Let’s remind ourselves of how a 𝗥𝗲𝗾𝘂𝗲𝘀𝘁-𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗠𝗼𝗱𝗲𝗹 𝗗𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 looks like - 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆.
🧵
#MLOps #MachineLearning #DataScience #Data
🧵
#MLOps #MachineLearning #DataScience #Data

You will find this type of model deployment to be the most popular when it comes to Online Machine Learning Systems.
Let's zoom in:
𝟭: Version Control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
Let's zoom in:
𝟭: Version Control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
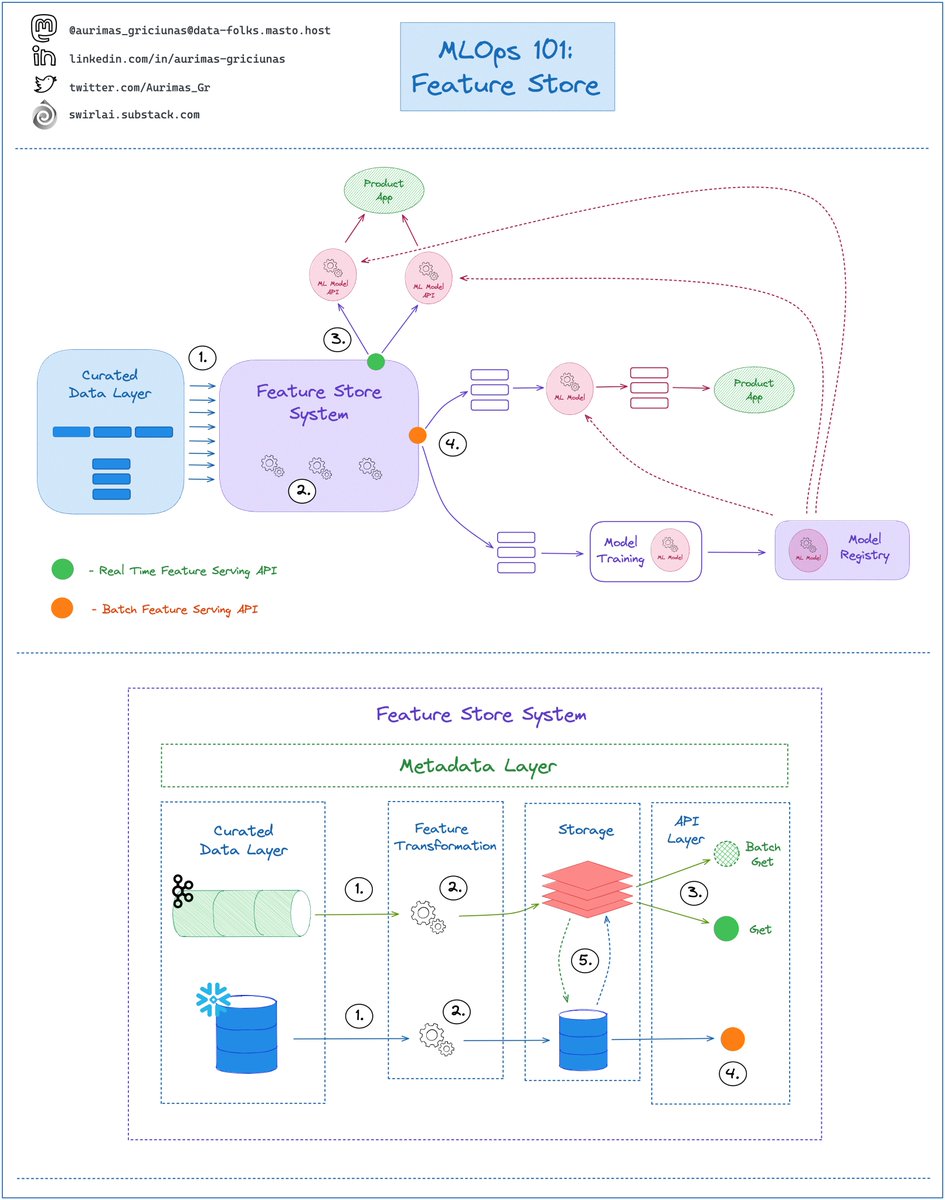
𝟮: Feature Preprocessing: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata that is tightly coupled to the Model being trained is saved to the Experiment Tracking System.
👇
👇
𝟯: Model is trained and validated on Preprocessed Data, Model related metadata is saved to the Experiment Tracking System.
👇
👇
𝟰.𝟭: If Model Validation passes all checks - Model Artifact is passed to a Model Registry.
𝟰.𝟮: Model is packaged into a container ready to be exposed as REST or gRPC API. Model is Served for deployment.
👇
𝟰.𝟮: Model is packaged into a container ready to be exposed as REST or gRPC API. Model is Served for deployment.
👇
𝟱.𝟭: Experiment Tracking metadata is connected to Model Registry per Model Artifact. Responsible person chooses the best candidate and switches its state to Production.
👇
👇
𝟱.𝟮: A web-hook is triggered by the action and a Deployment Pipeline is launched that deploys the new version of containerised API. There are different release strategies that we covered in one of the previous posts.
👇
👇
𝟲: A Request from a Product Application is performed against the API - Features for inference are retrieved from Real Time Feature Serving API and inference results are returned to the Application.
𝟳: ML APIs are faced with a Load Balancer to enable horizontal scaling.
👇
𝟳: ML APIs are faced with a Load Balancer to enable horizontal scaling.
👇
𝟴: Multiple ML APIs will be exposed in this way to support different Product Applications. A good example is a Ranking Function.
𝟵: Feature Store will be mounted on top of a Data Warehouse to retrieve Static Features or
👇
𝟵: Feature Store will be mounted on top of a Data Warehouse to retrieve Static Features or
👇
𝟵.𝟭: Some of the Features will be Dynamic and calculated in Real Time from a Distributed Messaging System like Kafka.
👇
👇
𝟭𝟬: An orchestrator schedules Model Retraining.
𝟭𝟭: ML Models that run in production are monitored. If Model quality degrades - retraining can be automatically triggered.
👇
𝟭𝟭: ML Models that run in production are monitored. If Model quality degrades - retraining can be automatically triggered.
👇
[𝗜𝗠𝗣𝗢𝗥𝗧𝗔𝗡𝗧]: The Defined Flow assumes that your Pipelines are already Tested and ready to be released to Production. We’ll look into the pre-production flow in future episodes.
𝗣𝗿𝗼𝘀 𝗮𝗻𝗱 𝗖𝗼𝗻𝘀:
✅ Dynamic Features - available.
✅ Low Latency Inference.
👇
𝗣𝗿𝗼𝘀 𝗮𝗻𝗱 𝗖𝗼𝗻𝘀:
✅ Dynamic Features - available.
✅ Low Latency Inference.
👇
❗️Inference results will be recalculated even if the input or result did not change (unless additional caching mechanism are implemented).
And remember - 𝗧𝗵𝗶𝘀 𝗶𝘀 𝗧𝗵𝗲 𝗪𝗮𝘆.
👇
And remember - 𝗧𝗵𝗶𝘀 𝗶𝘀 𝗧𝗵𝗲 𝗪𝗮𝘆.
👇
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 5000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: swirlai.substack.com/p/sai-15-whats…
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 5000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: swirlai.substack.com/p/sai-15-whats…
• • •
Missing some Tweet in this thread? You can try to
force a refresh