
Since it is Day 10 of #31DaysofML it's perfect to discuss 1️⃣0️⃣ things that can go wrong with #MachineLearning Projects and what you can do about it!
I watched this amazing presentation by @kweinmeister that sums it all up
A 🧵
I watched this amazing presentation by @kweinmeister that sums it all up
A 🧵

@kweinmeister 1️⃣ You aren't solving the right problem
❓What's the goal of your ML model?
❓How do you assess if your model is "good" or "bad"?
❓What's your baseline?
👉 Focus on a long-term mission with maximum impact
👉 Ensure that your problem is a good fit for ML
#31DaysofML
❓What's the goal of your ML model?
❓How do you assess if your model is "good" or "bad"?
❓What's your baseline?
👉 Focus on a long-term mission with maximum impact
👉 Ensure that your problem is a good fit for ML
#31DaysofML
@kweinmeister 2️⃣ Jumping into development without a prototype
👉 ML project is an iterative process
👉 Start with simple model & continue to refine it until you've reached your goal
👉 Quick prototype can tell a lot about hidden requirements, implementation challenges, scope, etc
#31DaysofML
👉 ML project is an iterative process
👉 Start with simple model & continue to refine it until you've reached your goal
👉 Quick prototype can tell a lot about hidden requirements, implementation challenges, scope, etc
#31DaysofML
@kweinmeister 3️⃣ Model training can take a long time
👉 When your team is trying to rapidly iterate on new ideas and techniques, training time can slow down projects and get in the way of innovation.
👉 Use GPU's, TPUs to speed up training
👉 Use serverless training methods
#31DaysofML
👉 When your team is trying to rapidly iterate on new ideas and techniques, training time can slow down projects and get in the way of innovation.
👉 Use GPU's, TPUs to speed up training
👉 Use serverless training methods
#31DaysofML
@kweinmeister 4️⃣ You have an imbalanced dataset
❓ How can you balance accuracy across each class?
👉 Weighting each class
👉 Oversampling and undersampling
👉 Generating synthetic data
Here's a tutorial to checkout tensorflow.org/tutorials/stru…
#31DaysofML
❓ How can you balance accuracy across each class?
👉 Weighting each class
👉 Oversampling and undersampling
👉 Generating synthetic data
Here's a tutorial to checkout tensorflow.org/tutorials/stru…
#31DaysofML
@kweinmeister 5️⃣ Your model's accuracy is not good enough
👉 Include more varied training data
👉 Feature engineering
👉 Try different model architectures, hyper-parameter tuning & ensembles
👉 Remove features that may be causing overfitting, start with a smaller model & add features slowly
👉 Include more varied training data
👉 Feature engineering
👉 Try different model architectures, hyper-parameter tuning & ensembles
👉 Remove features that may be causing overfitting, start with a smaller model & add features slowly
@kweinmeister 6️⃣ Your model doesn't serve all of your users well
"Fairness is the process of understanding bias introduced by your data & ensuring your model provides equitable predictions across all demographic groups"
- @SRobTweets read more 👉 bit.ly/2Ly9wMM
#31DaysofML
"Fairness is the process of understanding bias introduced by your data & ensuring your model provides equitable predictions across all demographic groups"
- @SRobTweets read more 👉 bit.ly/2Ly9wMM
#31DaysofML
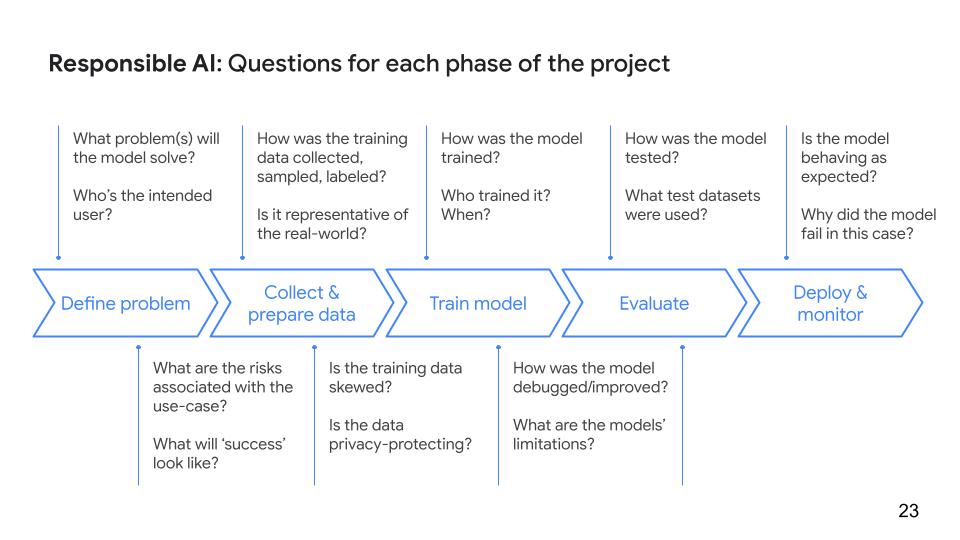
@kweinmeister @SRobTweets 7️⃣ It's unclear how your model works
👉 How will you be able to explain how your model makes predictions?
👉 Under what conditions does the model perform best and most consistently?
👉 Does it have blind spots? If so, where?
Read about Explainable AI 👉 bit.ly/3aFJdwx
👉 How will you be able to explain how your model makes predictions?
👉 Under what conditions does the model perform best and most consistently?
👉 Does it have blind spots? If so, where?
Read about Explainable AI 👉 bit.ly/3aFJdwx
@kweinmeister @SRobTweets 8️⃣ You could accidentally push a bad model into production
👉 Create ML pipeline to run same steps in same environment every time with a trigger/schedule
👉 Include steps - Data validation, Model evaluation, Conditional deployment
👉 Track pipeline runs & artifacts
#31DaysofML
👉 Create ML pipeline to run same steps in same environment every time with a trigger/schedule
👉 Include steps - Data validation, Model evaluation, Conditional deployment
👉 Track pipeline runs & artifacts
#31DaysofML

@kweinmeister @SRobTweets 1️⃣0️⃣ Model inference isn't scaling well in production
👉 Choose the right deployment tools that can scale
👉 Serve online endpoints for low-latency predictions, or predictions on massive batches of data
👉 Scale automatically based on your traffic
#31DaysofML
👉 Choose the right deployment tools that can scale
👉 Serve online endpoints for low-latency predictions, or predictions on massive batches of data
👉 Scale automatically based on your traffic
#31DaysofML
• • •
Missing some Tweet in this thread? You can try to
force a refresh







