
A refresher on the role of 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 in the Data Pipeline.
Read on in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Read on in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
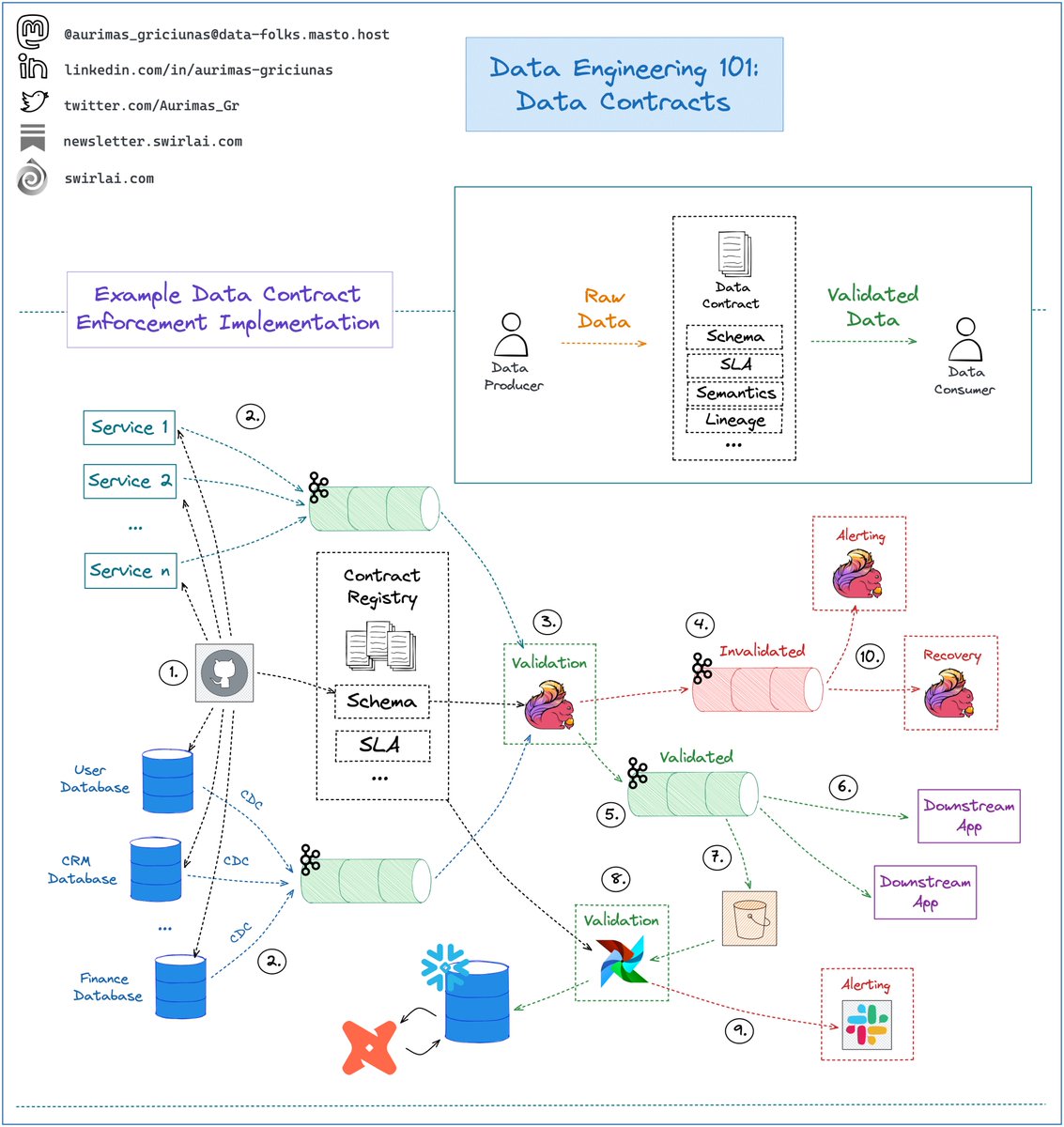
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
👇
👇
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 𝗵𝗼𝗹𝗱 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝗻𝗼𝗻-𝗲𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗹𝗶𝘀𝘁 𝗼𝗳 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮:
👉 Schema of the Data being Produced.
👇
👉 Schema of the Data being Produced.
👇
👉 Shema Version - Data Sources evolve, Producers have to ensure that it is possible to detect and react to schema changes. Consumers should be able to process Data with the old Schema.
👇
👇
👉 SLA metadata - Quality: is it meant for Production use? How late can the data arrive? How many missing values could be expected for certain fields in a given time period?
👇
👇
👉 Semantics - what entity does a given Data Point represent. Semantics, similar to schema, can evolve over time.
👉 Lineage - Data Owners, Intended Consumers.
👉 …
👇
👉 Lineage - Data Owners, Intended Consumers.
👉 …
👇
𝗦𝗼𝗺𝗲 𝗣𝘂𝗿𝗽𝗼𝘀𝗲𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
👇
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
👇
➡️ Improve scalability of your Data Systems.
➡️ Reduce intermediate Data Handover Layer.
➡️ …
Example implementation for Data Contract Enforcement:
👇
➡️ Reduce intermediate Data Handover Layer.
➡️ …
Example implementation for Data Contract Enforcement:
👇
1️⃣ Schema changes are implemented in a git repository, once approved - they are pushed to the Applications generating the Data and a central Schema Registry.
2️⃣ Applications push generated Data to Kafka Topics. Separate Raw Data Topics for CDC streams and Direct emission.
👇
2️⃣ Applications push generated Data to Kafka Topics. Separate Raw Data Topics for CDC streams and Direct emission.
👇
3️⃣ A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Schema Registry.
4️⃣ Data that does not meet the contract is pushed to Dead Letter Topic.
👇
4️⃣ Data that does not meet the contract is pushed to Dead Letter Topic.
👇
5️⃣ Data that meets the contract is pushed to Validated Data Topic.
6️⃣ Applications that need Real Time Data consume it directly from Validated Data Topic or its derivatives.
7️⃣ Data from the Validated Data Topic is pushed to object storage for additional Validation.
👇
6️⃣ Applications that need Real Time Data consume it directly from Validated Data Topic or its derivatives.
7️⃣ Data from the Validated Data Topic is pushed to object storage for additional Validation.
👇
8️⃣ On a schedule Data in the Object Storage is validated against additional SLAs and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
9️⃣ Consumers and Producers are alerted to any SLA breaches.
👇
9️⃣ Consumers and Producers are alerted to any SLA breaches.
👇
🔟 Data that was Invalidated in Real Time is consumed by Flink Applications that alert on invalid schemas. There could be a recovery Flink Application with logic on how to fix invalidated Data.
👇
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-15-whats…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-15-whats…
• • •
Missing some Tweet in this thread? You can try to
force a refresh









