So how do we implement 𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗚𝗿𝗮𝗱𝗲 𝗕𝗮𝘁𝗰𝗵 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 in 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Let’s zoom in:
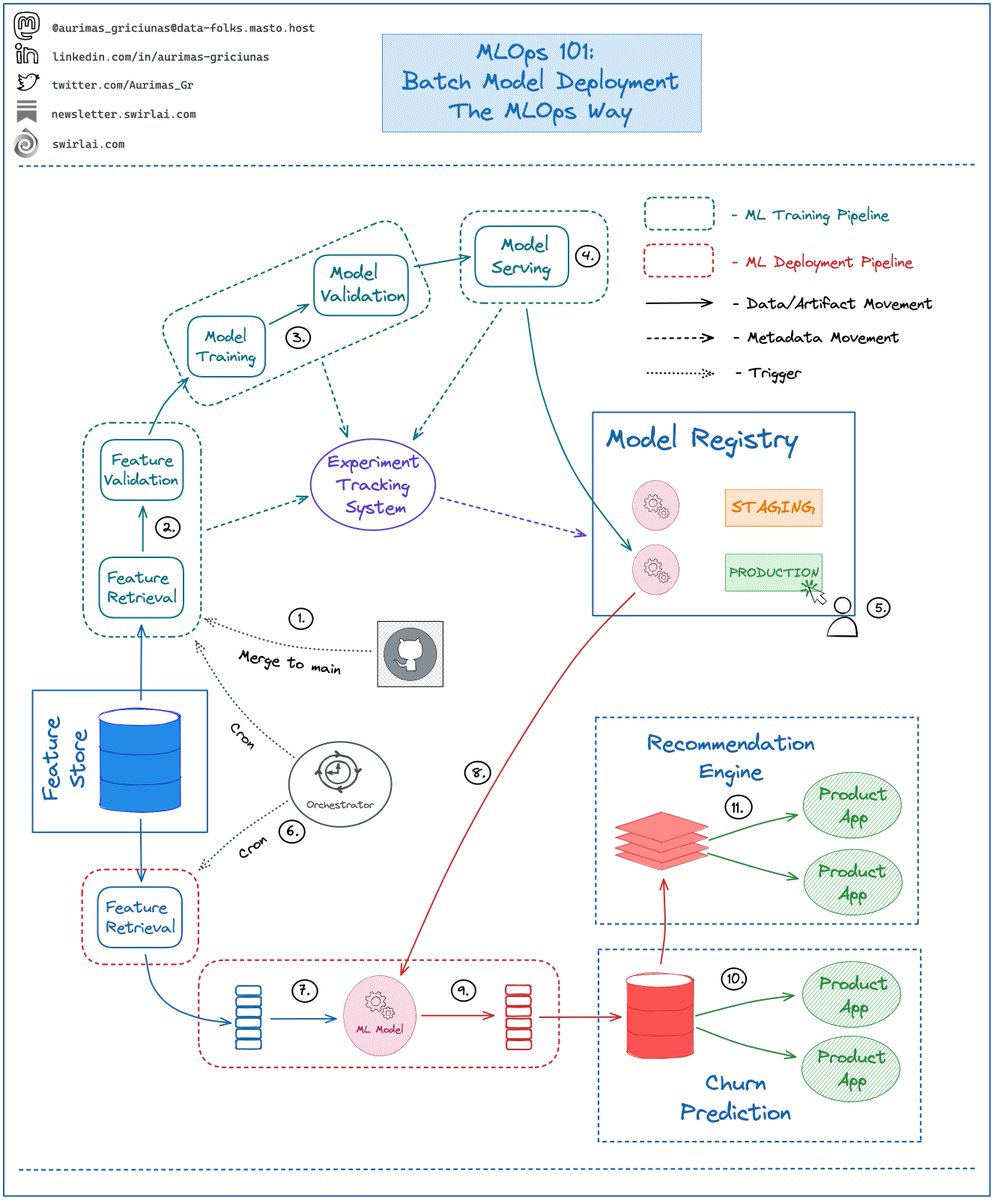
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟮: Feature preprocessing stage: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata is saved to an Experiment Tracking System.
👇
👇
𝟯: Model is trained and validated on Preprocessed Data, any Model related metadata is saved to an Experiment Tracking System.
𝟰: If Model Validation passes all checks - Model Artifact is passed to a Model Registry.
👇
𝟰: If Model Validation passes all checks - Model Artifact is passed to a Model Registry.
👇
𝟱: Experiment Tracking metadata is connected to Model Registry per Model Artifact. Responsible person chooses the best candidate and switches its state to Production. ML Training Pipeline ends here, the Model is served.
👇
👇
𝟲: On a schedule or on demand an orchestrator triggers ML Deployment Pipeline.
𝟳: Feature Data that wasn’t used for inference yet is retrieved from the Feature Store.
𝟴: Model version that is marked as Production ready is pulled from the Model Registry.
👇
𝟳: Feature Data that wasn’t used for inference yet is retrieved from the Feature Store.
𝟴: Model version that is marked as Production ready is pulled from the Model Registry.
👇
𝟵: Model Inference is applied on previously retrieved Feature Set.
𝟭𝟬: Inference results are loaded into an offline Batch Storage.
👇
𝟭𝟬: Inference results are loaded into an offline Batch Storage.
👇
👉 Inference results can be used directly from Batch Storage for some use cases. A good example is Churn Prediction - you extract users that are highly likely to churn and send promotional emails to them.
👇
👇
𝟭𝟭: If Product Application requires Real Time Data Access we load inference scores to a Low Latency Read Capable Storage like Redis and source from it.
👇
👇
👉 A good example is Recommender Systems - you extract scores for products to be recommended and use them to choose what to recommend.
👇
👇
𝗣𝗿𝗼𝘀 𝗮𝗻𝗱 𝗖𝗼𝗻𝘀:
✅ Easy to implement Flow.
❗️Inference is performed with delay.
❗️If new customers start using your product there will be no predictions for the stale data points until Deployment Pipeline is run again.
👇
✅ Easy to implement Flow.
❗️Inference is performed with delay.
❗️If new customers start using your product there will be no predictions for the stale data points until Deployment Pipeline is run again.
👇
❗️Fallback strategies will be required for new customers.
❗️Dynamic Features are not available.
This is The Way.
👇
❗️Dynamic Features are not available.
This is The Way.
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
• • •
Missing some Tweet in this thread? You can try to
force a refresh