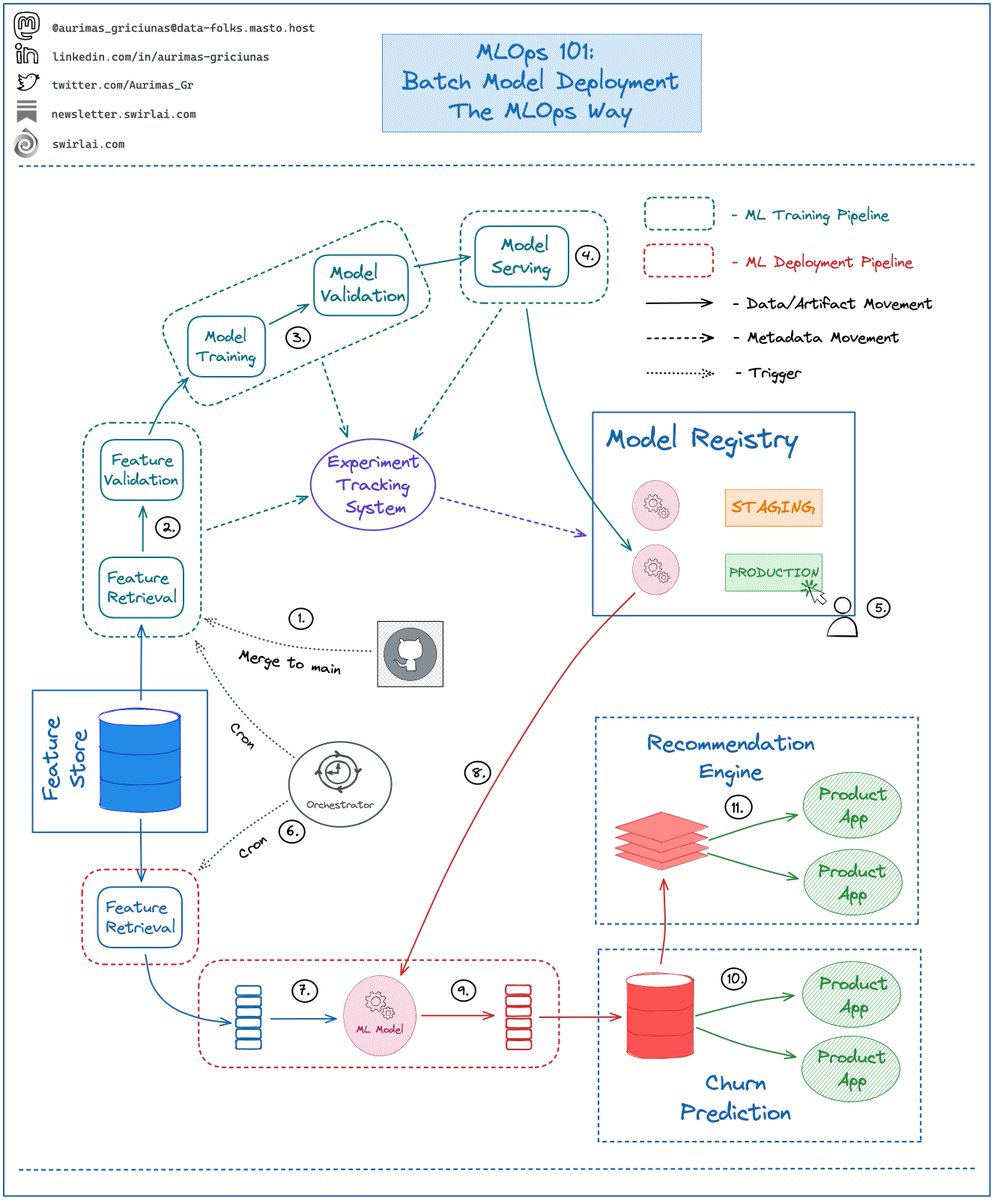
So what is the difference between Row Based and Column Based file formats?
🧵
#Data #DataEngineering #MLOps #MachineLearning
🧵
#Data #DataEngineering #MLOps #MachineLearning
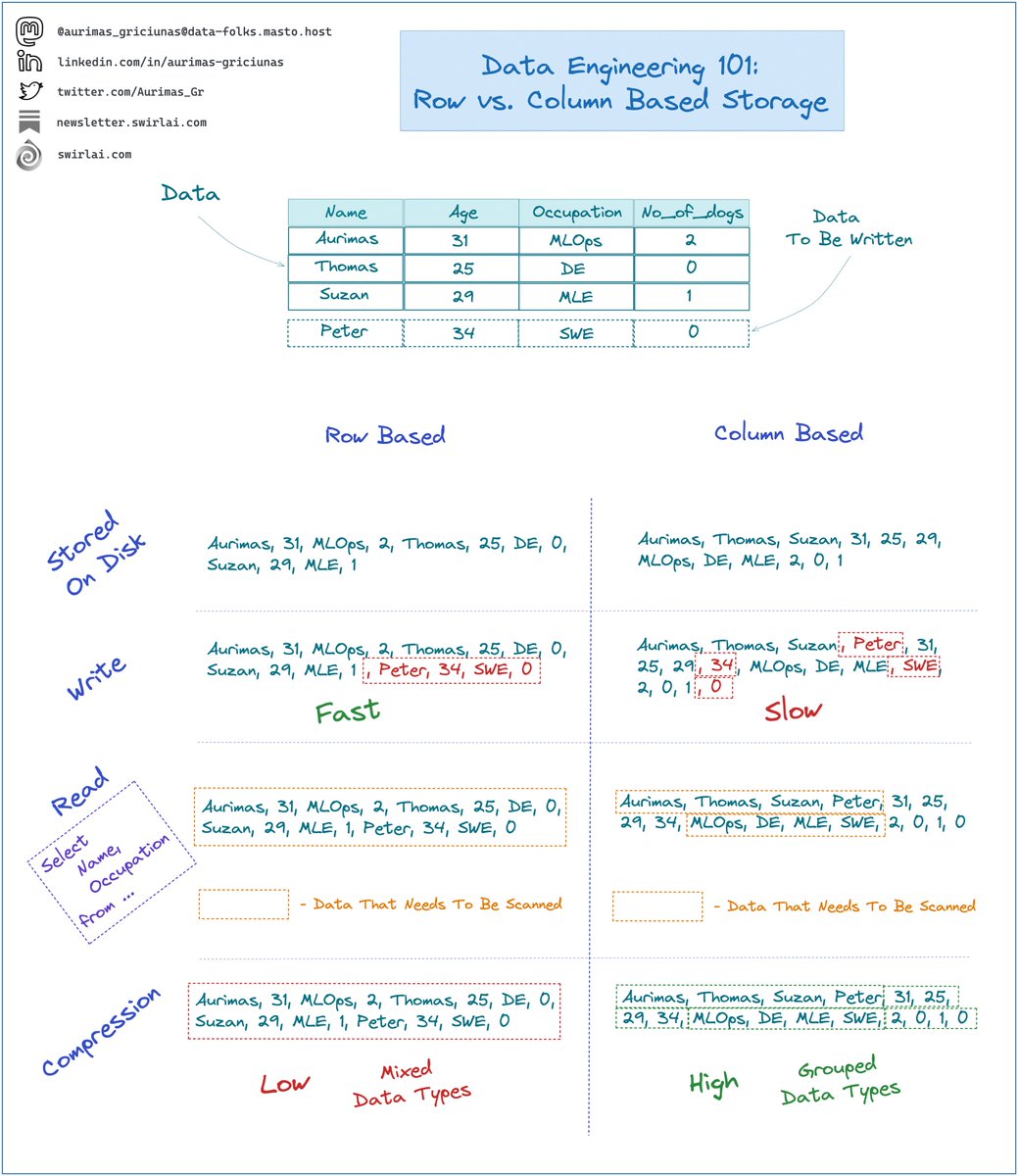
𝗥𝗼𝘄 𝗕𝗮𝘀𝗲𝗱:
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ For select statements that target a subset of columns, reading is slower since you need to scan all sets of rows to retrieve one of the columns.
👇
👇
➡️ Compression is not efficient if columns have different data types since different data types are scattered all around the files.
👉 Example File Formats: 𝗔𝘃𝗿𝗼
✅ Use for 𝗢𝗟𝗧𝗣 purposes.
👇
👉 Example File Formats: 𝗔𝘃𝗿𝗼
✅ Use for 𝗢𝗟𝗧𝗣 purposes.
👇
𝗖𝗼𝗹𝘂𝗺𝗻 𝗕𝗮𝘀𝗲𝗱:
➡️ Columns on disk are stored in sequence.
➡️ New rows are written slowly since you need to write fields of a row into different parts of the file.
👇
➡️ Columns on disk are stored in sequence.
➡️ New rows are written slowly since you need to write fields of a row into different parts of the file.
👇
➡️ For select statements that target a subset of columns, reads are faster than row based storage since you don’t need to scan the entire file.
👇
👇
➡️ Compression is efficient since different data types are always grouped together.
👉 Example File Formats: 𝗣𝗮𝗿𝗾𝘂𝗲𝘁, 𝗢𝗥𝗖
✅ Use for 𝗢𝗟𝗔𝗣 purposes.
👇
👉 Example File Formats: 𝗣𝗮𝗿𝗾𝘂𝗲𝘁, 𝗢𝗥𝗖
✅ Use for 𝗢𝗟𝗔𝗣 purposes.
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh