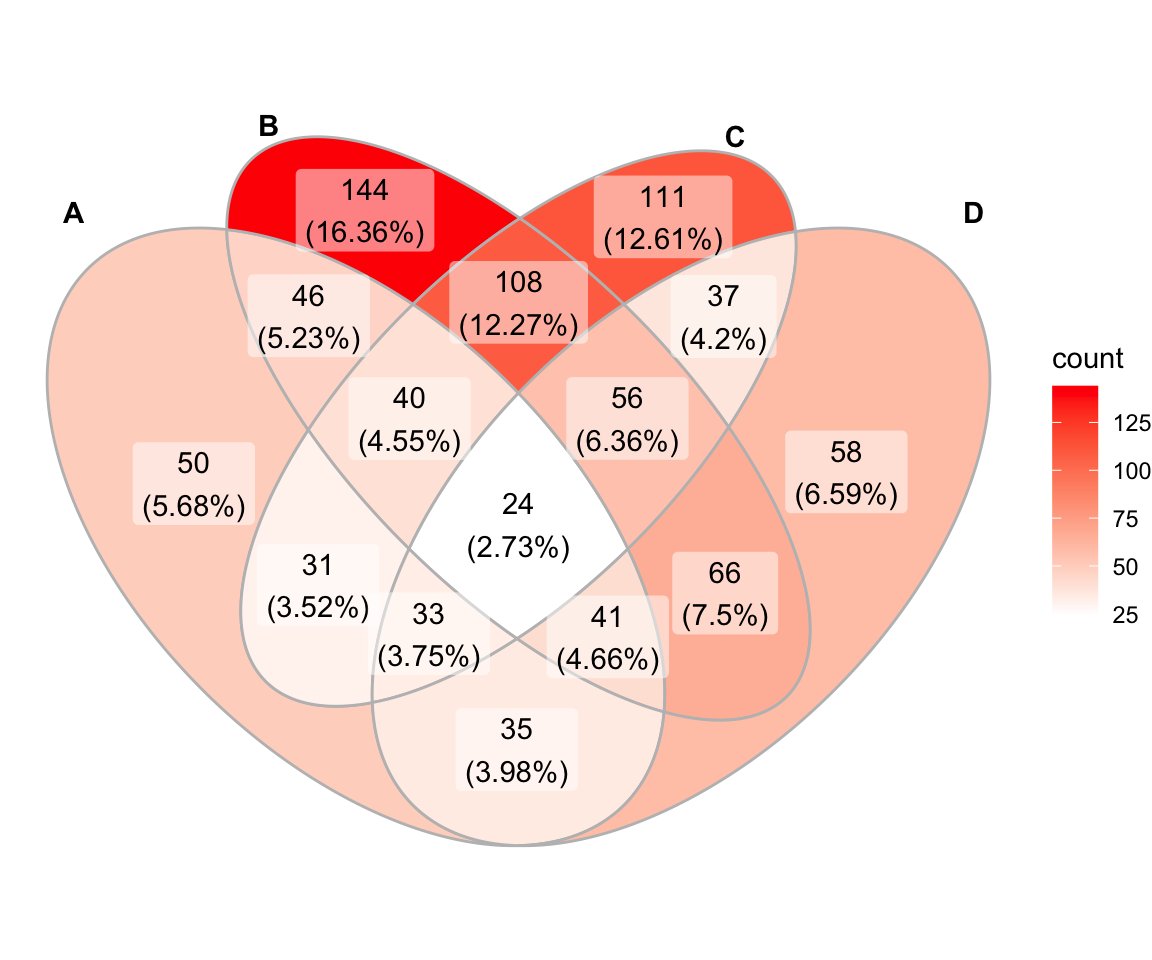
1/ Meta-analysis is a powerful statistical technique for synthesizing data from multiple studies. In R, there are several packages available for conducting meta-analyses. Let's take a look at some of them! #RStats #MetaAnalysis #DataScience 
2/ There are several R packages available to conduct meta-analysis, but some of the most popular include metafor, meta, and netmeta. Each package has its own strengths and weaknesses, so it's important to choose the right one for your specific analysis. #rstats
3/ metafor is a powerful package that can handle complex meta-analyses with multiple predictors and moderators. It also has robust methods for dealing with publication bias. However, it can be a bit tricky to use for beginners. #rstats
4/ If you're interested in conducting a meta-analysis using a random-effects model, the rma function in the metafor package is a good choice. It's easy to use and has several built-in options for estimating the between-study heterogeneity. #rstats
5/ The meta package is another great option, especially for those new to meta-analysis. It's relatively easy to use and has a wide range of models available. However, it's not as powerful as metafor when it comes to handling more complex analyses. #rstats
6/ Finally, if you're looking for a package that's specifically designed for conducting network meta-analyses, then netmeta is the way to go. It's a comprehensive package that can handle a variety of network meta-analysis models. #rstats
• • •
Missing some Tweet in this thread? You can try to
force a refresh