
1/🧵🔍 Making sense of Principal Component Analysis (PCA), Eigenvectors & Eigenvalues: A simple guide to understanding PCA and its implementation in R! Follow this thread to learn more! #RStats #DataScience #PCA 
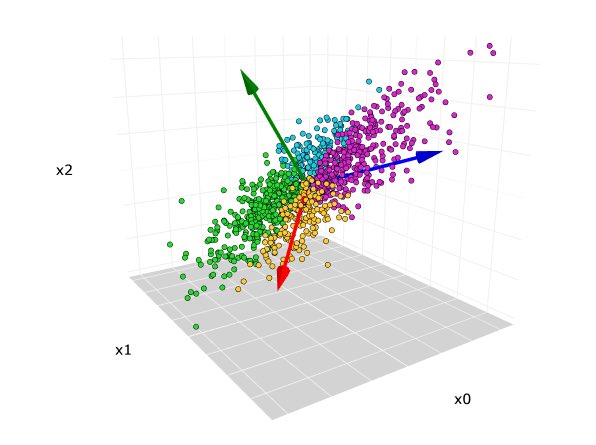
2/📚PCA is a dimensionality reduction technique that helps us to find patterns in high-dimensional data by projecting it onto a lower-dimensional space. It's often used for data visualization, noise filtering, & finding variables that explain the most variance. #DataScience
3/🎯 The goal of PCA is to identify linear combinations of original variables (principal components) that capture the maximum variance in the data, with each principal component being orthogonal to the others. #RStats #DataScience
4/📐 Eigenvectors & Eigenvalues: Eigenvectors represent the directions of the new feature space, while eigenvalues define the magnitude of these directions. They play a key role in PCA, as they help to identify the principal components. #RStats #DataScience
5/🔧 In R, the 'prcomp()' function in the 'stats' package makes PCA implementation easy. It computes the principal components and returns a list containing eigenvalues, eigenvectors, and more.
pca_result <- prcomp(data, scale. = TRUE)
#RStats #DataScience
pca_result <- prcomp(data, scale. = TRUE)
#RStats #DataScience
6/📊 Visualize the explained variance ratio using a scree plot. This helps to decide the optimal number of principal components to keep.
explained_variance <- pca_result$sdev^2 / sum(pca_result$sdev^2)
plot(explained_variance, type='b', main="Scree Plot")
#RStats #DataScience
explained_variance <- pca_result$sdev^2 / sum(pca_result$sdev^2)
plot(explained_variance, type='b', main="Scree Plot")
#RStats #DataScience
7/🌐 Biplot: A biplot is a graphical representation of the original variables and observations in the space of the first two principal components.
biplot(pca_result, scale = 0, main = "Biplot")
#RStats #DataScience
biplot(pca_result, scale = 0, main = "Biplot")
#RStats #DataScience
8/🔄 Transforming the original data into the principal component space can be done using the 'predict()' function.
transformed_data <- predict(pca_result, data)
#RStats #DataScience
transformed_data <- predict(pca_result, data)
#RStats #DataScience
9/💡 Remember that PCA is a linear technique, so it might not be suitable for datasets with non-linear relationships. Always consider the nature of your data before applying PCA. #RStats #DataScience
10/🔚 That's it! You've learned the basics of PCA, eigenvectors, and eigenvalues, and how to implement PCA in R. Now you can explore high-dimensional datasets more effectively and make better sense of your data! #RStats #DataScience
• • •
Missing some Tweet in this thread? You can try to
force a refresh








