Considering switching to a 𝗠𝗟𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 role?
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

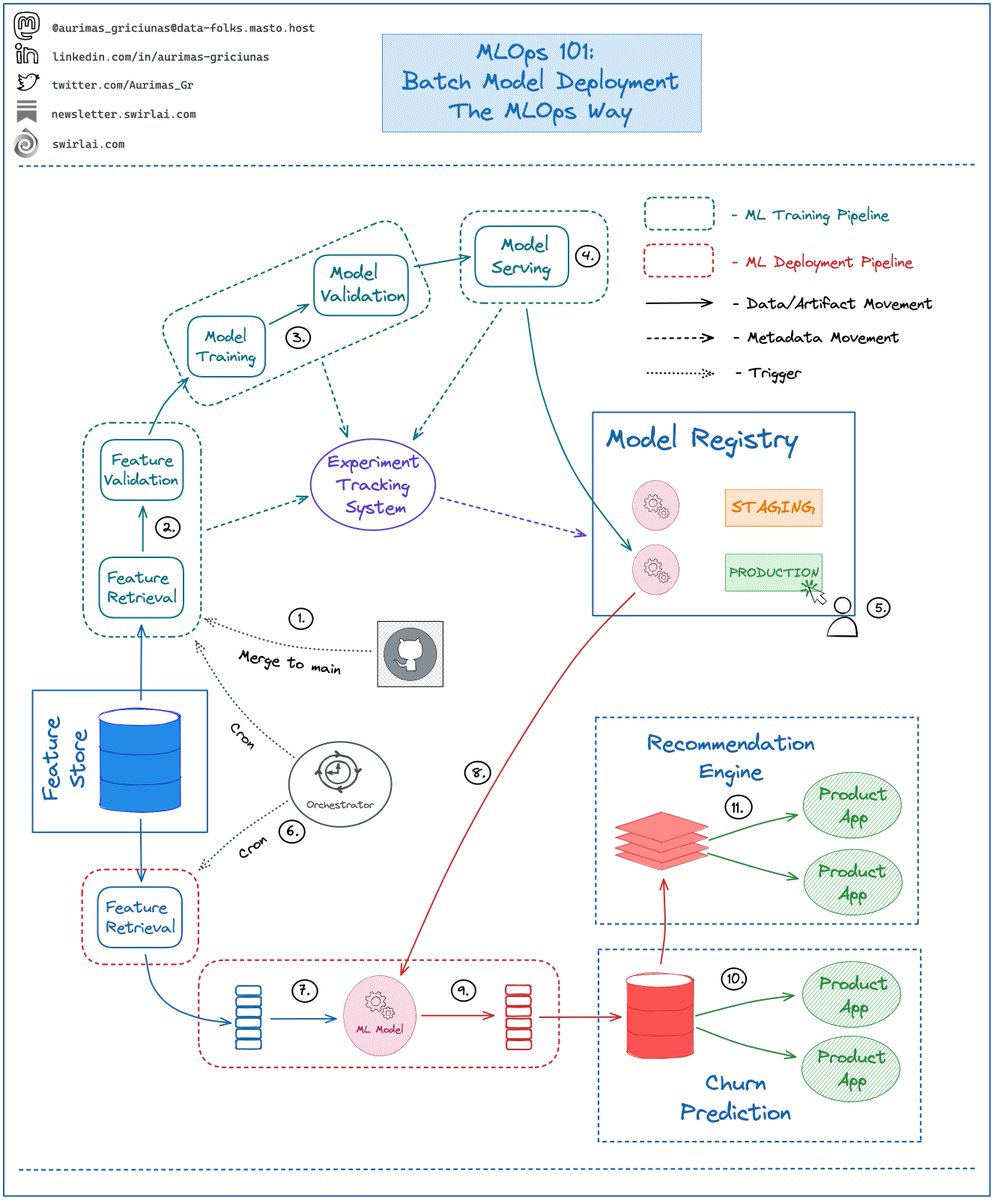
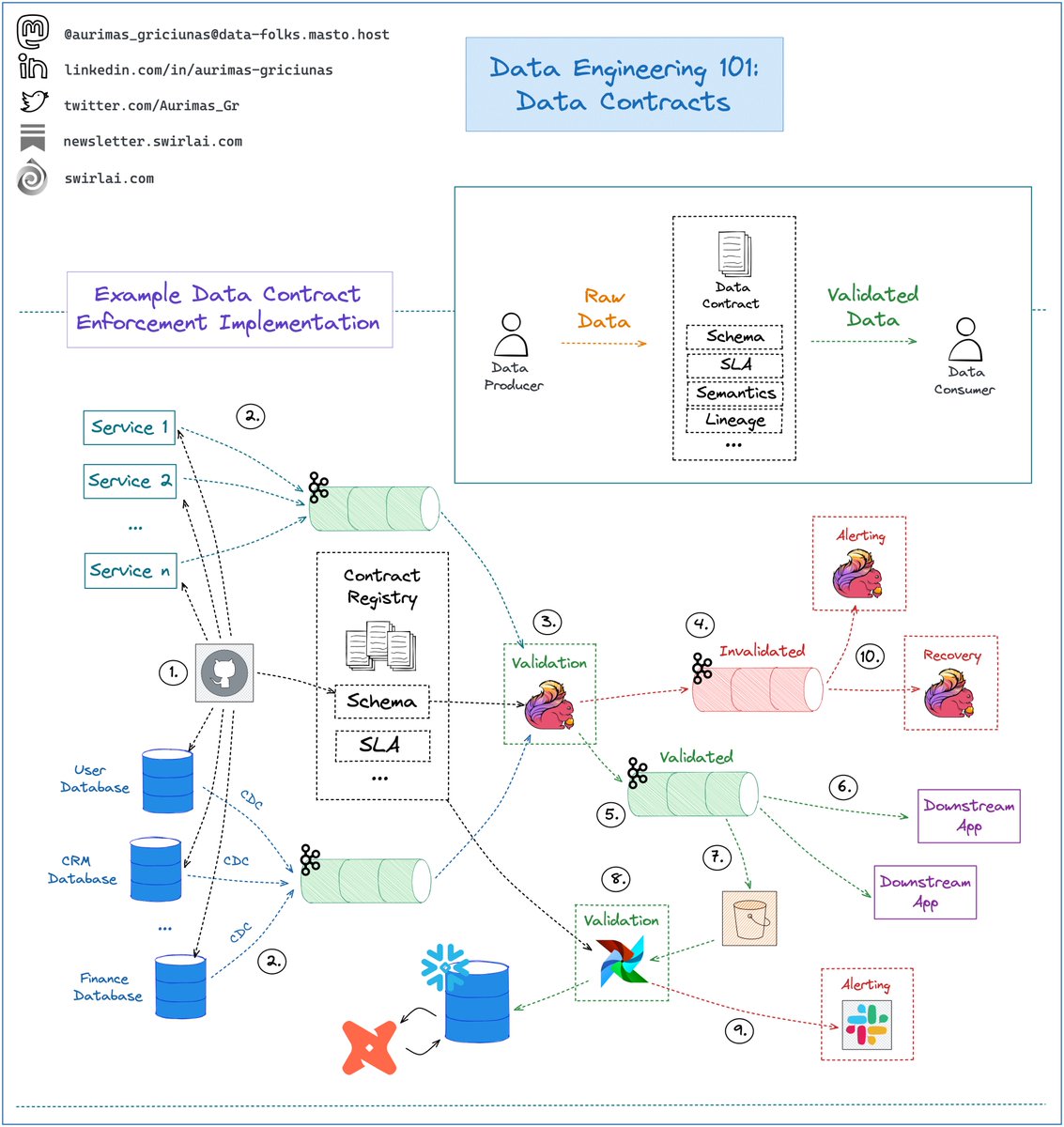
Usually MLOps Engineers are professionals tasked with building out the ML Platform in the organization.
👇
👇
This means that the skill set required is very broad - naturally very few people start off with the full set of skills you would need to brand yourself as a MLOps Engineer. This is why I would not choose this role if you are just entering the market.
👇
👇
However, you can get into the role from various sides once you already have some experience. Here are some examples - If you currently are:
👇
👇
ML Engineer: if you are currently successful in your role you might already have skills that are needed to become a successful MLOps Engineer. What you will need to do though is switch from an execution to a service role. So the main shift is mental rather than technical.
👇
👇
𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲/𝗖𝗹𝗼𝘂𝗱 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿: you are most likely good with infrastructure architecture, IaaC, Cloud Services etc. These are all crucial skills to have in the ML platform team.
👇
👇
𝗗𝗲𝘃𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿: you have probably mastered CI/CD infrastructure and very well know how to template and automate things, how to increase developer velocity - each of these being a necessity to become MLOps engineer.
👇
👇
Software Engineer: areas that software engineering skills could be leveraged in ML platform team: coding up clean interfaces, backend services, UIs to be used by platform adopters. Additionally, you are probably as good with CI/CD infrastructure as most DevOps engineers are.
👇
👇
In any case - be prepared to learn a lot as MLOps Engineers are generalists and it usually takes a lot of time to acquire the full-stack.
👇
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6000+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-19-the-d…
• • •
Missing some Tweet in this thread? You can try to
force a refresh