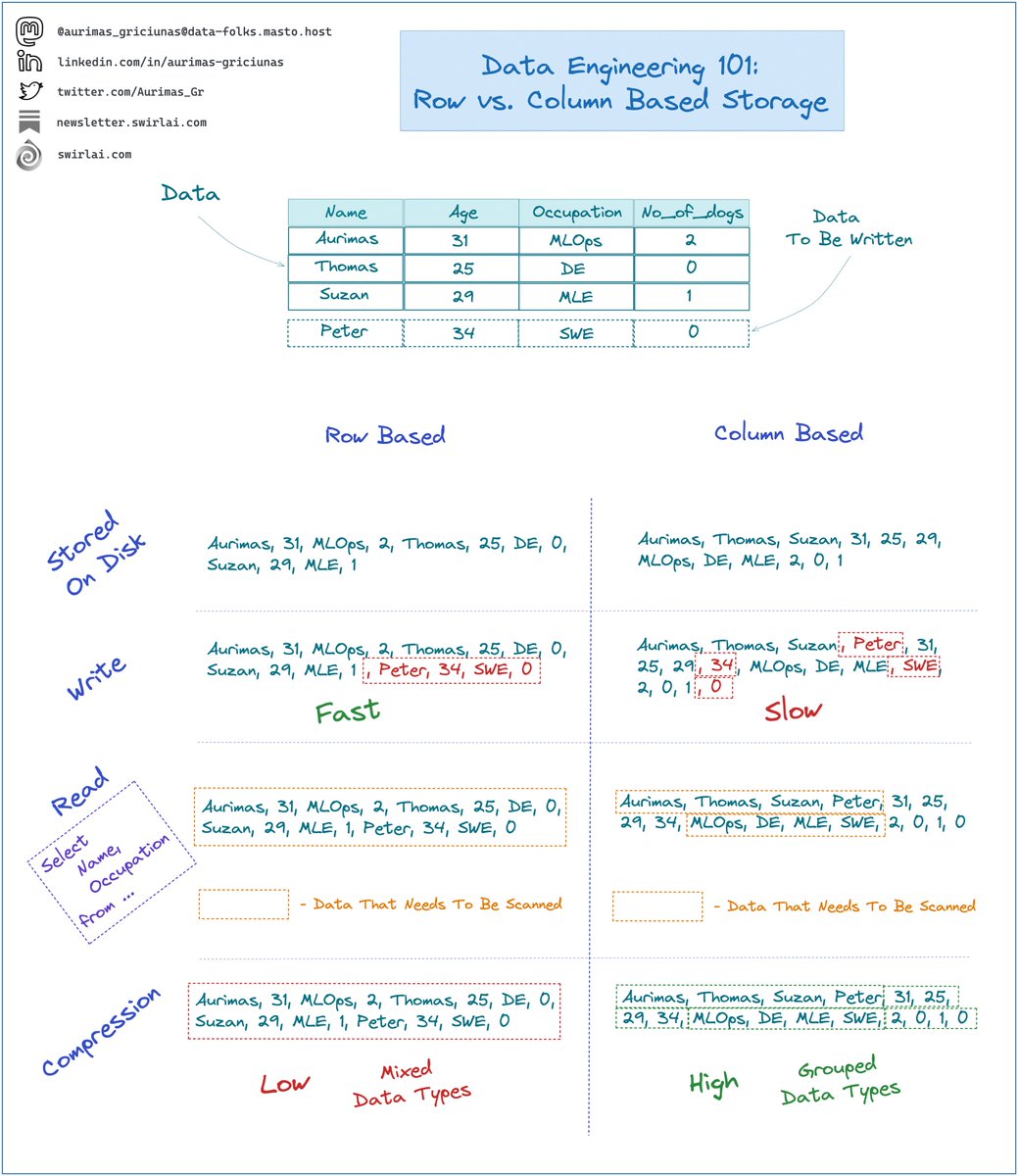
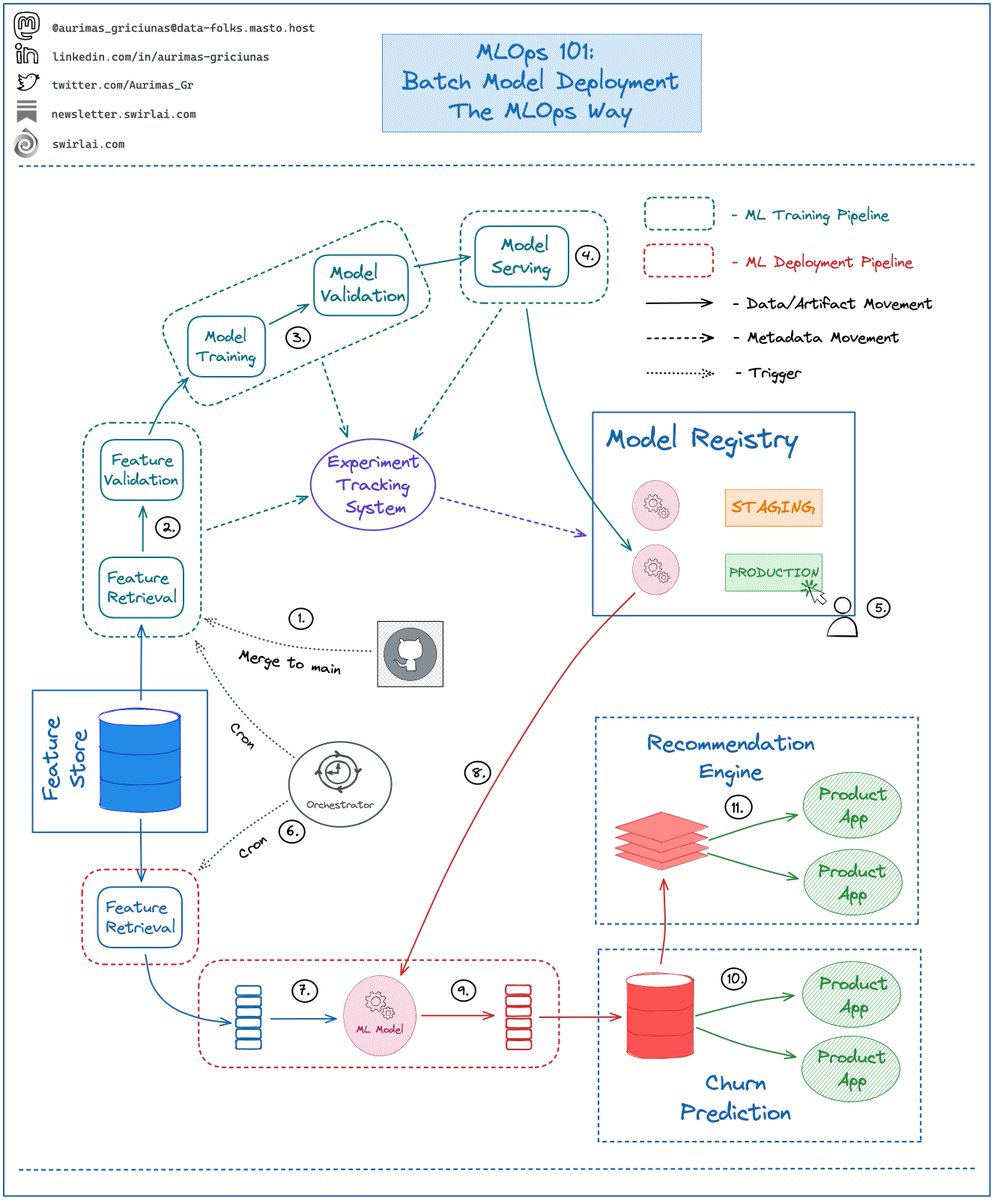
What are the basics of Writing Data to a Kafka Topic?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
➡️ Clients writing to Kafka are called 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀,
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
➡️ Messages sent to Topics are called 𝗥𝗲𝗰𝗼𝗿𝗱𝘀.
➡️ Topics are composed of 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀.
➡️ Each Partition behaves like and is a set of 𝗪𝗿𝗶𝘁𝗲 𝗔𝗵𝗲𝗮𝗱 𝗟𝗼𝗴𝘀.
👇
➡️ Topics are composed of 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀.
➡️ Each Partition behaves like and is a set of 𝗪𝗿𝗶𝘁𝗲 𝗔𝗵𝗲𝗮𝗱 𝗟𝗼𝗴𝘀.
👇
𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮:
➡️ There are two types of records that can be sent to a Topic - 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗶𝗻𝗴 𝗮 𝗞𝗲𝘆 𝗮𝗻𝗱 𝗪𝗶𝘁𝗵𝗼𝘂𝘁 𝗮 𝗞𝗲𝘆.
➡️ If there is no key, then records are written into Partitions in a 𝗥𝗼𝘂𝗻𝗱 𝗥𝗼𝗯𝗶𝗻 𝗳𝗮𝘀𝗵𝗶𝗼𝗻.
👇
➡️ There are two types of records that can be sent to a Topic - 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗶𝗻𝗴 𝗮 𝗞𝗲𝘆 𝗮𝗻𝗱 𝗪𝗶𝘁𝗵𝗼𝘂𝘁 𝗮 𝗞𝗲𝘆.
➡️ If there is no key, then records are written into Partitions in a 𝗥𝗼𝘂𝗻𝗱 𝗥𝗼𝗯𝗶𝗻 𝗳𝗮𝘀𝗵𝗶𝗼𝗻.
👇
➡️ If there is a key, then records with the same keys will always be written to the 𝗦𝗮𝗺𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
➡️ Data is always written to the 𝗘𝗻𝗱 𝗼𝗳 𝘁𝗵𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
👇
➡️ Data is always written to the 𝗘𝗻𝗱 𝗼𝗳 𝘁𝗵𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
👇
➡️ When written, a record gets an 𝗢𝗳𝗳𝘀𝗲𝘁 assigned to it which denotes its 𝗢𝗿𝗱𝗲𝗿/𝗣𝗹𝗮𝗰𝗲 𝗶𝗻 𝘁𝗵𝗲 𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻.
➡️ Partitions have separate sets of Offsets starting from 1.
➡️ Offsets are incremented sequentially when new records are written.
👇
➡️ Partitions have separate sets of Offsets starting from 1.
➡️ Offsets are incremented sequentially when new records are written.
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh