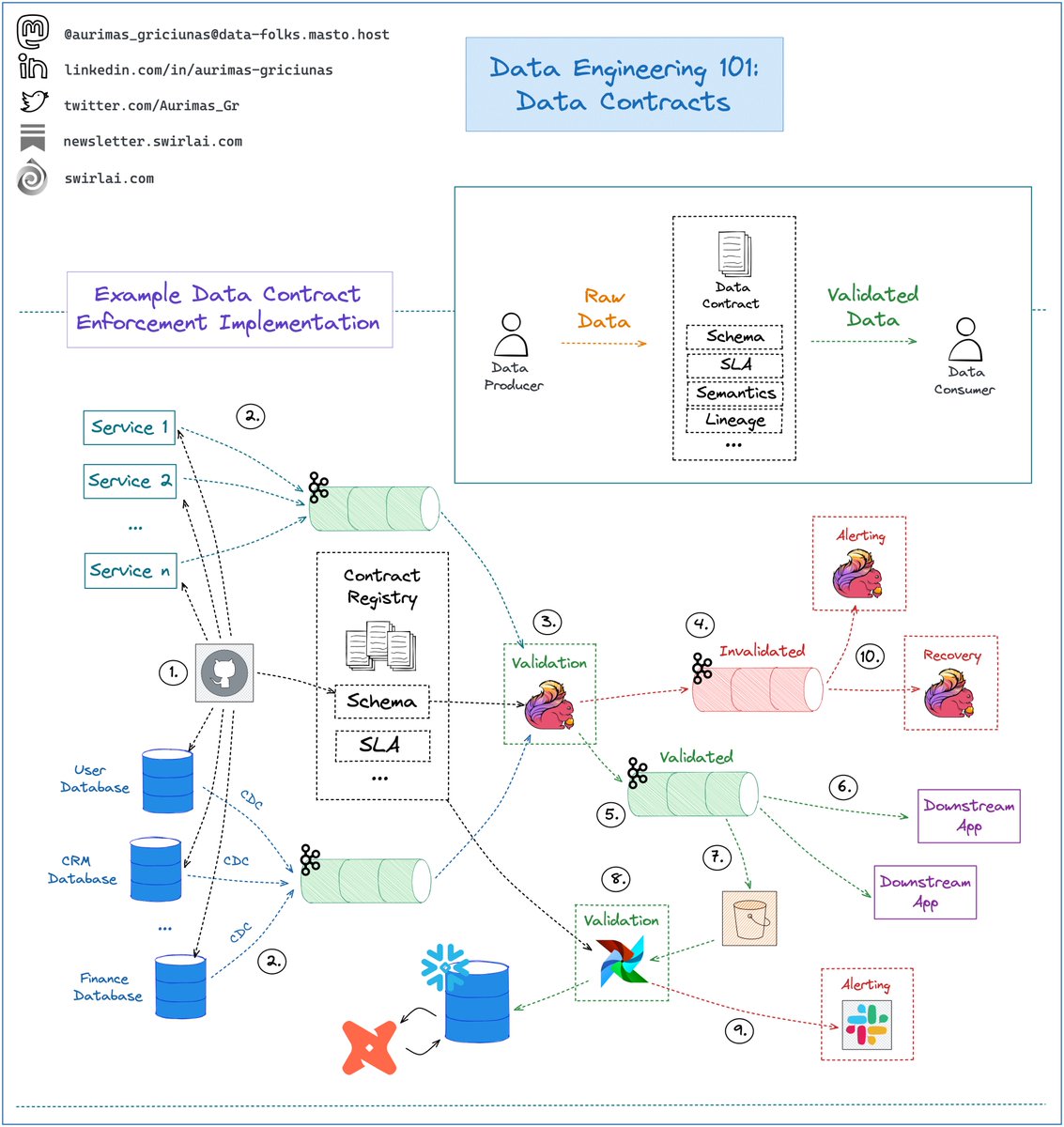
Do you know how 𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 𝗶𝘀 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝗲𝗱?
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 is an extremely popular distributed processing framework utilizing in-memory processing to speed up task execution. Most of its libraries are contained in the Spark Core layer.
👇
👇
As a warm up exercise for later deeper dives and tips, today we focus on some architecture basics.
𝗦𝗽𝗮𝗿𝗸 𝗵𝗮𝘀 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝗵𝗶𝗴𝗵 𝗹𝗲𝘃𝗲𝗹 𝗔𝗣𝗜𝘀 𝗯𝘂𝗶𝗹𝘁 𝗼𝗻 𝘁𝗼𝗽 𝗼𝗳 𝗦𝗽𝗮𝗿𝗸 𝗖𝗼𝗿𝗲 𝘁𝗼 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀:
👇
𝗦𝗽𝗮𝗿𝗸 𝗵𝗮𝘀 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝗵𝗶𝗴𝗵 𝗹𝗲𝘃𝗲𝗹 𝗔𝗣𝗜𝘀 𝗯𝘂𝗶𝗹𝘁 𝗼𝗻 𝘁𝗼𝗽 𝗼𝗳 𝗦𝗽𝗮𝗿𝗸 𝗖𝗼𝗿𝗲 𝘁𝗼 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀:
👇
➡️ 𝗦𝗽𝗮𝗿𝗸𝗦𝗤𝗟 - Batch Processing.
➡️ 𝗦𝗽𝗮𝗿𝗸 𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 - Near to Real-Time Processing.
➡️ 𝗦𝗽𝗮𝗿𝗸 𝗠𝗟𝗹𝗶𝗯 - Machine Learning.
➡️ 𝗚𝗿𝗮𝗽𝗵𝗫 - Graph Structures and Algorithms.
👇
➡️ 𝗦𝗽𝗮𝗿𝗸 𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 - Near to Real-Time Processing.
➡️ 𝗦𝗽𝗮𝗿𝗸 𝗠𝗟𝗹𝗶𝗯 - Machine Learning.
➡️ 𝗚𝗿𝗮𝗽𝗵𝗫 - Graph Structures and Algorithms.
👇
𝗦𝘂𝗽𝗽𝗼𝗿𝘁𝗲𝗱 𝗽𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲𝘀:
➡️ Scala
➡️ Java
➡️ Python
➡️ R
👇
➡️ Scala
➡️ Java
➡️ Python
➡️ R
👇
𝗚𝗲𝗻𝗲𝗿𝗮𝗹 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲:
1️⃣ Once you submit a 𝗦𝗽𝗮𝗿𝗸 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻 - 𝗦𝗽𝗮𝗿𝗸𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗢𝗯𝗷𝗲𝗰𝘁 is created in the 𝗗𝗿𝗶𝘃𝗲𝗿 𝗣𝗿𝗼𝗴𝗿𝗮𝗺. This Object is responsible for communicating with the 𝗖𝗹𝘂𝘀𝘁𝗲𝗿 𝗠𝗮𝗻𝗮𝗴𝗲𝗿.
👇
1️⃣ Once you submit a 𝗦𝗽𝗮𝗿𝗸 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻 - 𝗦𝗽𝗮𝗿𝗸𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗢𝗯𝗷𝗲𝗰𝘁 is created in the 𝗗𝗿𝗶𝘃𝗲𝗿 𝗣𝗿𝗼𝗴𝗿𝗮𝗺. This Object is responsible for communicating with the 𝗖𝗹𝘂𝘀𝘁𝗲𝗿 𝗠𝗮𝗻𝗮𝗴𝗲𝗿.
👇
2️⃣ 𝗦𝗽𝗮𝗿𝗸𝗖𝗼𝗻𝘁𝗲𝘅𝘁 negotiates with Cluster Manager for required resources to run 𝗦𝗽𝗮𝗿𝗸 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻. 𝗖𝗹𝘂𝘀𝘁𝗲𝗿 𝗠𝗮𝗻𝗮𝗴𝗲𝗿 allocates the resources inside of a respective Cluster and creates a requested number of 𝗦𝗽𝗮𝗿𝗸 𝗘𝘅𝗲𝗰𝘂𝘁𝗼𝗿𝘀.
👇
👇
3️⃣ After starting - Spark Executors will connect with 𝗦𝗽𝗮𝗿𝗸𝗖𝗼𝗻𝘁𝗲𝘅𝘁 to notify about joining the Cluster. 𝗘𝘅𝗲𝗰𝘂𝘁𝗼𝗿𝘀 will be sending heartbeats regularly to notify the 𝗗𝗿𝗶𝘃𝗲𝗿 𝗣𝗿𝗼𝗴𝗿𝗮𝗺 that they are healthy and don’t need rescheduling.
👇
👇
4️⃣ 𝗦𝗽𝗮𝗿𝗸 𝗘𝘅𝗲𝗰𝘂𝘁𝗼𝗿𝘀 are responsible for executing tasks of the 𝗖𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻 𝗗𝗔𝗚 (𝗗𝗶𝗿𝗲𝗰𝘁𝗲𝗱 𝗔𝗰𝘆𝗰𝗹𝗶𝗰 𝗚𝗿𝗮𝗽𝗵). This could include reading, writing data or performing a certain operation on a partition of RDDs.
👇
👇
𝗦𝘂𝗽𝗽𝗼𝗿𝘁𝗲𝗱 𝗖𝗹𝘂𝘀𝘁𝗲𝗿 𝗠𝗮𝗻𝗮𝗴𝗲𝗿𝘀:
➡️ 𝗦𝘁𝗮𝗻𝗱𝗮𝗹𝗼𝗻𝗲 - simple cluster manager shipped together with Spark.
➡️ 𝗛𝗮𝗱𝗼𝗼𝗽 𝗬𝗔𝗥𝗡 - resource manager of Hadoop ecosystem.
👇
➡️ 𝗦𝘁𝗮𝗻𝗱𝗮𝗹𝗼𝗻𝗲 - simple cluster manager shipped together with Spark.
➡️ 𝗛𝗮𝗱𝗼𝗼𝗽 𝗬𝗔𝗥𝗡 - resource manager of Hadoop ecosystem.
👇
➡️ 𝗔𝗽𝗮𝗰𝗵𝗲 𝗠𝗲𝘀𝗼𝘀 - general cluster manager (❗️ deprecated).
➡️ 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀 - popular open-source container orchestrator.
𝗦𝗽𝗮𝗿𝗸 𝗝𝗼𝗯 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹𝘀:
👇
➡️ 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀 - popular open-source container orchestrator.
𝗦𝗽𝗮𝗿𝗸 𝗝𝗼𝗯 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹𝘀:
👇
👉 𝗦𝗽𝗮𝗿𝗸 𝗗𝗿𝗶𝘃𝗲𝗿 is responsible for constructing an optimized physical execution plan for a given application submitted for execution.
👉 This plan materializes into a Job which is a 𝗗𝗔𝗚 𝗼𝗳 𝗦𝘁𝗮𝗴𝗲𝘀.
👇
👉 This plan materializes into a Job which is a 𝗗𝗔𝗚 𝗼𝗳 𝗦𝘁𝗮𝗴𝗲𝘀.
👇
👉 Some of the 𝗦𝘁𝗮𝗴𝗲𝘀 can be executed in parallel if they have no sequential dependencies.
👉 Each 𝗦𝘁𝗮𝗴𝗲 is composed of 𝗧𝗮𝘀𝗸𝘀.
👇
👉 Each 𝗦𝘁𝗮𝗴𝗲 is composed of 𝗧𝗮𝘀𝗸𝘀.
👇
👉 All 𝗧𝗮𝘀𝗸𝘀 of a single 𝗦𝘁𝗮𝗴𝗲 contain the same type of work which is the smallest piece of work that can be executed in parallel and is performed by 𝗦𝗽𝗮𝗿𝗸 𝗘𝘅𝗲𝗰𝘂𝘁𝗼𝗿𝘀.
👇
👇
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-03-machi…
• • •
Missing some Tweet in this thread? You can try to
force a refresh