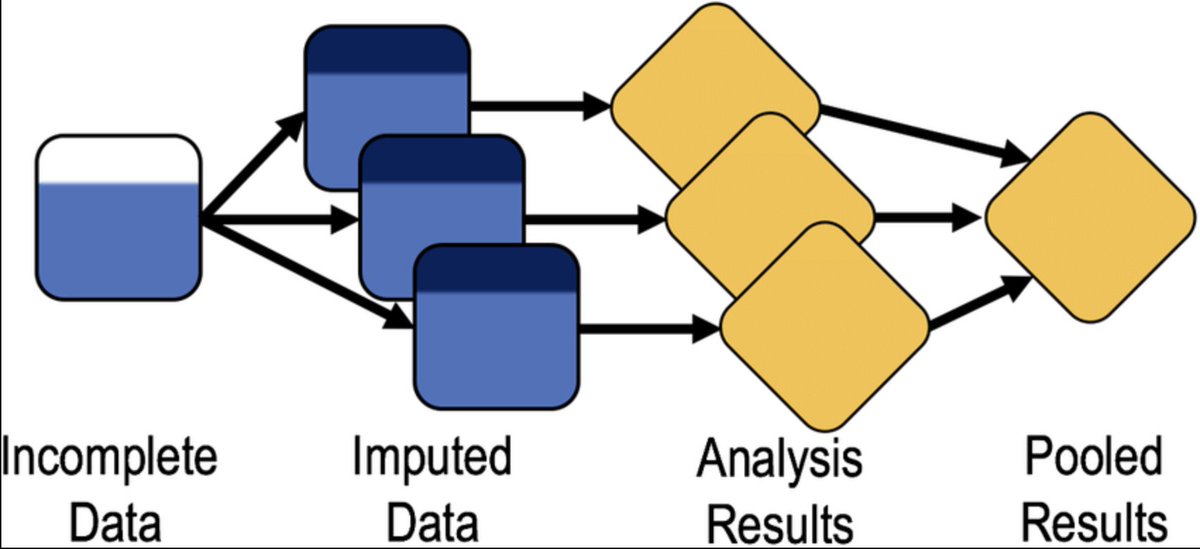
3️⃣ Imputación múltiple
- Supone que los NA ocurren al azar
- Genera valores posibles para los NA creando varios conjuntos de datos "completos"
- Produce resultados para cada uno y resultados combinados
📦mi, Amelia, mice, mitools, missForest o simputation
stat.columbia.edu/~gelman/resear…
- Supone que los NA ocurren al azar
- Genera valores posibles para los NA creando varios conjuntos de datos "completos"
- Produce resultados para cada uno y resultados combinados
📦mi, Amelia, mice, mitools, missForest o simputation
stat.columbia.edu/~gelman/resear…
⚠️RECUERDA
- Identifica los NA
- Comprueba si hay patrones o lagunas en los datos
- Elige el método adecuado
- No elimines ni sustituyas (imputes) los NA a ciegas
- Utilizar un procedimiento inapropiado puede generar más problemas de los que resuelve
#DataScientists #stats #data
- Identifica los NA
- Comprueba si hay patrones o lagunas en los datos
- Elige el método adecuado
- No elimines ni sustituyas (imputes) los NA a ciegas
- Utilizar un procedimiento inapropiado puede generar más problemas de los que resuelve
#DataScientists #stats #data
😉Sígueme para obtener más herramientas y recursos de #DataScience #ML #IA #RStats y aprende las mejores técnicas y enfoques.
Y si te resultó útil, ¡Comparte este hilo! 🤩
Y si te resultó útil, ¡Comparte este hilo! 🤩
https://twitter.com/RosanaFerrero/status/1618570691288399878?s=20&t=_Vi7cYiNfDz2a7wpC2C3dg
• • •
Missing some Tweet in this thread? You can try to
force a refresh