How ON EARTH did the government manage to temporarily mislay 16,000 test results, putting thousands of people at risk of contracting #COVID19?
I try to explain it here.
Warning: you may find yourself shouting at the screen as you read it news.sky.com/story/coronavi…
I try to explain it here.
Warning: you may find yourself shouting at the screen as you read it news.sky.com/story/coronavi…
A thread with some of the main details:
The key point (and perhaps the second most important revelation today) is that sitting at the very apex of Britain's testing system is a PHE computer system which processes test results and sends positive cases onto Test & Trace.
The key point (and perhaps the second most important revelation today) is that sitting at the very apex of Britain's testing system is a PHE computer system which processes test results and sends positive cases onto Test & Trace.
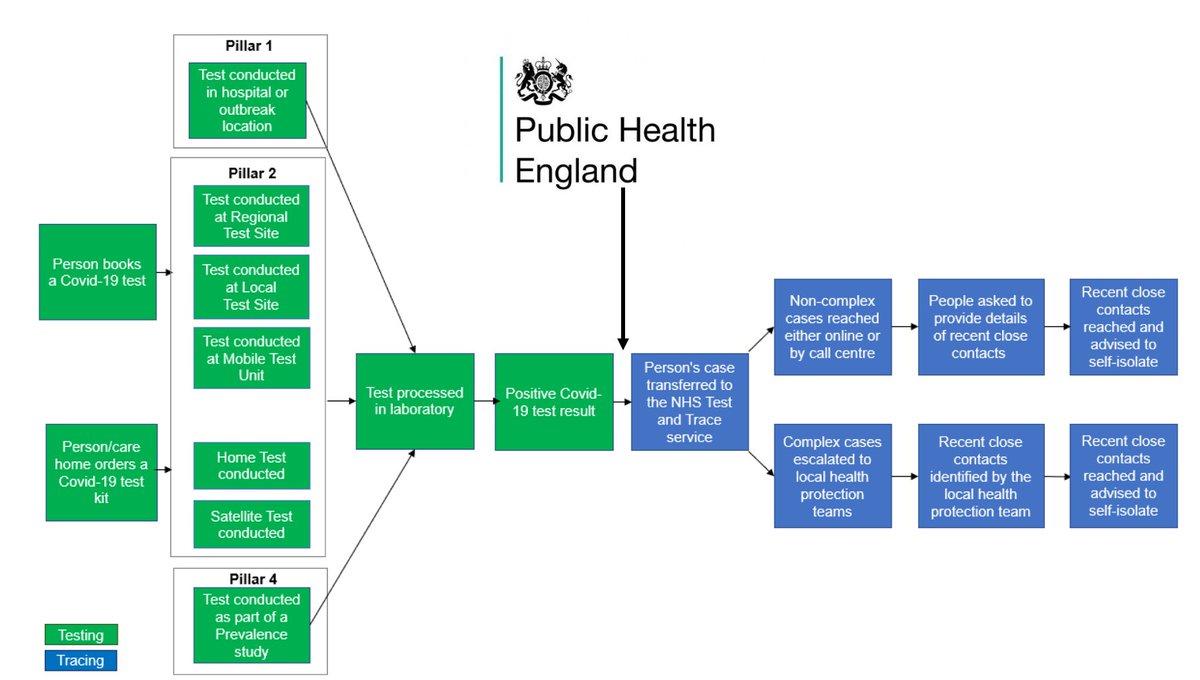
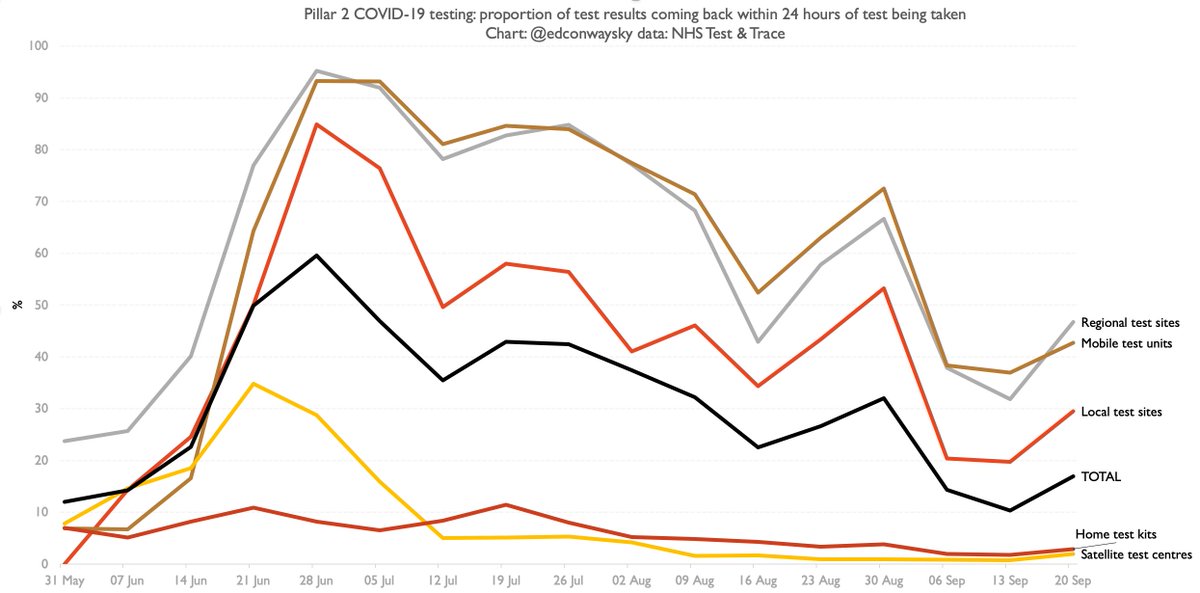
Now, this computer system works very well when it comes to the test result data coming in from the established pathology labs (pillar 1). There's a secure FTP link from them to something called SGSS. No problems there. But more testing these days is being done by "pillar 2"
"Pillar 2", you'll prob recall, is the centralised bit - the new bit, the Lighthouse Lab/Deloitte/Serco bit. And for some reason no-one can explain to me they haven't worked out how to feed their results directly into SGSS. So (wait for it)...
All the pillar 2 results (basically most English test results these days) are sent in the form of a csv spreadsheet file to @PHE_UK. They then feed those results into an Excel template and from there it gets fed into the dashboard and, like those SGSS results, along to T&T
It’s worth dwelling on this for a moment before we get to the car crash moment. At the very apex of our key #COVID19 defence mechanism is a database setup that’s a bit like putting a car together with sellotape. It is so, so, so not how to manage big, crucial databases.
And this isn’t just a database. It’s a mechanism which is supposed to save people’s lives. The sooner someone who’s got #COVID19 is identified and their contacts traced, the more we can halt the spread of the infection. This is the WHOLE POINT. Data saves lives.
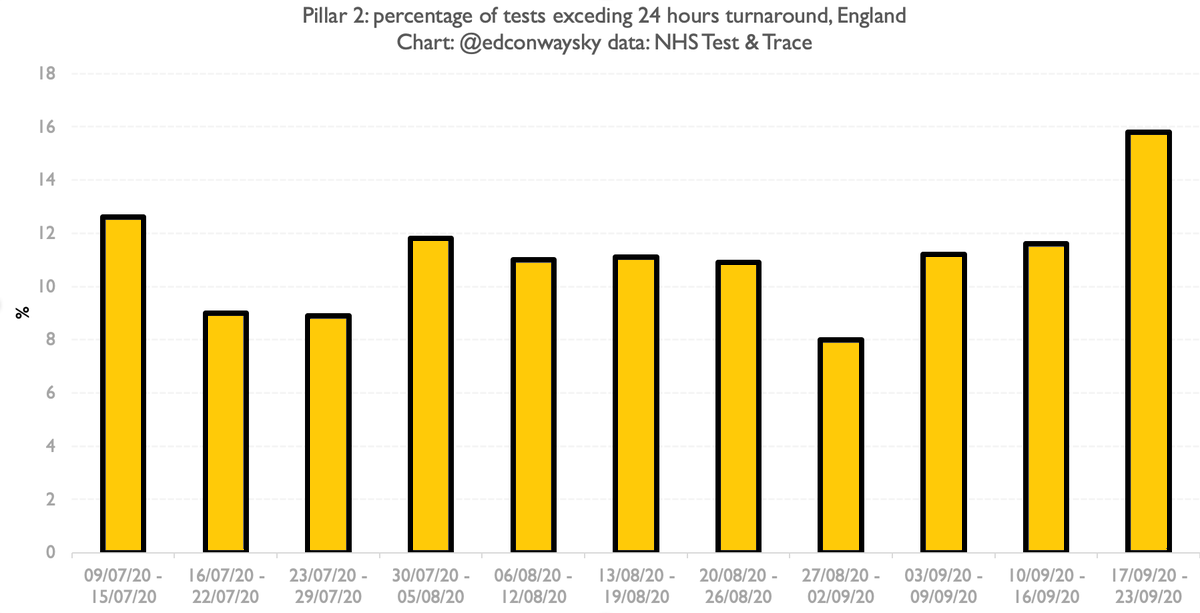
You may already know how this ends. It turns out old versions of Excel have a somewhat arbitrary and very well known limitation: the files can’t have any more than 65,536 rows in them. This is not the only reason people DO NOT USE EXCEL as a database, but it’s one of them.
It turns out the computer @PHE_UK was using to convert the CSVs into Excel and hence onwards into their dashboard/T&T was running an old version of Excel. Last Friday those monitoring the dashboard discovered it had run into that limit a week earlier.
There was, I’m told, sheer horror in the corridors of @PHE_UK in the following hours. They realised that as cases had mounted, so had the length of the CSVs coming in, and they were now well over 65,536 rows. So thousands of cases were simply not being ingested.
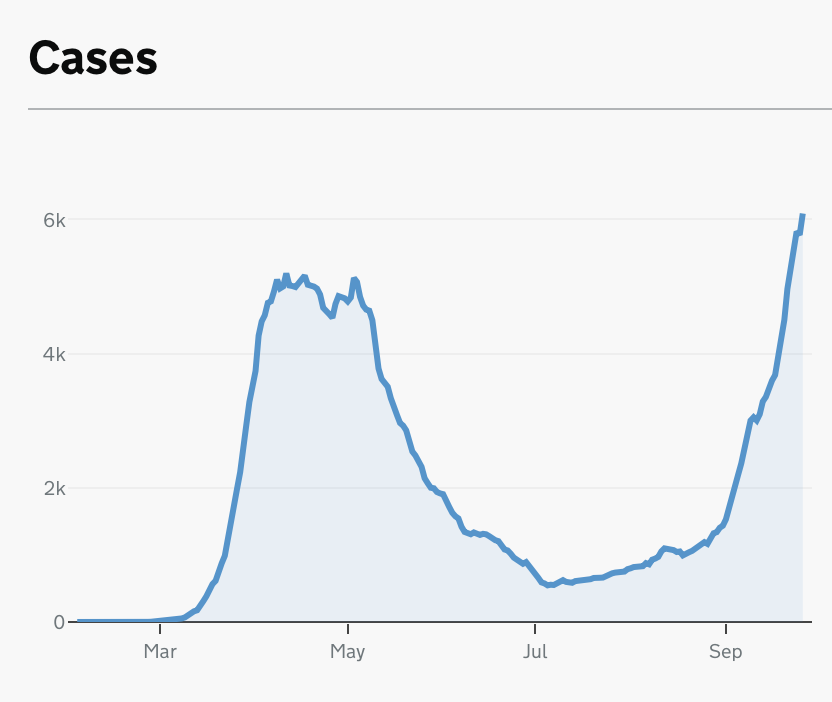
The upshot is around 16k cases were passed onto the contact tracers late. Around 12k were a few days late. Around 4k were as much as a week, perhaps a bit more, late. It seems highly likely people will have contracted #COVID19 as a result of this. Some may die.
The irony is if someone at @PHE_UK had simply upgraded Excel to the new version they would have upped their row limit to a million and we might never have had this catastrophe. Though, in case this wasn’t already obvious, Excel is NOT the program to use for this kind of thing.
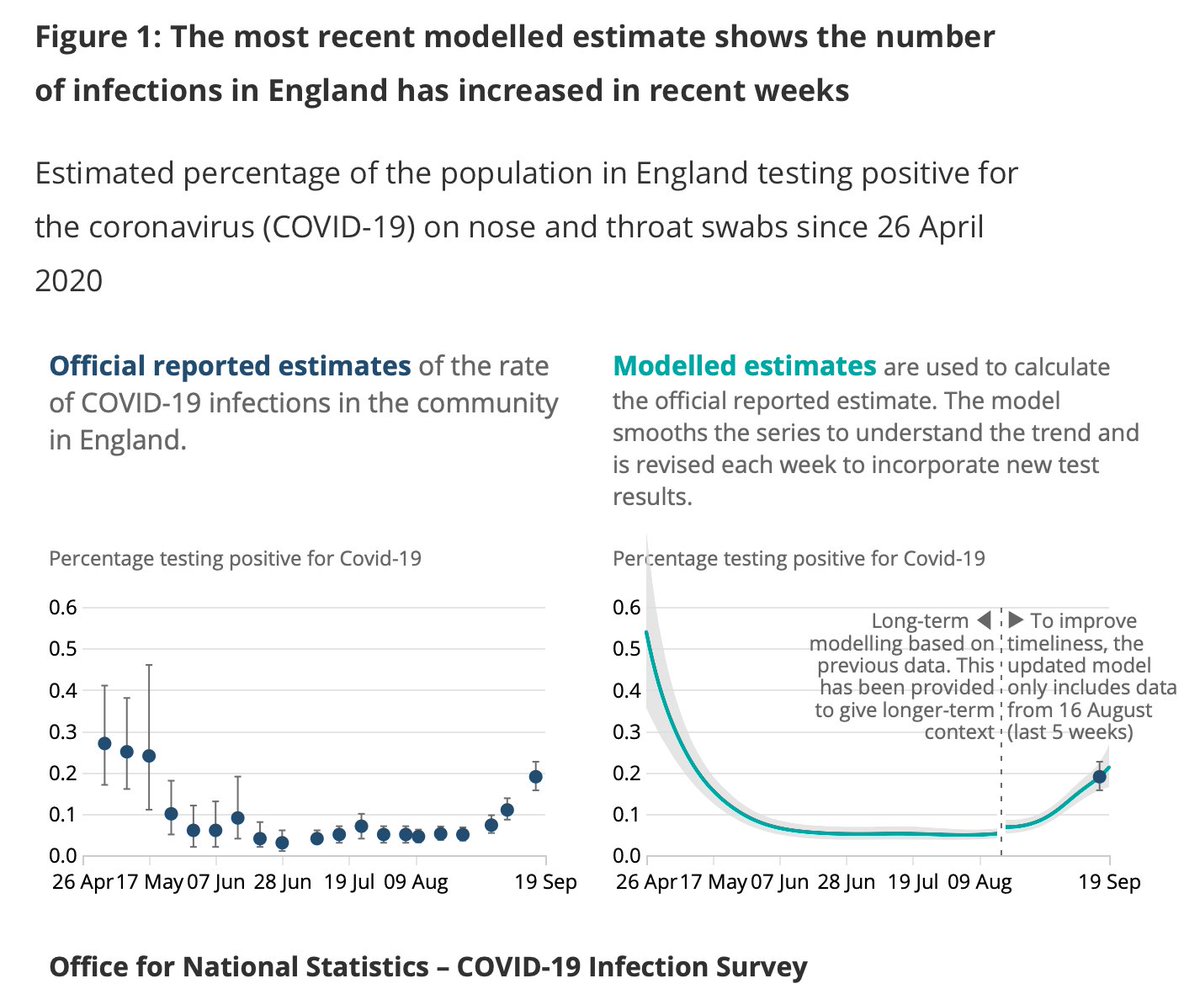
Now as I outlined last night, this might make some of the recent UK #COVID19 data look a bit scarier. But it prob doesn’t change the broader picture as depicted by the @ONS infection survey: it's spreading but prob not at the speed it was a few weeks ago.
https://twitter.com/EdConwaySky/status/1312873886808244224?s=20
The real worry is that we allowed so many cases to go untraced for such a long period. That might or might not change the disease's course. Let's hope not. Either way, some will prob get #COVID19 as a result. Some may die. And all due to hideous, elementary data mismanagement.
Back in July we revealed that data collection when it came to #COVID19 tests was so primitive that they were being collated with pen and paper.
Ironically that method would have been more robust than the Excel method that caused this latest data fiasco…
news.sky.com/story/coronavi…
Ironically that method would have been more robust than the Excel method that caused this latest data fiasco…
news.sky.com/story/coronavi…

For those who prefer their news in video form, here’s a short explainer on how on earth an obscure computer error somewhere in Whitehall meant that tens of thousands of people were unnecessarily exposed to #COVID19
• • •
Missing some Tweet in this thread? You can try to
force a refresh