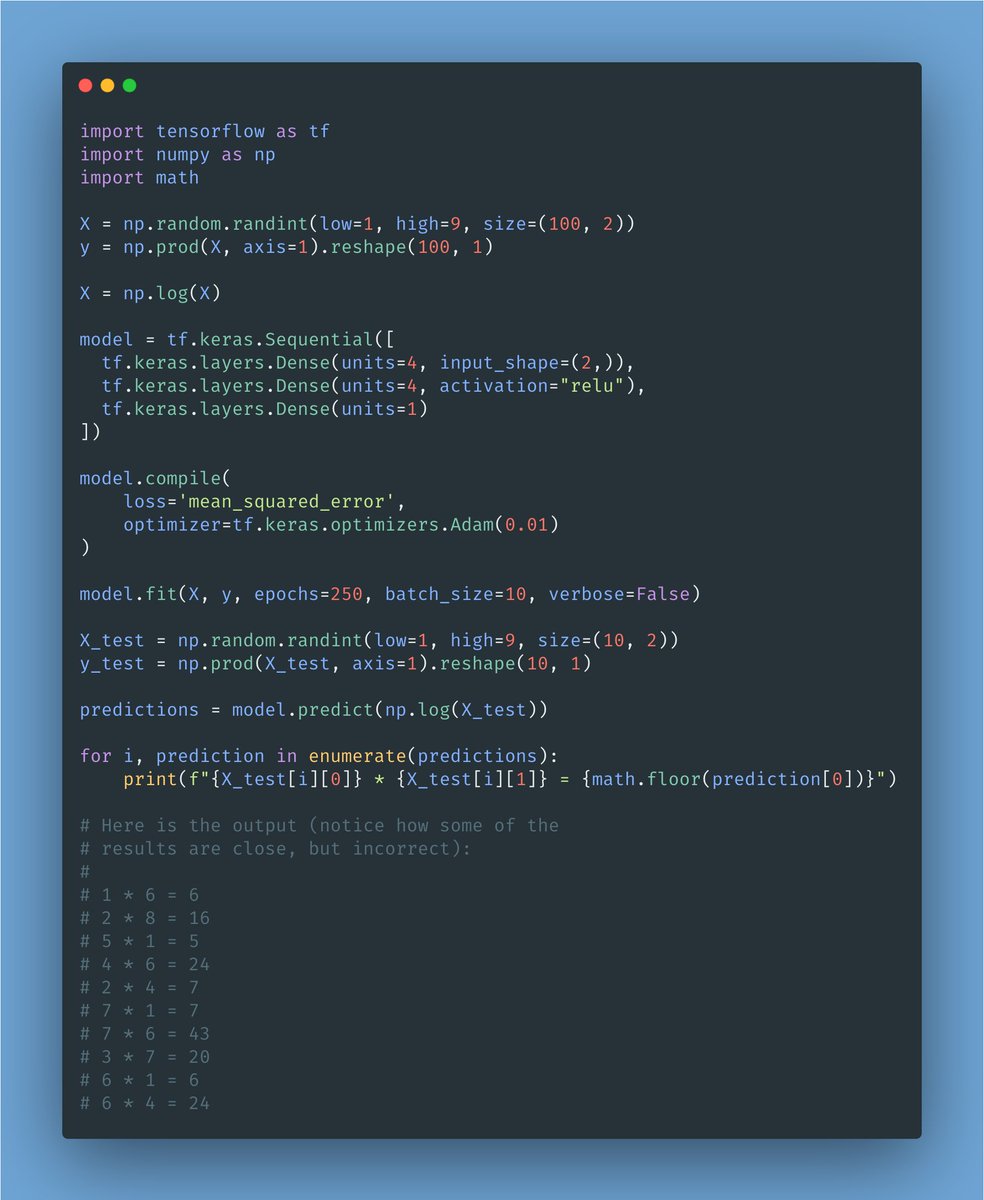
The one million dollar question:
"Is it reasonable for someone to dive into machine learning with a shallow knowledge of math?"
▫️ The short answer is "yes."
▫️ The more nuanced answer is "it depends."
Let me try and unpack this question for you.
🧵👇
"Is it reasonable for someone to dive into machine learning with a shallow knowledge of math?"
▫️ The short answer is "yes."
▫️ The more nuanced answer is "it depends."
Let me try and unpack this question for you.
🧵👇
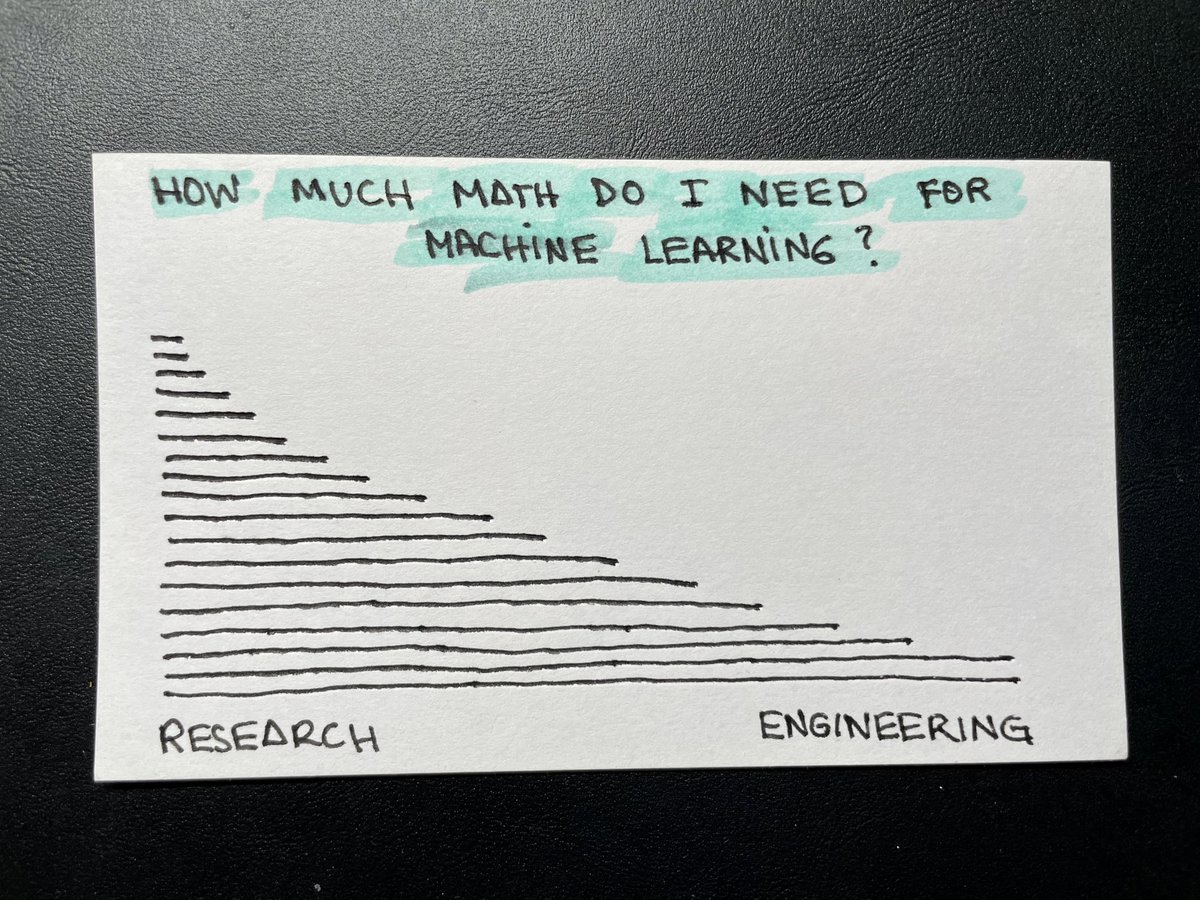
You can think about machine learning as a spectrum that goes all the way from pure research to engineering.
The more you move towards a research position, the more you can benefit from your math knowledge. If you move in the other direction, you'll get away with less of it.
👇
The more you move towards a research position, the more you can benefit from your math knowledge. If you move in the other direction, you'll get away with less of it.
👇
I have friends that got a Ph.D. and became college professors.
For them, math is an absolute requirement!
Not only are they working on research projects, but they are teaching the next generation of scientists and engineers.
👇
For them, math is an absolute requirement!
Not only are they working on research projects, but they are teaching the next generation of scientists and engineers.
👇
Other friends went the other direction: they took positions at companies that focus on exploiting existing high-level frameworks to produce value.
A lot of the math required is already abstracted away by these libraries. They can get away with much less knowledge.
👇
A lot of the math required is already abstracted away by these libraries. They can get away with much less knowledge.
👇
Notice that I didn't say that you don't need math *at all*. I specifically framed the initial question as having a "shallow knowledge" of it.
It's tough to escape from math, regardless of what you do in life. Machine learning is no exception.
👇
It's tough to escape from math, regardless of what you do in life. Machine learning is no exception.
👇
I'm an engineer. This is my experience:
▫️ Basic knowledge of statistics and probabilities is essential for what I do.
▫️ Understanding derivatives much less so.
▫️ Linear algebra comes up all the time, but it's easy to refresh concepts when I need them.
👇
▫️ Basic knowledge of statistics and probabilities is essential for what I do.
▫️ Understanding derivatives much less so.
▫️ Linear algebra comes up all the time, but it's easy to refresh concepts when I need them.
👇
I want you to keep this in mind:
▫️ You can get started with a much shallower knowledge of math than what would be required for a job.
Part of the process is to learn what you need!
This is probably the most relevant piece of advice that always gets lost in translation.
👇
▫️ You can get started with a much shallower knowledge of math than what would be required for a job.
Part of the process is to learn what you need!
This is probably the most relevant piece of advice that always gets lost in translation.
👇
If today is your first day getting on the machine learning train, I promise you can get away with basic high school level math.
In a year, you'll need more than that. But that will happen gradually.
👇
In a year, you'll need more than that. But that will happen gradually.
👇
Remember when you were learning to ride a bicycle?
If you look back and try to think logically about it, there are so many things you probably *wish* you knew before starting.
But you didn't.
And you learned.
And everything turned out okay.
👇
If you look back and try to think logically about it, there are so many things you probably *wish* you knew before starting.
But you didn't.
And you learned.
And everything turned out okay.
👇
Let's wrap up this with a TLDR;
▫️ You can get started with very little math.
▫️ As you progress, you'll incorporate more of it.
▫️ Your specialization will determine how much.
More important than anything:
GET. STARTED. Don't overthink it.
▫️ You can get started with very little math.
▫️ As you progress, you'll incorporate more of it.
▫️ Your specialization will determine how much.
More important than anything:
GET. STARTED. Don't overthink it.
I finish work every day around 5 pm. Then I come here to share some of the things I've learned.
Every day ☀️🌙
If you don't mind a blunt and practical point of view about machine learning and software engineering, stay tuned!
Every day ☀️🌙
If you don't mind a blunt and practical point of view about machine learning and software engineering, stay tuned!
• • •
Missing some Tweet in this thread? You can try to
force a refresh