
Complex networks, infectious diseases, data science || Science is what you understand well enough to explain to a computer [D.Knuth]

 La mappa mostra una stima del rischio di essere esposti al virus SARS-CoV-2 per provincia, sulla base del numero di persone che partecipano ad un evento. Il rischio è espresso come la probabilità che almeno un individuo positivo sia presente all'evento. 👇
La mappa mostra una stima del rischio di essere esposti al virus SARS-CoV-2 per provincia, sulla base del numero di persone che partecipano ad un evento. Il rischio è espresso come la probabilità che almeno un individuo positivo sia presente all'evento. 👇
 In this work we analyzed a large dataset of de-identified CDRs from mobile phone users in Santiago, Chile, and tried to answer the question: do women move differently than men, in the city? tl;dr - Yes, they do.
In this work we analyzed a large dataset of de-identified CDRs from mobile phone users in Santiago, Chile, and tried to answer the question: do women move differently than men, in the city? tl;dr - Yes, they do. 
 Users’ movements between different provinces are now at -30%, on average, w.r.t the baseline. The median of users’ movements on connections within the same region has increased to -27%. Movements on connections between provinces of different regions have increased to -60%.
Users’ movements between different provinces are now at -30%, on average, w.r.t the baseline. The median of users’ movements on connections within the same region has increased to -27%. Movements on connections between provinces of different regions have increased to -60%. 
 Allo stato attuale, il modello desume che circa l'8% della popolazione italiana sia stato contagiato nel corso degli ultimi 3 mesi. Ci sono grandi variazioni regionali: nel Nord Italia il numero dei contagiati è probabilmente superiore al 10% mentre nel Sud è inferiore al 4%.
Allo stato attuale, il modello desume che circa l'8% della popolazione italiana sia stato contagiato nel corso degli ultimi 3 mesi. Ci sono grandi variazioni regionali: nel Nord Italia il numero dei contagiati è probabilmente superiore al 10% mentre nel Sud è inferiore al 4%. 

 The current standing of R by region is shown here. Lazio and Piedmont still on the edge of R=1. Veneto looks solid under control. Code available here: github.com/micheletizzoni…
The current standing of R by region is shown here. Lazio and Piedmont still on the edge of R=1. Veneto looks solid under control. Code available here: github.com/micheletizzoni… 
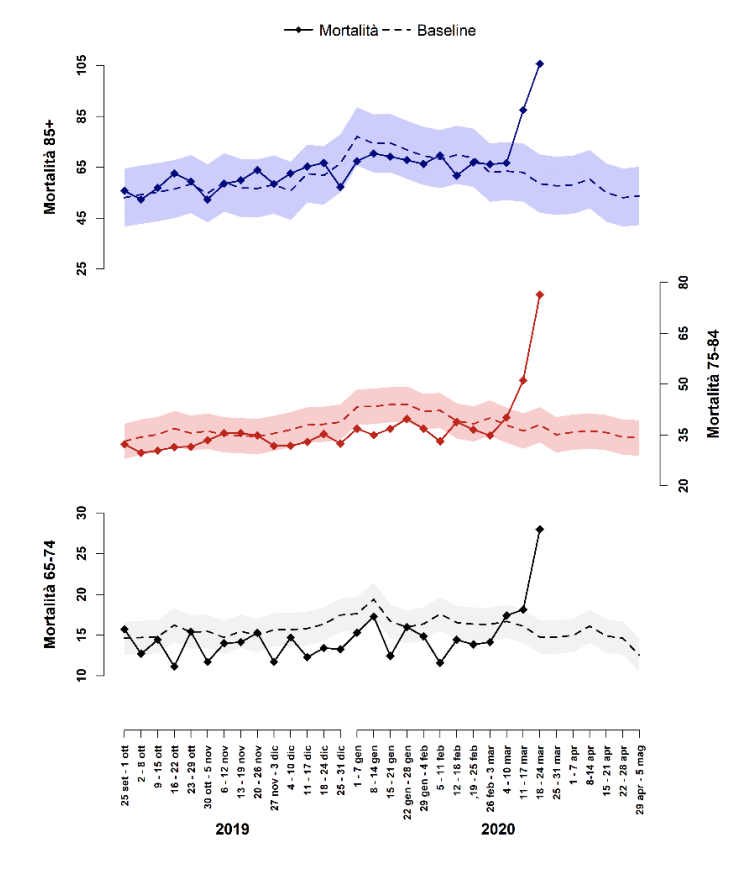 The above charts refer only to Northern Italy. These numbers are not comparable to any past flu season. Before jumping to conclusions, take a closer look at the chart below: it's updated to the week 4 of 2020, which means January. Data is still missing.
The above charts refer only to Northern Italy. These numbers are not comparable to any past flu season. Before jumping to conclusions, take a closer look at the chart below: it's updated to the week 4 of 2020, which means January. Data is still missing. 
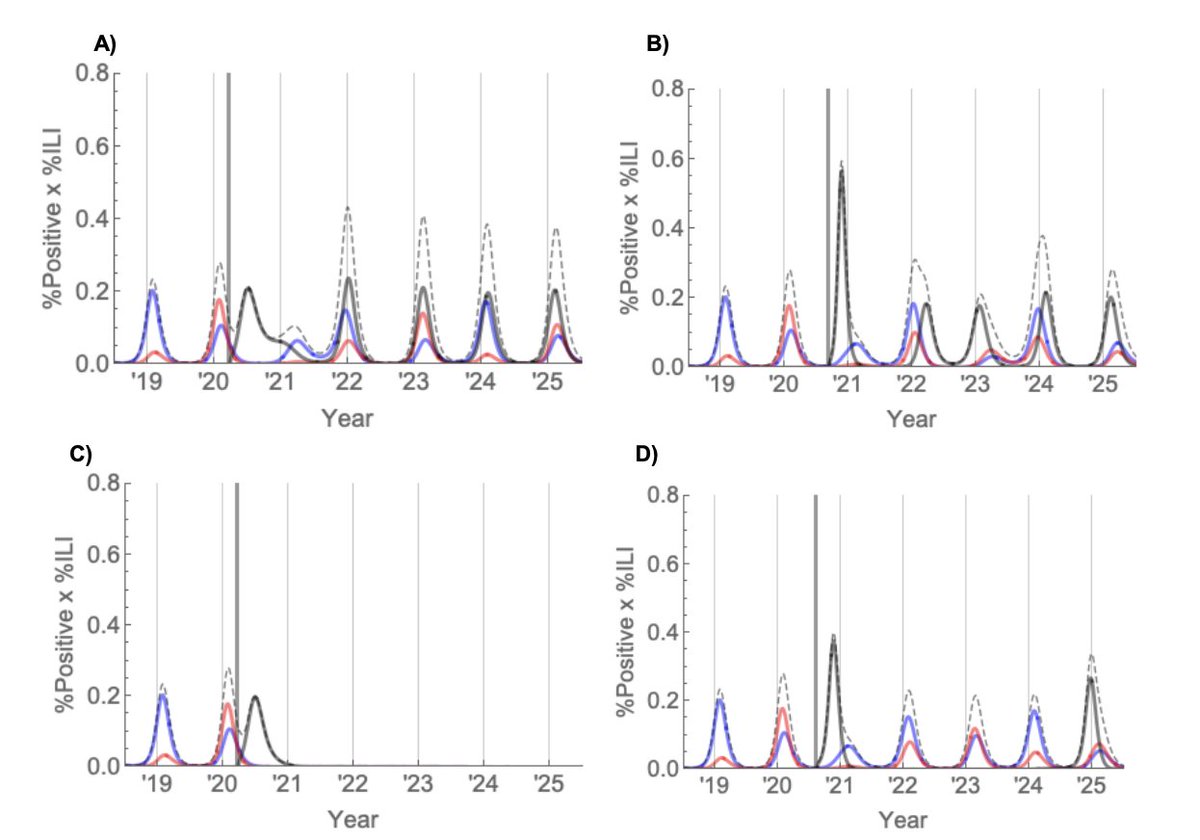
 Alcuni ricercatori dell'Università di Toronto lo hanno fatto, pubblicando i risultati qui: medrxiv.org/content/10.110… [attenzione non è ancora un studio peer-reviewed]. Tra gli autori: @DFisman @AshTuite (2/n)
Alcuni ricercatori dell'Università di Toronto lo hanno fatto, pubblicando i risultati qui: medrxiv.org/content/10.110… [attenzione non è ancora un studio peer-reviewed]. Tra gli autori: @DFisman @AshTuite (2/n)