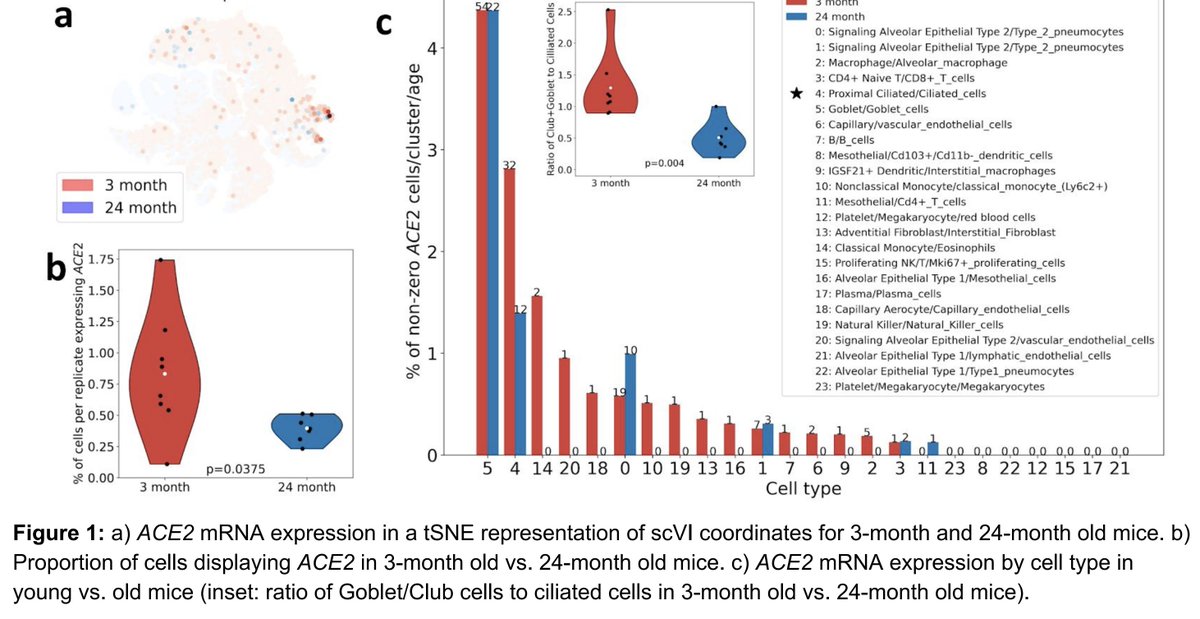
There are some difficult truths when it comes to publication modes and publication costs, and @rsidd120 makes some good points here.
His on-point thread reminded me of my black and white paper: 🧵
His on-point thread reminded me of my black and white paper: 🧵
https://twitter.com/rsidd120/status/1336152889895501833?s=20
In 2006 I went on a year-long sabbatical to @UniofOxford from @UCBerkeley. My grants were just ending and I thought I'd reset by doing some math after several years of genome consortia (I didn't have a biology mentor to tell me R01s can be renewed, so I didn't know & didn't try).
At @UniofOxford I was hosted by Philip Maini in Maths and @JotunHein in the Stats. It was a fun year in which I met @satijalab who was a student at the time. We ended up writing a paper on phylogenetics, alignment and annotation: academic.oup.com/bioinformatics…
With phylogenetics on my mind I invited one of my students at the time, Dan Levy (now a prof. @CSHL), to join me to work on a theoretical project related to NeighborNet. This ended up in a paper submitted in 2007 (published in 2011... math takes a while!) sciencedirect.com/science/articl…
This paper has all of its figures in black and white, and it really diminished its quality. Below you can see what one of the main figures looks like in the journal paper (in black and white, left) vs. in the arXiv (in color, right): 


Why was the paper in B&W? I had no grant money. While I had paid part of my salary when the project started from an NSF grant, it too had run out. Dan Levy was paid from a @BBSRC grant. And the @ElsevierConnect wanted an arm and a leg for color. I just didn't have the $$.
Even without color the article was not free, and it was hard to find the money for it. And what did @ElsevierConnect do with the $? They introduced errors in my work. For example Jotun Hein's name was spelled correct in the arXiv & submission, yet is misspelled in the journal. 🤦🏻♂️
In biology, well-funded PIs don't blink at outrageous publication charges that run into the thousands even without open access. It's a small tax to pay from large grants, and a "high-profile" paper pays off in future grant dividends.
In the case of "consortia", the publication charges are a drop in the bucket from budgets that run in tens or hundreds of millions of dollars, and the juicy "packages" they pay for are a win-win: multiple papers for authors and multiple citations for journals.
As @rsidd120 points out, it's not only scientists who earn less than $11,500 in a month that are hurt. The costs for open access publishing have become outlandish and arguments that amount to little more than haggling over the price miss the forest for the trees.
The point of telling my black and white paper story is that costs are real, and they lead to difficult choices for many. I've been privileged and lucky to have been well-funded my entire career, and my experience with the NeighborNet paper taught me to plan ahead more carefully.
But planning ahead with grants is impossible nowadays with funding frequently dipping into the single digits. So yeah- let's burn this publication system to the ground and follow the lead of our math colleagues (@wtgowers et al.) blog.scholasticahq.com/post/introduci…
• • •
Missing some Tweet in this thread? You can try to
force a refresh