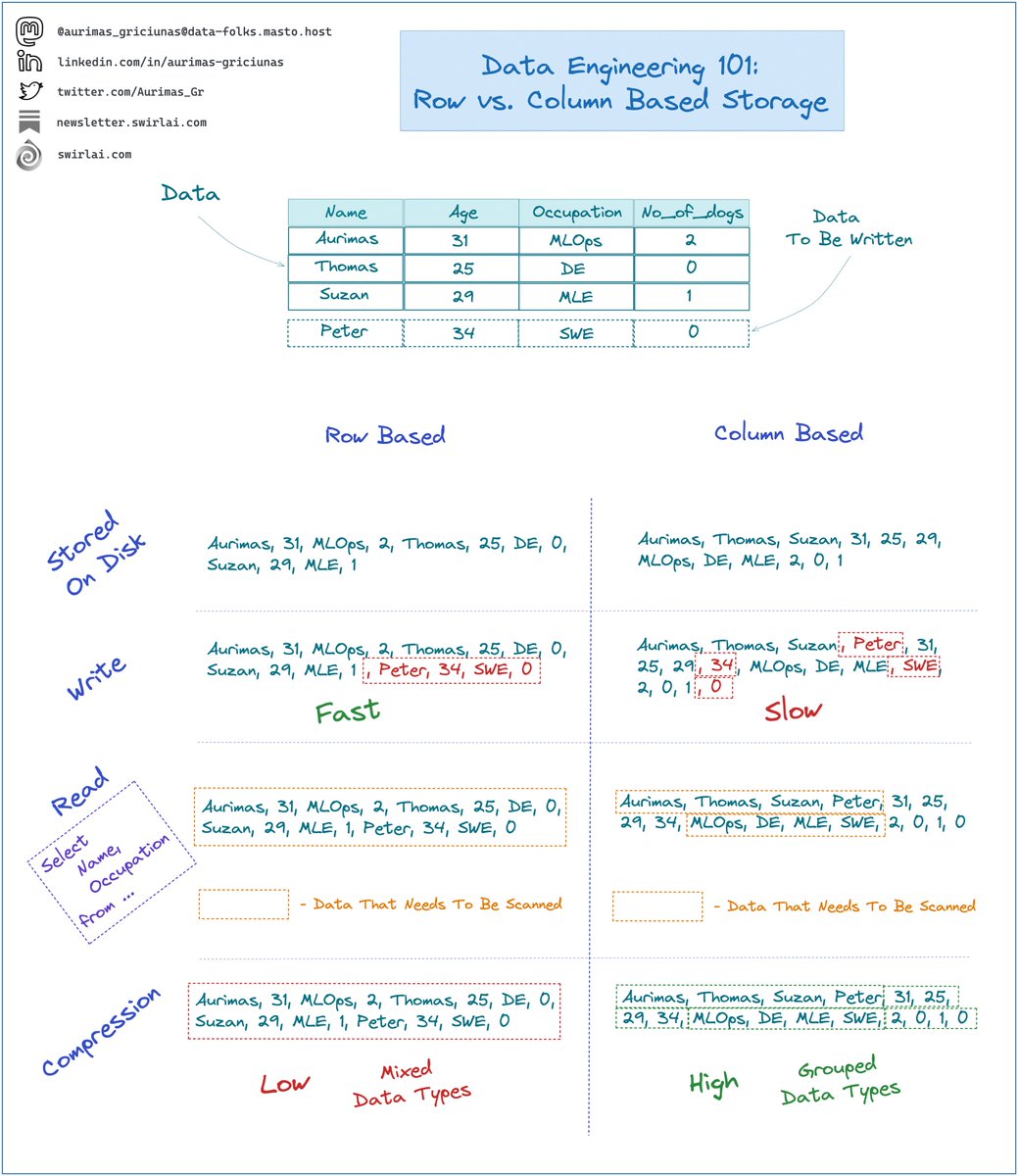
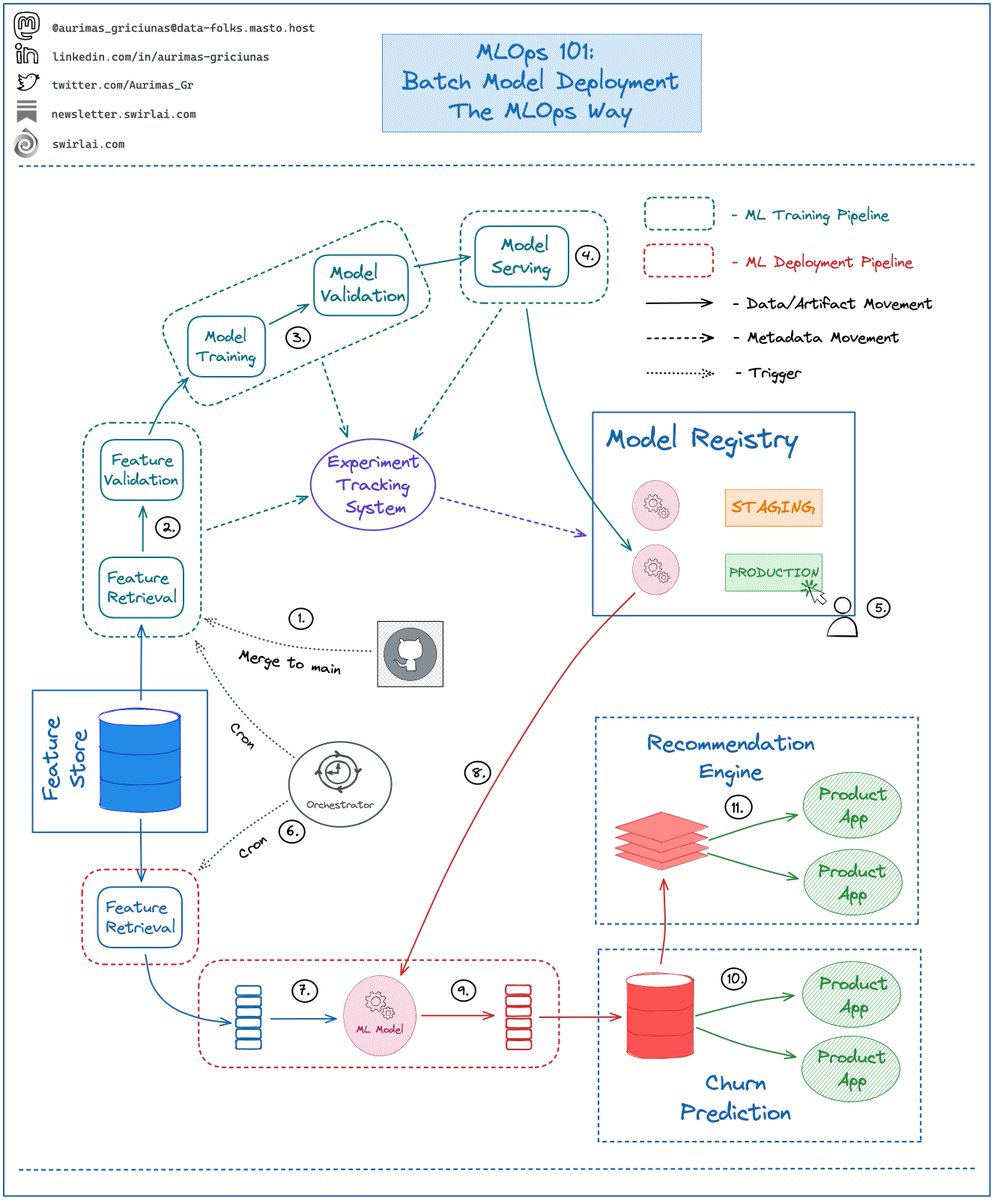
What are the main use cases for Apache Kafka or any other Distributed Messaging System?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer?
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗪𝗲𝗯𝘀𝗶𝘁𝗲 𝗔𝗰𝘁𝗶𝘃𝗶𝘁𝘆 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴.
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇
➡️ These events are forwarded to the downstream Analytical systems or processed in Real Time.
➡️ Kafka is used as an initial buffer as the Data amounts are usually big and Kafka guarantees no message loss due to its replication mechanisms.
👇
➡️ Kafka is used as an initial buffer as the Data amounts are usually big and Kafka guarantees no message loss due to its replication mechanisms.
👇
𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲 𝗥𝗲𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻.
➡️ Database Commit log is piped to a Kafka topic.
➡️ The committed messages are executed against a new Database in the same order.
➡️ Database replica is created.
👇
➡️ Database Commit log is piped to a Kafka topic.
➡️ The committed messages are executed against a new Database in the same order.
➡️ Database replica is created.
👇
𝗟𝗼𝗴/𝗠𝗲𝘁𝗿𝗶𝗰𝘀 𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻.
➡️ Kafka is used for centralized Log and Metrics collection.
➡️ Daemons like FluentD are deployed in servers or containers together with the Applications to be monitored.
➡️ Applications send their Logs/Metrics to the Daemons.
👇
➡️ Kafka is used for centralized Log and Metrics collection.
➡️ Daemons like FluentD are deployed in servers or containers together with the Applications to be monitored.
➡️ Applications send their Logs/Metrics to the Daemons.
👇
➡️ The Daemons pipe Logs/Metrics to a Kafka Topic.
➡️ Logs/Metrics are delivered downstream to storages like ElasticSearch or InfluxDB for Log/Metrics discovery respectively.
➡️ This is also how you would track your IoT Fleets.
👇
➡️ Logs/Metrics are delivered downstream to storages like ElasticSearch or InfluxDB for Log/Metrics discovery respectively.
➡️ This is also how you would track your IoT Fleets.
👇
𝗦𝘁𝗿𝗲𝗮𝗺 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴.
➡️ This is usually coupled with ingestion mechanisms already covered.
➡️ Instead of piping Data to a certain storage downstream we mount a Stream Processing Framework on top of Kafka Topics.
👇
➡️ This is usually coupled with ingestion mechanisms already covered.
➡️ Instead of piping Data to a certain storage downstream we mount a Stream Processing Framework on top of Kafka Topics.
👇
➡️ The Data is filtered, enriched and then piped to the downstream systems to be further used according to the use case.
➡️ This is also where one would be running Machine Learning Models embedded into a Stream Processing Application.
👇
➡️ This is also where one would be running Machine Learning Models embedded into a Stream Processing Application.
👇
𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴.
➡️ Kafka can be used as a replacement for more traditional messaging brokers like RabbitMQ.
➡️ Kafka has better durability guarantees and is easier to configure for several separate Consumer Groups to consume from the same Topic.
👇
➡️ Kafka can be used as a replacement for more traditional messaging brokers like RabbitMQ.
➡️ Kafka has better durability guarantees and is easier to configure for several separate Consumer Groups to consume from the same Topic.
👇
❗️Having said this - always consider the complexity you are bringing with introduction of a Distributed System. Sometimes it is better to just use traditional frameworks.
👇
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh