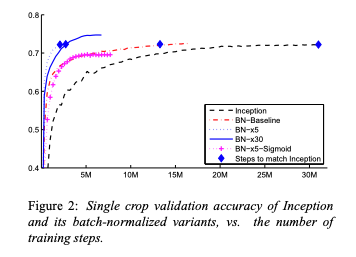
The paper that introduced Batch Norm arxiv.org/abs/1502.03167 combines clear intuition with compelling experiments (14x speedup on ImageNet!!)
So why has 'internal covariate shift' remained controversial to this day?
Thread 👇
So why has 'internal covariate shift' remained controversial to this day?
Thread 👇
A recent question on Twitter from @yoavgo shows that there's still confusion about how Batch Norm works in practice:
@TheGregYang's answer to the thread provides insight on a related topic, outlining limitations of BN for very deep nets and the need for residual connections...
...but it doesn't explain why BN works!
...but it doesn't explain why BN works!
Studies at initialisation can't! For that you have to look at what happens during training.
We're going to answer @yoavgo's question and explain how BN works, based on old understanding and new progress from the last year.
We will come down firmly in support of 'internal covariate shift' as the underlying issue (claims to the contrary notwithstanding.)
We shall even define what we mean by the term! @alirahimi0
We shall even define what we mean by the term! @alirahimi0
Let's get started.
What does the original paper have to say?
What does the original paper have to say?

'Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates…'
The authors named this phenomenon ‘internal covariate shift’ and fixed it in a natural way by controlling the first two moments of layer distributions.
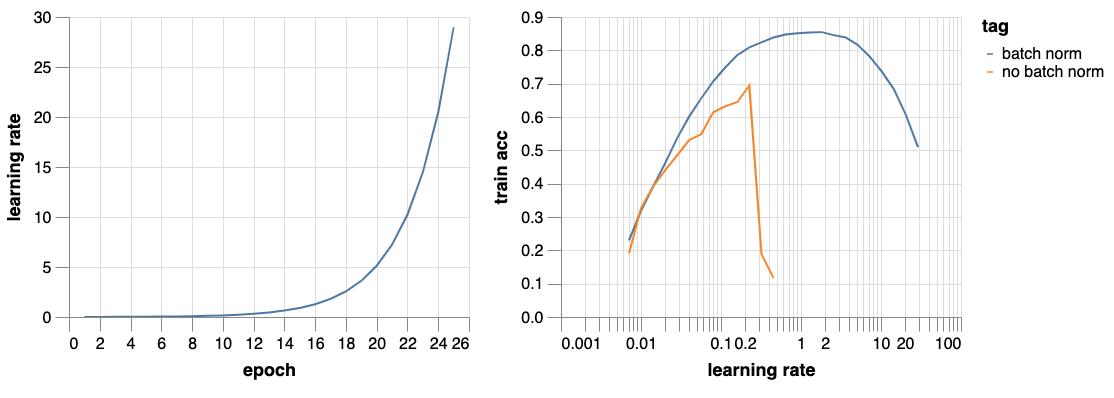
This enables much faster training at higher LRs and became standard practice.
This enables much faster training at higher LRs and became standard practice.

A possible source of confusion: the phrase ‘internal covariate shift’ seems to hint at domain adaptation rather than the pure optimisation issue described above.
Now let’s go back further.
In the olden days it was understood that training deep nets is a hard optimisation problem.
(Things have since gotten simpler so it’s easy to forget!)
In the olden days it was understood that training deep nets is a hard optimisation problem.
(Things have since gotten simpler so it’s easy to forget!)
Among the tricks that practitioners used, centering, normalising and decorrelating inputs were known to be helpful.
(@ylecun et al ’98) yann.lecun.com/exdb/publis/pd…
(@ylecun et al ’98) yann.lecun.com/exdb/publis/pd…
There was theory too!
For a single layer, centering improves conditioning of the Hessian of the loss, enabling higher learning rates.
(@ylecun et al ’90) papers.nips.cc/paper/314-seco…
For a single layer, centering improves conditioning of the Hessian of the loss, enabling higher learning rates.
(@ylecun et al ’90) papers.nips.cc/paper/314-seco…
The intuition is simple. If the inputs to a neuron have non-zero mean then shifting weights in parallel moves the output mean.
(If that output is a ‘cat’ neuron, a change in mean can lead to predicting ‘cat’ on every example!)
(If that output is a ‘cat’ neuron, a change in mean can lead to predicting ‘cat’ on every example!)
Since this affects all the training examples, it will dominate effects that vary from sample to sample (in the absence of strong input correlations.)
It was understood that it should be helpful to center and normalise hidden layers - not just inputs - but the technique wasn't fully developed…
...until the Batch Norm paper which proved that this works, allowing training at much higher LRs!
According to the old wisdom, this comes from better conditioning of the Hessian.
According to the old wisdom, this comes from better conditioning of the Hessian.

Recent papers have studied the Hessian of the loss for deep nets experimentally:
(@leventsagun et al) arxiv.org/abs/1611.07476, arxiv.org/abs/1706.04454
(Papyan) arxiv.org/abs/1811.07062.
(@_ghorbani et al) arxiv.org/abs/1901.10159 compare what happens with and without BN.
(@leventsagun et al) arxiv.org/abs/1611.07476, arxiv.org/abs/1706.04454
(Papyan) arxiv.org/abs/1811.07062.
(@_ghorbani et al) arxiv.org/abs/1901.10159 compare what happens with and without BN.
These results are exciting because they give quantitative insight into how BN aids optimisation!
Outlying eigenvalues of the Hessian are removed in a way reminiscent of the old analyses…
Outlying eigenvalues of the Hessian are removed in a way reminiscent of the old analyses…

So how to relate outlying eigenvalues to changes in hidden layer distributions?
Insight comes from identifying directions in parameter space that produce large changes in output distribution.
Insight comes from identifying directions in parameter space that produce large changes in output distribution.

The biggest impacts come from synchronised changes in distribution throughout the network - giving a precise definition of problematic 'internal covariate shift' !

The same directions span the outlying subspace of the Hessian and limit the learning rate.
This is unsurprising - a large change in output distribution wreaks havoc with predictions (as with the ‘cat’ neuron above.)
This is unsurprising - a large change in output distribution wreaks havoc with predictions (as with the ‘cat’ neuron above.)

So we have given precise experimental meaning to the statement that 'internal covariate shift' limits LRs and that BN works by preventing this...
...matching the intuition of the original paper!
...matching the intuition of the original paper!
Thanks to @jeremyphoward for encouraging me to write this up and feedback on an early draft!