🧵1/10 - Law of Large Numbers (LLN) in R 📈
Hello #Rstats community! Today, we're going to explore the Law of Large Numbers (LLN), a fundamental concept in probability theory, and how to demonstrate it using R. Get ready for some code! 🚀
#Probability #Statistics #DataScience
Hello #Rstats community! Today, we're going to explore the Law of Large Numbers (LLN), a fundamental concept in probability theory, and how to demonstrate it using R. Get ready for some code! 🚀
#Probability #Statistics #DataScience
🧵2/10 - What is LLN? 🧐
LLN states that as the number of trials (n) in a random experiment increases, the average of the outcomes converges to the expected value. In other words, the more we repeat an experiment, the closer we get to the true probability.
#RStats #DataScience
LLN states that as the number of trials (n) in a random experiment increases, the average of the outcomes converges to the expected value. In other words, the more we repeat an experiment, the closer we get to the true probability.
#RStats #DataScience
🧵3/10 - Coin Flip Example 🪙
Imagine flipping a fair coin. The probability of getting heads (H) is 0.5. As we increase the number of flips, the proportion of H should approach 0.5. Let's see this in action with R!
#RStats #DataScience
Imagine flipping a fair coin. The probability of getting heads (H) is 0.5. As we increase the number of flips, the proportion of H should approach 0.5. Let's see this in action with R!
#RStats #DataScience
🧵4/10 - R: Coin Flip Simulation 📊
First, we'll create a simple function to simulate a coin flip:
flip_coin <- function(n) {
outcomes <- sample(c("H", "T"), n, replace = TRUE)
return(outcomes)
}
#RStats #DataScience
First, we'll create a simple function to simulate a coin flip:
flip_coin <- function(n) {
outcomes <- sample(c("H", "T"), n, replace = TRUE)
return(outcomes)
}
#RStats #DataScience
🧵5/10 - R: Running the Experiment 🧪
Now, let's run the experiment for different numbers of flips & store the proportion of H:
n_trials <- seq(10, 100000, 5)
proportion_heads <- sapply(n_trials, function(n) {
flips <- flip_coin(n)
mean(flips == "H")
})
#RStats #DataScience
Now, let's run the experiment for different numbers of flips & store the proportion of H:
n_trials <- seq(10, 100000, 5)
proportion_heads <- sapply(n_trials, function(n) {
flips <- flip_coin(n)
mean(flips == "H")
})
#RStats #DataScience
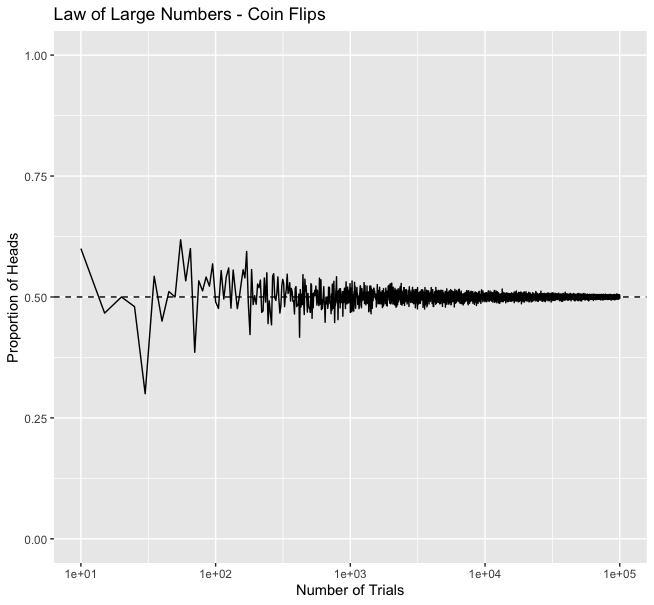
🧵6/10 - R: Visualizing the Results 📉
We'll use ggplot2 to visualize the results:
library(ggplot2)
data <- data.frame(n_trials, proportion_heads)
ggplot(data, aes(x = n_trials, y = proportion_heads)) +
geom_line() +
geom_hline(yintercept = 0.5, linetype = "dashed") +
We'll use ggplot2 to visualize the results:
library(ggplot2)
data <- data.frame(n_trials, proportion_heads)
ggplot(data, aes(x = n_trials, y = proportion_heads)) +
geom_line() +
geom_hline(yintercept = 0.5, linetype = "dashed") +
ylim(c(0,1)) +
scale_x_log10() +
labs(title = "Law of Large Numbers - Coin Flips",
x = "Number of Trials",
y = "Proportion of Heads")
#RStats #DataScience
scale_x_log10() +
labs(title = "Law of Large Numbers - Coin Flips",
x = "Number of Trials",
y = "Proportion of Heads")
#RStats #DataScience

🧵7/10 - Interpreting the Plot 📈
The plot shows that as the number of trials increases, the proportion of H converges to 0.5, confirming the Law of Large Numbers.
#RStats #DataScience
The plot shows that as the number of trials increases, the proportion of H converges to 0.5, confirming the Law of Large Numbers.
#RStats #DataScience
🧵8/10 - Real-World Applications 🌎
LLN has many real-world applications, such as predicting stock prices, insurance premium calculations, and assessing the performance of machine learning models.
#RStats #DataScience #MachineLearning
LLN has many real-world applications, such as predicting stock prices, insurance premium calculations, and assessing the performance of machine learning models.
#RStats #DataScience #MachineLearning
🧵9/10 - Limitations of LLN ⚠️
Keep in mind that LLN doesn't guarantee a specific outcome in any single trial, and it doesn't say how fast the convergence occurs. The speed of convergence depends on the specific problem.
#Statistics #Probability #RStats #DataScience
Keep in mind that LLN doesn't guarantee a specific outcome in any single trial, and it doesn't say how fast the convergence occurs. The speed of convergence depends on the specific problem.
#Statistics #Probability #RStats #DataScience
🧵10/10 - Conclusion 🎉
We've successfully demonstrated the Law of Large Numbers in R using a coin flip example. Remember, this is just a simple example, and you can apply the same logic to more complex problems.
Happy coding! 🚀
#Rstats #DataScience #Probability
We've successfully demonstrated the Law of Large Numbers in R using a coin flip example. Remember, this is just a simple example, and you can apply the same logic to more complex problems.
Happy coding! 🚀
#Rstats #DataScience #Probability
• • •
Missing some Tweet in this thread? You can try to
force a refresh