
1/32 Okay #medtwitter #epitwitter , as promised here’s a #Tweetorial on diagnostic test performance study design. Who am I to do this? My PhD is in #biostatistics, I direct the @MayoClinicSOM #EBM curriculum, and I teach Bayesian Diagnostic Testing Strategies @MayoGradSchool.
2/ Yep, this is a little wonkish but really not so complicated. And anyway, when I hear “wonkish” I hear:
3/ BLUF: To date, how many studies of #COVID19 diagnostic tests have been conducted ideally, with fully appropriate measures to minimize risk of bias?
4/ There has been some discussion of problematic test characteristics for #COVID19.
mayoclinicproceedings.org/pb/assets/raw/… or
COVID-19 Testing: The Threat of False-Negative Results sciencedirect.com/science/articl… #EBM
@MayoProceedings Also note ja.ma/3ct4UPD from @marcottl @JoshuaLiaoMD
mayoclinicproceedings.org/pb/assets/raw/… or
COVID-19 Testing: The Threat of False-Negative Results sciencedirect.com/science/articl… #EBM
@MayoProceedings Also note ja.ma/3ct4UPD from @marcottl @JoshuaLiaoMD
5/ There has also been lots of review of problematic #COVID19 therapy studies by @VinayPrasad @ProfDFrancis @rbganatra and others. Unsurprisingly, there are similar concerns about the data on diagnostic test performance, but these are less discussed.
6/ These are not easy studies to do well, but it’s important to understand the limitations of the data we see (when we see it … very little has even been reported). Hence this #EBM #Tweetorial.
7/ Users' Guides to the Medical Literature: A Manual for Evidence-Based Clinical Practice, 3rd ed bit.ly/2xAx8tc is an excellent source for this content (online restricted but can buy). Let’s walk through the risk-of-bias elements, with some additions here and there.
8/ Q1: “Did Participating Patients Constitute a Representative Sample of Those Presenting With a Diagnostic Dilemma?” I.e., participants should resemble the unknowns (diagnostic dilemmas) we see in clinical practice, NOT have established diagnoses!
9/ Including participants with established diagnoses leads to overestimates of diagnostic test performance. This is nearly universal in laboratory studies of diagnostic tests. Why?
10/ If a test fails the lower bar of the “known diagnoses” sample, we can stop investigating it because it’s not a good enough test for general use. This could be efficient from a research standpoint. However, I worry the more common reason is lack of understanding of this bias.
11/ So Point #1: most if not all studies to date of #COVID19 diagnostic test performance are biased to show better performance than they will have in actual practice. If we have concerns about them now, the reality is worse.
12/ On to Q2: “Did the Investigators Compare the Test to an Appropriate, Independent Reference Standard?” What is the gold standard for #COVID19 testing so far? This is tough, because it’s a NOVEL coronavirus.
13/ Sometimes the totality of clinical evidence can work (samples from other sites, results from other tests, etc.), but if these overlap with the diagnostic test, guess what? This again leads to overestimates of diagnostic test performance, and it’s happening!
14/ So Point #2: without a clearly defined and appropriate gold standard, the diagnostic performance of a test cannot be determined with any sense of assurance.
15/ Wow, we need @SomeGoodNews
16/ On to Q3: “Were those interpreting the test and reference standard blind to the other result?” Good news -- for interpretation of laboratory assay sorts of tests, blinding is usually not a concern!
17/ So Point #3: blinding for #COVID19 lab assays shouldn’t adversely impact risk of bias for these studies.
18/ On to Q4, the final question, and it’s a doozy: “Did Investigators Perform the Same Reference Standard in All Patients Regardless of the Results of the Test Under Investigation?” This is sometimes called verification or work-up bias. It has two common forms.
19/ First, the gold standard may be done more in higher-risk patients (less commonly the other way), in whom the risks of this often more costly and more invasive testing may be considered more justifiable. What effect does this have? Let’s look at a 2x2 table example.
20/ In this table, with disease prevalence 10%,
Sensitivity = 70%
Specificity = 95%
LR+ = 14
LR- = 0.32
These are not dissimilar to #COVID19 data floating around, although hardly universally agreed upon.
Sensitivity = 70%
Specificity = 95%
LR+ = 14
LR- = 0.32
These are not dissimilar to #COVID19 data floating around, although hardly universally agreed upon.
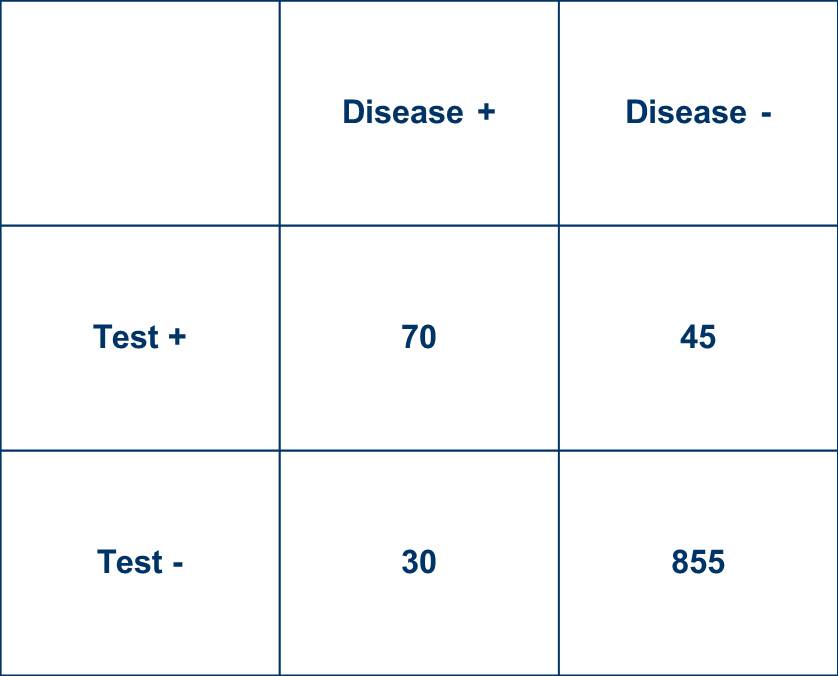
21/ Don’t like these numbers? Enter your own! There are lots of online calculators to help with this. Here’s a nice modifiable one from @masnick and @dr_dmorgan prepopulated with data from @zbinney_NFLinj: calculator.testingwisely.com/playground/4.5….
22/ Now suppose 1/3 of participants with negative diagnostic tests don’t get the gold standard, divided proportionately among those with and without disease. What happens?
23/ The disease prevalence estimate ⬆️ a bit, and the revised (and now biased) diagnostic test performance stats are:
Sensitivity = 78%, ⬆️ from 70%
Specificity = 93%, ⬇️ from 95%
LR+ = 10.6, ⬇️ from 14
LR- = 0.24, better than 0.32
So the LR- looks 25% better than it really is.
Sensitivity = 78%, ⬆️ from 70%
Specificity = 93%, ⬇️ from 95%
LR+ = 10.6, ⬇️ from 14
LR- = 0.24, better than 0.32
So the LR- looks 25% better than it really is.
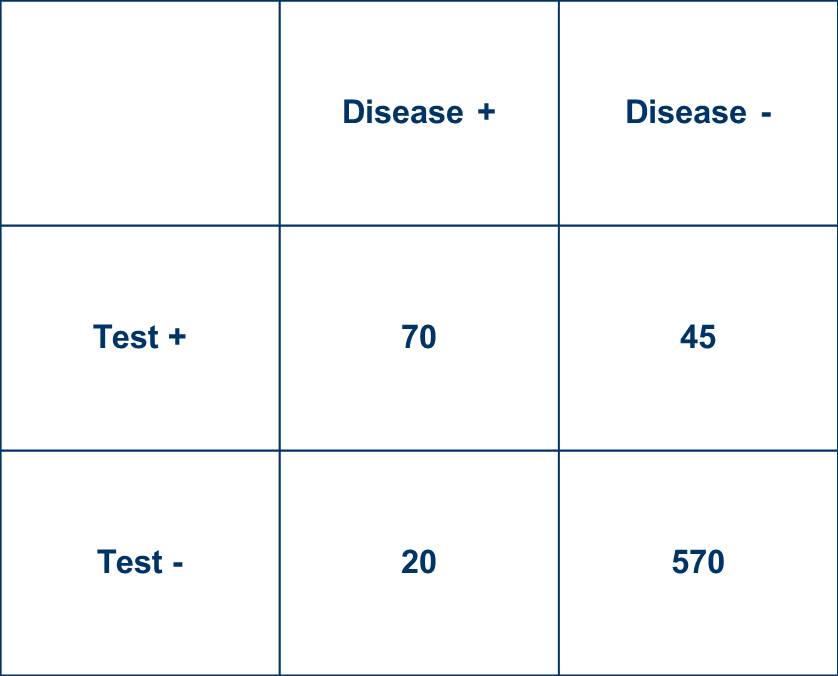
24/ Again, if we have concerns about the tests now, especially for false-negative rates, the reality may be worse.
25/ Oh yeah, I said there were two common forms of verification bias issues in diagnostic test studies, I almost forgot. The other one is a bit subtle, but occurs when participants are included retrospectively based on having had both the diagnostic test and the gold standard.
26/ This skews things because patients who got both tests are quite likely to be different from the full sample of those who presented as a diagnostic dilemma before any testing at all (back to Q1). These studies are easy to do from clinical databases. But are they good?
27/ Unfortunately, they generally introduce bias. So Point #4: the best way to do these studies is to prospectively enroll participants at risk but without known diagnoses and ensure everyone gets both the proposed test and a good gold/reference standard, period.
28/ Bringing this back full circle, how many studies of #COVID19 diagnostic tests to date have been conducted ideally, with fully appropriate measures to minimize risk of bias?
29/ As @PSampathkumarMD @vmontori and I wrote in @MayoProceedings mayoclinicproceedings.org/pb/assets/raw/… , “The challenge of COVID-19 must be faced with our best science”.
30/ And with that, I’ll bring this to a close.
31/ Did you enjoy this #EBM #Tweetorial? RT if you liked it, and please add to the conversation! Future topics might include more on the impact of FN and FP at different #COVID19 prevalence levels, how these inform #COVID19 pandemic control, or … what else would you like to see?
32/ Sharing the #Tweetorial with #EBM experts, pass it on to others I missed! @adamcifu @VPrasadMDMPH @vmontori @TheSGEM @nataliexdean @medpedshosp @PaulBerglMD @EvidenceBasedMD @RichardLehman1 @StephRStarr @neeraagrwal @CStephenson_MD @CarinaHimes @CourtHarrisMD @jaegermeister58

