What is the difference between Splittable and Non-Splittable Files?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

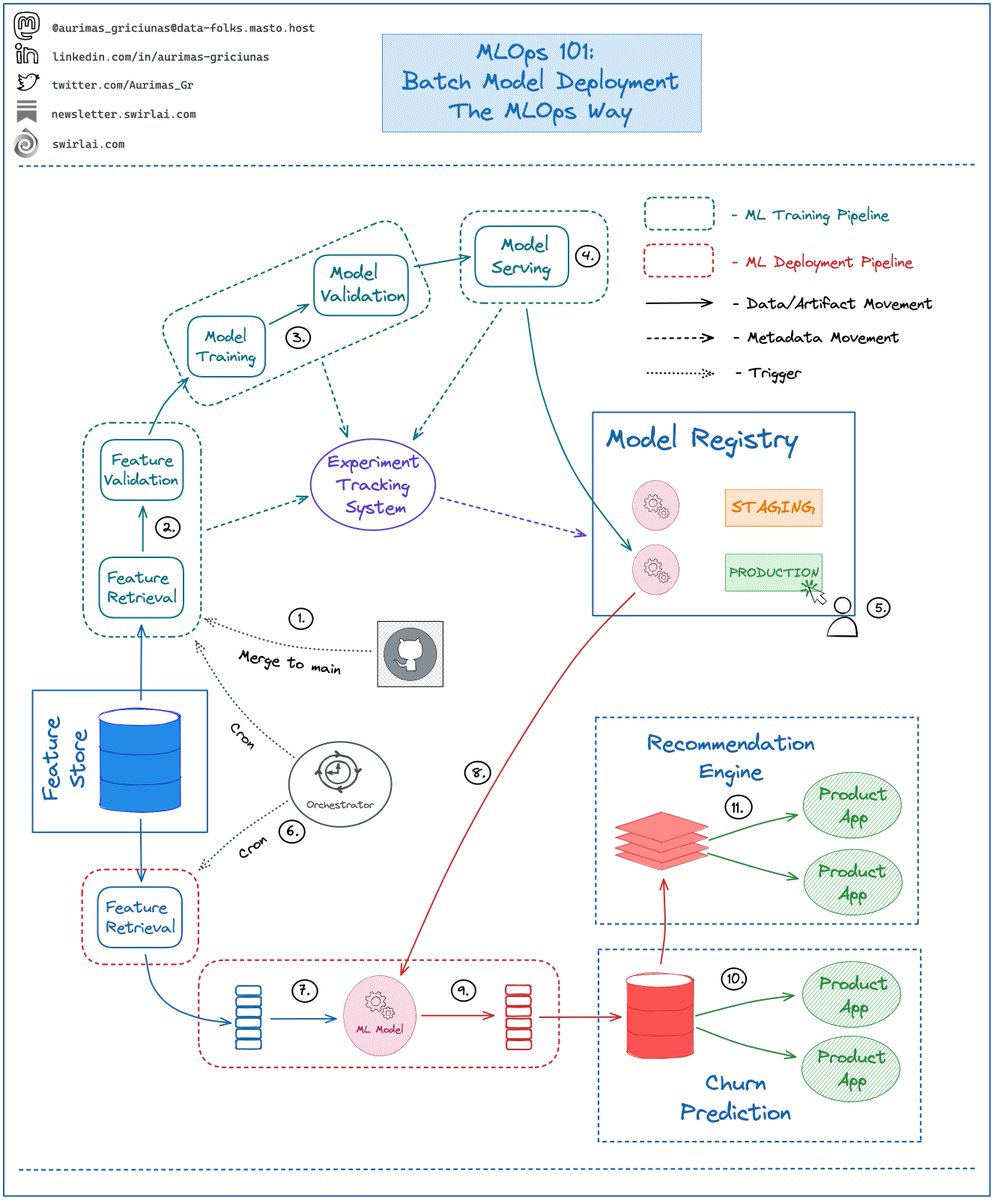
You are very likely to run into a 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗼𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 in your career. It could be 𝗦𝗽𝗮𝗿𝗸, 𝗛𝗶𝘃𝗲, 𝗣𝗿𝗲𝘀𝘁𝗼 or any other.
👇
👇
Also, it is very likely that these Frameworks would be reading data from a distributed storage. It could be 𝗛𝗗𝗙𝗦, 𝗦𝟯 etc.
👇
👇
These Frameworks utilize multiple 𝗖𝗣𝗨 𝗖𝗼𝗿𝗲𝘀 𝗳𝗼𝗿 𝗟𝗼𝗮𝗱𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 and performing 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 in parallel.
👇
👇
How files are stored in your 𝗦𝘁𝗼𝗿𝗮𝗴𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗶𝘀 𝗞𝗲𝘆 for utilizing distributed 𝗥𝗲𝗮𝗱 𝗮𝗻𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁𝗹𝘆.
𝗦𝗼𝗺𝗲 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
𝗦𝗼𝗺𝗲 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
➡️ 𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 𝗙𝗶𝗹𝗲𝘀 are Files that can be partially read by several processes at the same time.
➡️ In distributed file or block storages files are stored in chunks called blocks.
➡️ Block sizes will vary between different storage systems.
👇
➡️ In distributed file or block storages files are stored in chunks called blocks.
➡️ Block sizes will vary between different storage systems.
👇
𝗧𝗵𝗶𝗻𝗴𝘀 𝘁𝗼 𝗸𝗻𝗼𝘄:
➡️ If your file is 𝗡𝗼𝗻-𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 and is bigger than a block in storage - it will be split between blocks but will only be read by a 𝗦𝗶𝗻𝗴𝗹𝗲 𝗖𝗣𝗨 𝗖𝗼𝗿𝗲 which might cause 𝗜𝗱𝗹𝗲 𝗖𝗣𝗨 time.
👇
➡️ If your file is 𝗡𝗼𝗻-𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 and is bigger than a block in storage - it will be split between blocks but will only be read by a 𝗦𝗶𝗻𝗴𝗹𝗲 𝗖𝗣𝗨 𝗖𝗼𝗿𝗲 which might cause 𝗜𝗱𝗹𝗲 𝗖𝗣𝗨 time.
👇
➡️ If your file is 𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 - multiple cores can read it at the same time (one core per block).
👇
👇
𝗦𝗼𝗺𝗲 𝗴𝘂𝗶𝗱𝗮𝗻𝗰𝗲:
➡️ If possible - prefer 𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 𝗙𝗶𝗹𝗲 types.
➡️ If you are forced to use 𝗡𝗼𝗻-𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 files - manually partition them into sizes that would fit into a single FS Block to utilize more CPU Cores.
👇
➡️ If possible - prefer 𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 𝗙𝗶𝗹𝗲 types.
➡️ If you are forced to use 𝗡𝗼𝗻-𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 files - manually partition them into sizes that would fit into a single FS Block to utilize more CPU Cores.
👇
𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 𝗳𝗶𝗹𝗲 𝗳𝗼𝗿𝗺𝗮𝘁𝘀:
👉 𝗔𝘃𝗿𝗼.
👉 𝗖𝗦𝗩.
👉 𝗢𝗥𝗖.
👉 𝗻𝗱𝗝𝗦𝗢𝗡.
👉 𝗣𝗮𝗿𝗾𝘂𝗲𝘁.
👇
👉 𝗔𝘃𝗿𝗼.
👉 𝗖𝗦𝗩.
👉 𝗢𝗥𝗖.
👉 𝗻𝗱𝗝𝗦𝗢𝗡.
👉 𝗣𝗮𝗿𝗾𝘂𝗲𝘁.
👇
𝗡𝗼𝗻-𝗦𝗽𝗹𝗶𝘁𝘁𝗮𝗯𝗹𝗲 𝗳𝗶𝗹𝗲 𝗳𝗼𝗿𝗺𝗮𝘁𝘀:
👉 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹 𝗕𝘂𝗳𝗳𝗲𝗿𝘀.
👉 𝗝𝗦𝗢𝗡.
👉 𝗫𝗠𝗟.
👇
👉 𝗣𝗿𝗼𝘁𝗼𝗰𝗼𝗹 𝗕𝘂𝗳𝗳𝗲𝗿𝘀.
👉 𝗝𝗦𝗢𝗡.
👉 𝗫𝗠𝗟.
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
• • •
Missing some Tweet in this thread? You can try to
force a refresh