How do we 𝗗𝗲𝗰𝗼𝗺𝗽𝗼𝘀𝗲 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝗲𝗿𝘃𝗶𝗰𝗲 𝗟𝗮𝘁𝗲𝗻𝗰𝘆 and why should you care to understand the pieces as a ML Engineer?
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

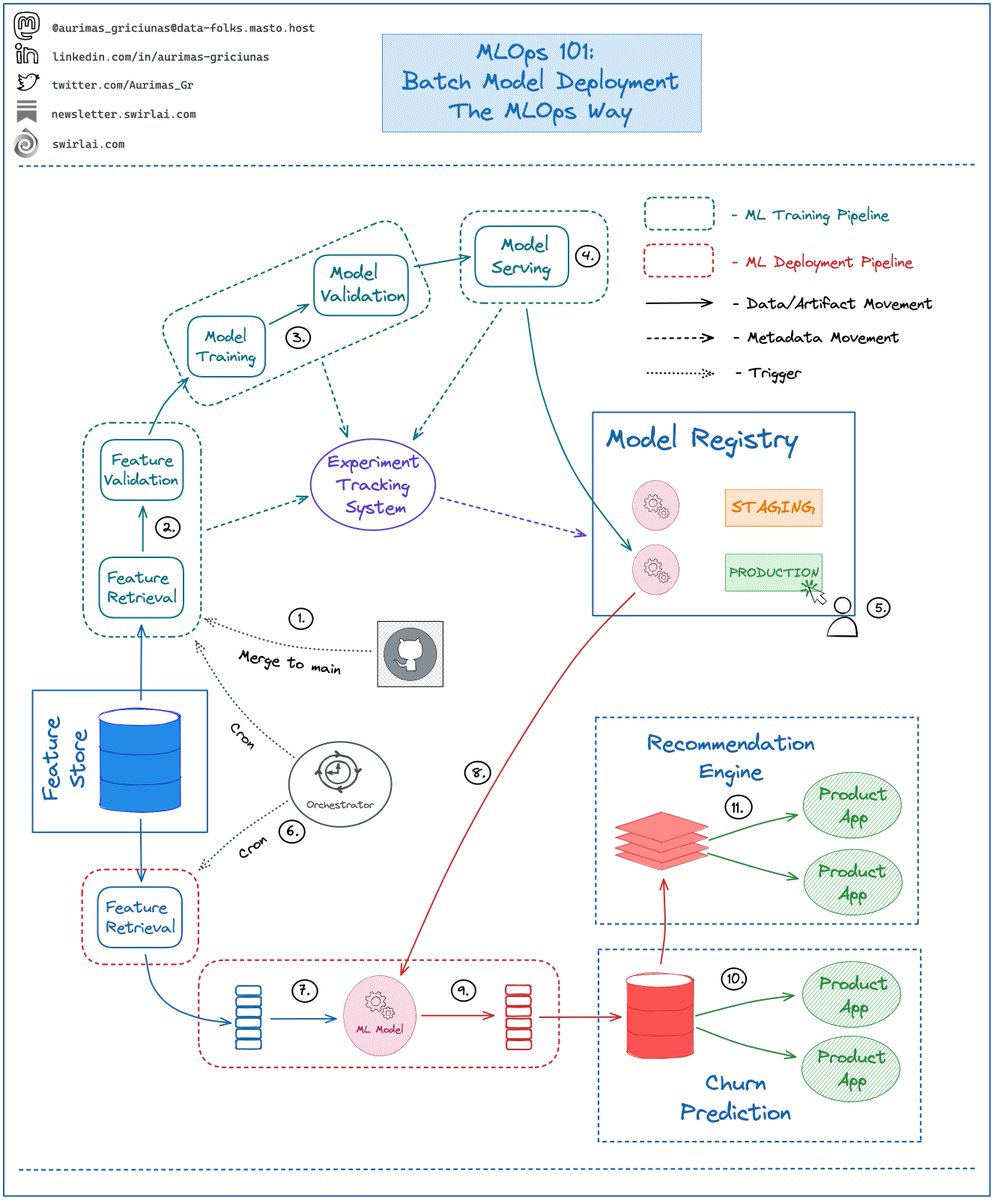
Usually, what is cared about by the users of your Machine Learning Service is the total endpoint latency - the time difference between when a request is performed (1.) against the Service till when the response is received (6.).
👇
👇
Certain SLAs will be established on what the acceptable latency is and you will need to reach that. Being able to decompose the total latency is even more important as you can improve each piece independently. Let's see how.
👇
👇
Total latency of typical Machine Learning Service will be comprised of:
𝟮: Feature Lookup.
You can decrease the latency here by:
𝘼: Changing the Storage Technology to better fit the type of data you are looking up and the queries you are running against the Store.
👇
𝟮: Feature Lookup.
You can decrease the latency here by:
𝘼: Changing the Storage Technology to better fit the type of data you are looking up and the queries you are running against the Store.
👇
𝘽: Implementing aggressive caching strategy that would allow you to contain the data of most frequently queries locally. You could spin up local Online Feature Stores if the data held in them are not too big (however, management and syncing of these becomes troublesome).
👇
👇
𝟯: 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗣𝗿𝗲𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴.
Decrease latency here by:
👇
Decrease latency here by:
👇
𝘼: If possible, moving preprocessing logic before the data is pushed to the Feature Store. This allows for calculation logic to be performed once instead of doing it each time before Inference. Combine this with improvements in point 2 for largest latency improvement.
👇
👇
𝟰: 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲.
Decrease latency here by:
𝘼: Reducing the Model Size using techniques like Pruning, Knowledge Distillation or Quantisation (more on these in future posts).
👇
Decrease latency here by:
𝘼: Reducing the Model Size using techniques like Pruning, Knowledge Distillation or Quantisation (more on these in future posts).
👇
𝘽: If your service consists of multiple models - applying inference in parallel and combining the results instead of chaining them in sequence if possible.
👇
👇
These three building blocks are what is specific to a ML System, there are naturally components like Network latency and machine resources that we need to take into consideration.
👇
👇
Network Latency could be improved by pulling ML Model into the backend service.
When it comes to Machine Resources - it is important to consider horizontal scaling strategies and how large your servers have to be to efficiently host the model type that you are using.
👇
When it comes to Machine Resources - it is important to consider horizontal scaling strategies and how large your servers have to be to efficiently host the model type that you are using.
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
Finally, I would be really grateful if You could Retweet my content to your audience so that it can reach more people. Thank you! 🙏
https://twitter.com/Aurimas_Gr/status/1630165714886709248
• • •
Missing some Tweet in this thread? You can try to
force a refresh