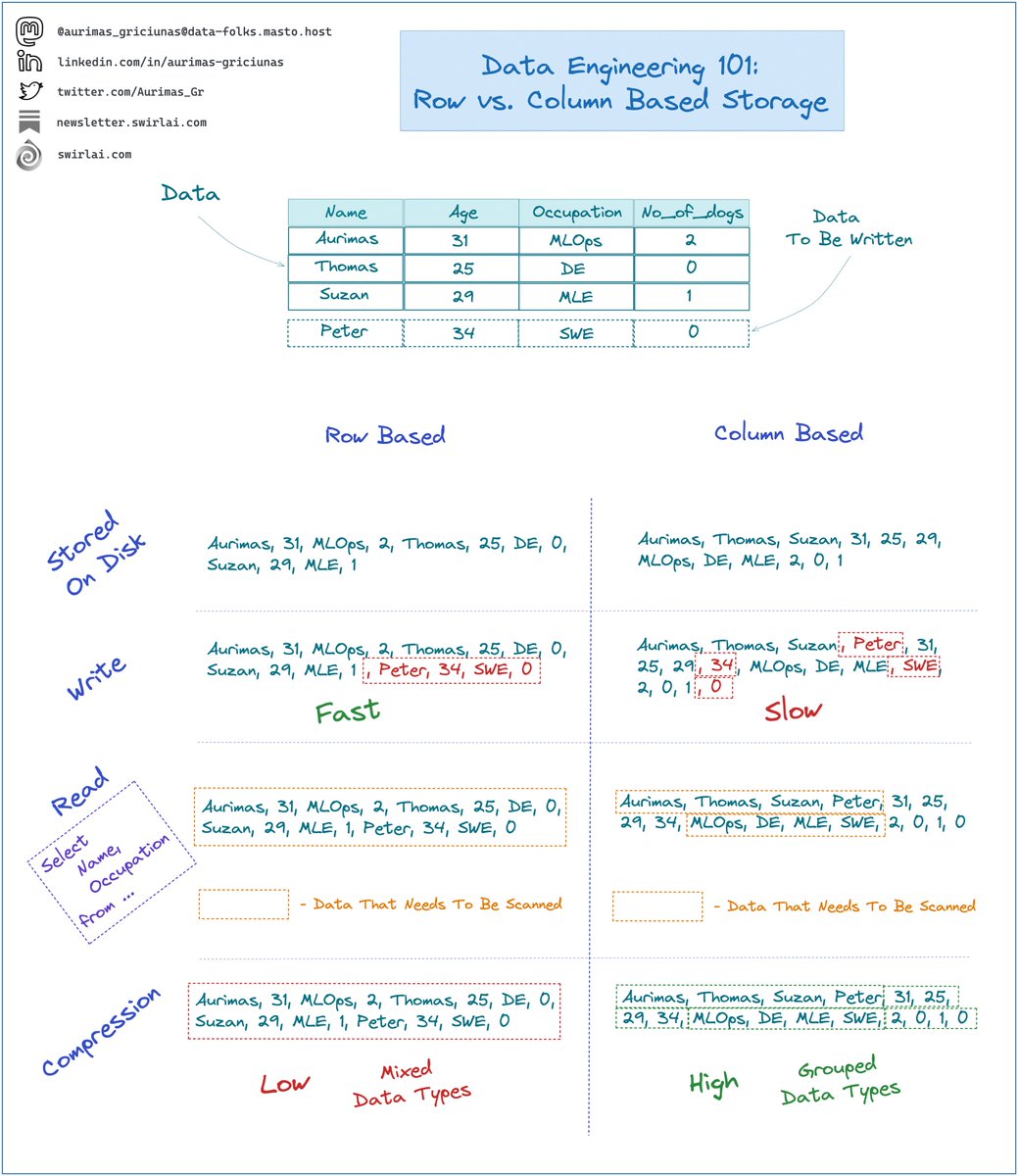
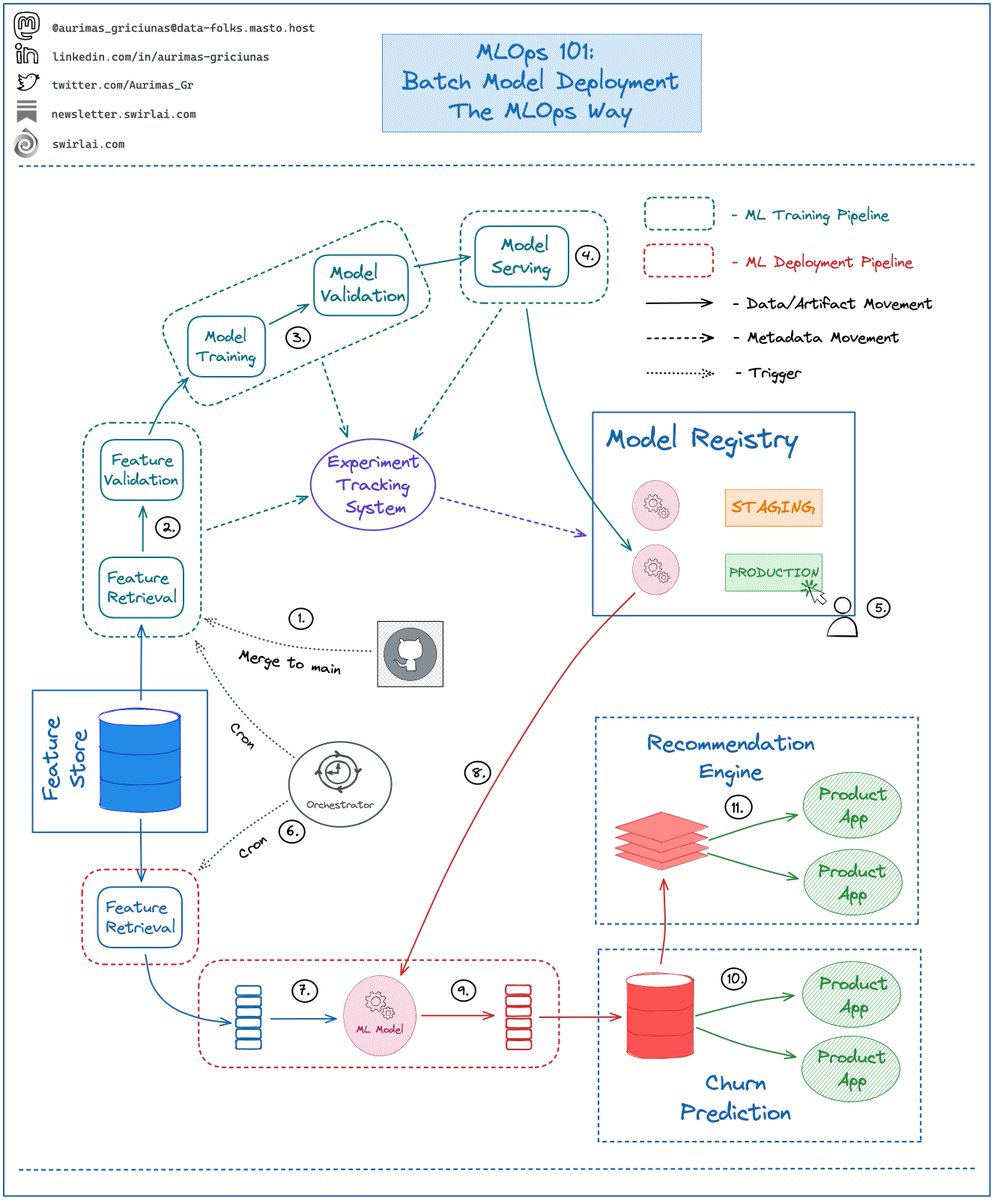
What is a correct Data Engineering Learning Path?
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

I believe that the following is a correct order to start in 𝗬𝗼𝘂𝗿 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗮𝘁𝗵:
👇
👇
➡️ 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝗕𝗮𝘀𝗶𝗰 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗲𝘀:
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
➡️ 𝗟𝗲𝗮𝗿𝗻 𝗺𝗼𝘀𝘁 𝘄𝗶𝗱𝗲𝗹𝘆 𝘂𝘀𝗲𝗱 𝘁𝗼𝗼𝗹𝗶𝗻𝗴 𝗯𝘆 𝗰𝗿𝗲𝗮𝘁𝗶𝗻𝗴 𝗮 𝗽𝗲𝗿𝘀𝗼𝗻𝗮𝗹 𝗽𝗿𝗼𝗷𝗲𝗰𝘁 𝘁𝗵𝗮𝘁 𝗹𝗲𝘃𝗲𝗿𝗮𝗴𝗲𝘀 𝘁𝗵𝗲 𝘁𝗲𝗰𝗵𝗻𝗼𝗹𝗼𝗴𝘆:
👉 Python
👉 SQL
👇
👉 Python
👉 SQL
👇
👉 Airflow - 𝘆𝗲𝘀 𝗔𝗶𝗿𝗳𝗹𝗼𝘄, there are many who say that focusing only on Airflow as a scheduler is a narrow minded approach. Well, you will find Airflow in 99% of job ads - start with it, forget what people say.
👉 Spark
👉 DBT
👇
👉 Spark
👉 DBT
👇
➡️ 𝗟𝗲𝗮𝗿𝗻 𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 𝗗𝗲𝗲𝗽𝗹𝘆:
👉 Data Modeling
👉 Distributed Compute
👉 Stakeholder Management
👉 System Design
👉 …
👇
👉 Data Modeling
👉 Distributed Compute
👉 Stakeholder Management
👉 System Design
👉 …
👇
➡️ 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴/𝗦𝗽𝗲𝗰𝗶𝗮𝗹𝗶𝘇𝗶𝗻𝗴:
👉 Stream Processing
👉 Feature Stores
👉 Data Governance
👉 DataOps
👉 Different tooling to implement the same Basic Processes
👉 ...
👇
👉 Stream Processing
👉 Feature Stores
👉 Data Governance
👉 DataOps
👉 Different tooling to implement the same Basic Processes
👉 ...
👇
👋 I am Aurimas.
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
I will help you Level Up in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space.
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔
Join a growing community of 6500+ Data Enthusiasts by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com/p/sai-21-what-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh