Swin Transformer: New SOTA backbone for Computer Vision🔥
👉 What?
New vision Transformer architecture called Swin Transformer that can serve as a backbone in computer vision instead of CNNs.
📝 arxiv.org/abs/2103.14030
⚒ Code (soon) github.com/microsoft/Swin…
Thread 👇
👉 What?
New vision Transformer architecture called Swin Transformer that can serve as a backbone in computer vision instead of CNNs.
📝 arxiv.org/abs/2103.14030
⚒ Code (soon) github.com/microsoft/Swin…
Thread 👇
2/
❓Why?
There are two main problems with the usage of Transformers for computer vision.
1. Existing Transformer-based models have tokens of a fixed scale. However, in contrast to the word tokens, visual elements can be different in scale (e.g. objects of varying sizes in img)
❓Why?
There are two main problems with the usage of Transformers for computer vision.
1. Existing Transformer-based models have tokens of a fixed scale. However, in contrast to the word tokens, visual elements can be different in scale (e.g. objects of varying sizes in img)
3/
2. Regular self-attention requires quadratic of the image size number of operations, limiting applications in computer vision where high resolution is necessary (e.g., instance segmentation).
...
2. Regular self-attention requires quadratic of the image size number of operations, limiting applications in computer vision where high resolution is necessary (e.g., instance segmentation).
...
4/
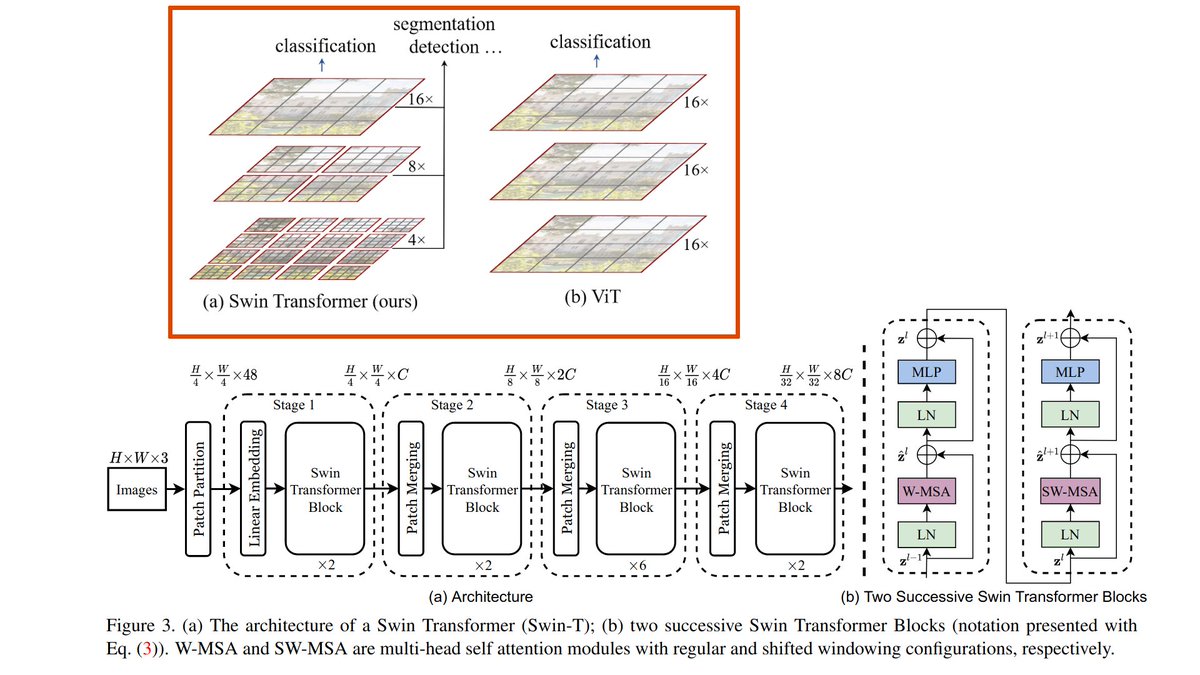
🥊 Main ideas of Swin Transformers:
1. Hierarchical feature maps where at each level of hierarchy Self-attention is applied within local non-overlapping windows. The size of the windows is progressively increased with the network depth (inspired by CNNs). ...
🥊 Main ideas of Swin Transformers:
1. Hierarchical feature maps where at each level of hierarchy Self-attention is applied within local non-overlapping windows. The size of the windows is progressively increased with the network depth (inspired by CNNs). ...
5/
...This enables building architectures similar to feature pyramid networks (FPN) or U-Net for dense pixel-level tasks.
2. Window-based Self-attention reduces the computational overhead.
...This enables building architectures similar to feature pyramid networks (FPN) or U-Net for dense pixel-level tasks.
2. Window-based Self-attention reduces the computational overhead.
6/
⚙️ Overall Architecture consists of repeating the following blocks:
- Split RGB image into non-overlapping patches (tokens).
- Apply MLP to translate raw features into an arbitrary dimension.
- Apply 2 consecutive Swin Transformer blocks with Window self-attention: both ...
⚙️ Overall Architecture consists of repeating the following blocks:
- Split RGB image into non-overlapping patches (tokens).
- Apply MLP to translate raw features into an arbitrary dimension.
- Apply 2 consecutive Swin Transformer blocks with Window self-attention: both ...
7/..blocks have the same window size, but the second block uses shifted by patch_size/2 windows which allows information flow between non-overlapping windows
- Downsampling layer: Reduce the number of tokens by merging neighboring patches in a 2x2 window, and double feature depth
- Downsampling layer: Reduce the number of tokens by merging neighboring patches in a 2x2 window, and double feature depth

8/
🦾 Results
+ Outperforms SOTA by a significant margin on COCO segmentation and detection tasks and ADE20K segmentation.
+ Comparable accuracy to the EfficientNet family on ImageNet-1K classification, while being faster.
🦾 Results
+ Outperforms SOTA by a significant margin on COCO segmentation and detection tasks and ADE20K segmentation.
+ Comparable accuracy to the EfficientNet family on ImageNet-1K classification, while being faster.

👌Conclusion
While Transformers are super flexible, researchers start to inject in Transformers inductive biases similar to those in CNNs, e.g., local connectivity, feature hierarchies. And this seems to help tremendously!
That's it!
While Transformers are super flexible, researchers start to inject in Transformers inductive biases similar to those in CNNs, e.g., local connectivity, feature hierarchies. And this seems to help tremendously!
That's it!
👉 Join my Telegram channel "Gradient Dude" not to miss the latest posts like this! t.me/gradientdude
• • •
Missing some Tweet in this thread? You can try to
force a refresh