
Really impressed by the acting you can generate with @elevenlabsio #texttospeech! These are #AIvoices generated from text—dozens of "takes" stitched together. Breakdown thread: 1/8 #syntheticvoices #ainarration #autonarrated #aicinema #aiartcommunity #aiia #ai #MachineLearning
I started by having #chatGPT write a few rough drafts of a scene involving a panicked character calling her friend for help from a spaceship. I was going for something that would involve heightened emotions but not be too serious. 2/8 

Then I wrote a short script using some of those ideas plus my own and put the whole thing into @elevenlabsio. I generated a few takes using low Stability (1-2%) and high Clarity (90-99%). Each take usually had parts I liked, or at least gave me ideas for direction. 3/8

I stuck to one voice I liked for simplicity. Changing voices can sometimes dramatically alter the sound to where it almost feels like diff mics were used. I decided I'd just change the pitch of the voices in post to differentiate them more. 4/8
After doing a few takes of the whole script, I generated individual lines. There I'd experiment with the "prompt" to see if I could direct the acting more by adding ellipses, diff punctuation, line breaks, and misspellings. Here's a sample of my history. 5/8

Then I laid everything out in #premierepro. I cut up the audio into sections with different takes and methodically edited down to my favorites, trying to choose parts that blended well together. 6/8
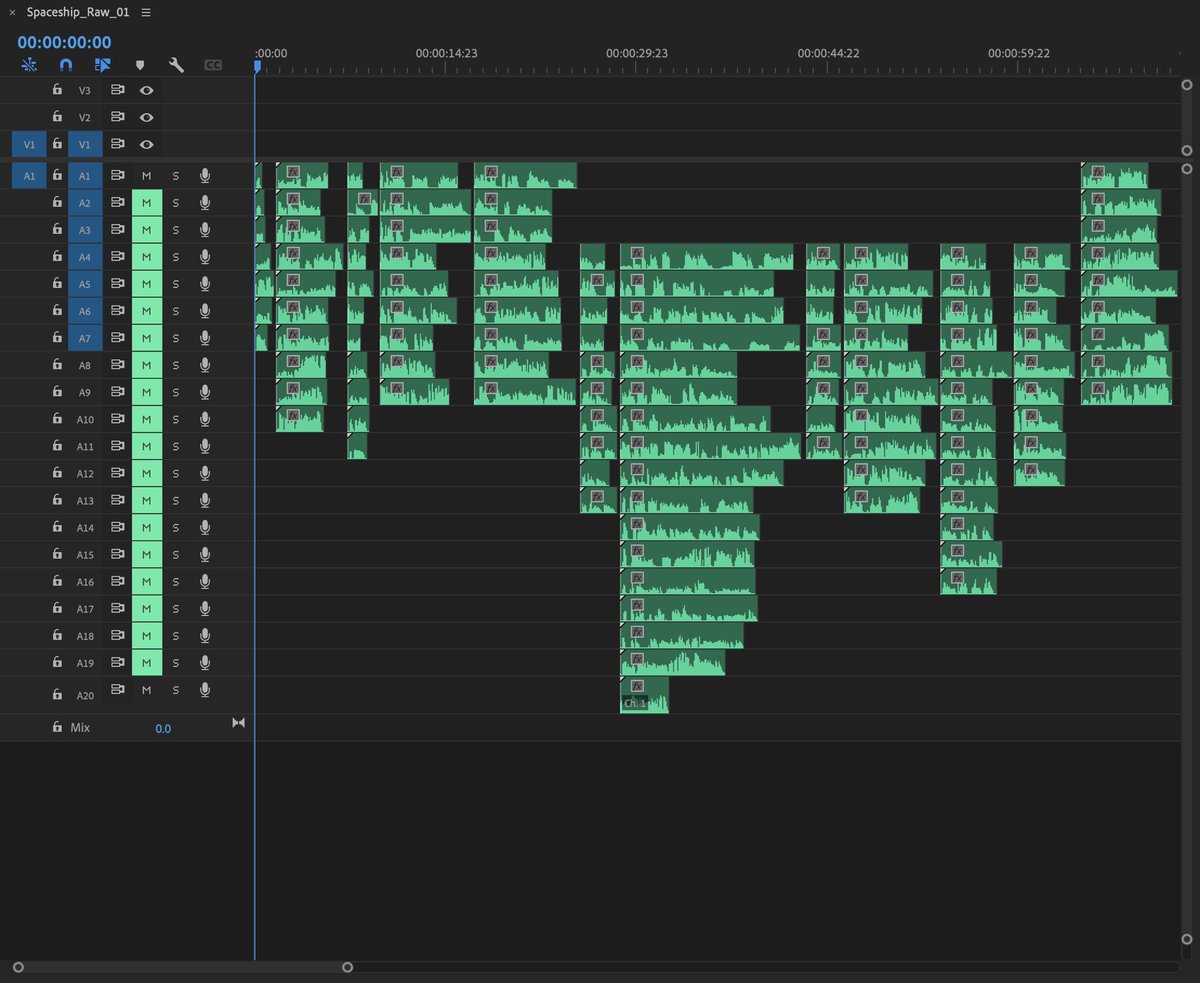
When parts wouldn't blend well together, I'd just rewrite the lines and generate a few more takes in @elevenlabsio. It's almost like instantaneous ADR. Then I used #adobeaudition for shifting the pitch in the voices and adding reverb. 7/8
Last step was using the script as rolling credits and put it on an image I made in #midjourney. I added the audio wave in After Effects. 8/8
• • •
Missing some Tweet in this thread? You can try to
force a refresh









