Eine kleine Anekdote zum Thema Software schneller machen - also Laufzeitoptimierung. Für meine Covid- risikotabelle.de habe ich im letzen Jahr begonnen, Python datatable zu benutzen, um die RKI-Datendumps auszuwerten.
Datatables ist eine Library für Python, deren Kern in C++ geschrieben ist und die unglaublich schnell riesige Tabellen aus .csv lesen und schreiben und darauf sehr schnell rechnen kann, mit Python-Ausdrücken, die in Pseudocode für den C++-Kern umgewandelt werden, der außerdem...
...noch schlaue Dinge macht, um weniger rechnen zu müssen. Kann man sich hier im Detail anschauen github.com/h2oai/datatable
Nun sind mir aber zwei Probleme entstanden: Zum einen ist die Datenmenge explodiert. So wächst die täglich *neue* Datenmenge um fast so viele Zeilen, ...
Nun sind mir aber zwei Probleme entstanden: Zum einen ist die Datenmenge explodiert. So wächst die täglich *neue* Datenmenge um fast so viele Zeilen, ...
....wie es neue Fälle gibt. Jede neue Dump enthält also die Daten aller Fälle seit Anfang der Pandemie plus die neuen Fälle, heute 1.562.198 Zeilen oder 268MB als .csv, und alle dumps seit April sind zusammen 188.703.395 Zeilen oder 44GB im .jay Format.
Und ein paar Dutzend Spalten. Ist eine ganz schön lange Tabelle. Aus diesen ganzen Falldaten will ich nun Zeitreihen herausrechnen, also wie viele Fälle an welchem Tag in welchem Landkreis aufgetreten sind, wie viele gestorben sind, und all das nach Geschlecht und Alter...
...und Kalenderdaten aufgeschlüsselt, aber auch nach Bundesländern und für das ganze Land. Es kommen noch kleine Komplikationen in Form von Flags dazu, aber im Prinzip muss man die Liste der Fälle durchgehen und jeweils nur die Zählen, die einer bestimmten Kombination an...
...Filterkriterien entspricht, und so hatte ich das auch programmiert, wobei ich mir mit einer Operation auf der Tabelle eine komplette Spalte nach Tagen für eine Region in weniger als einer Sekunde ausrechnen konnte, und 1 Bundesrepublik, 16 Länder und 408 Kreise macht ...
...425 Regionen, also 425 Tabellen, jede mit ~30 Spalten und ein paar hundert Zeilen, für jeden Tag Pandemie eine - das ist das gewünschte Ergebnis, und es dauerte nur einige Sekunden, um aus den vielen GB Daten so eine Tabelle mit Zeitreihen für eine Region zu berechnen.
Also nicht wirklich ein Problem, das einmal am Tag zehn oder zwanzig Minuten laufen zu lassen und die 425 Tabellen komplett neu zu generieren, wenn die täglichen neuen Daten kommen, und kein Grund, allzu viel Zeit aufs Optimieren zu verwenden.
Das war im Herbst vor der zweiten Welle. Seitdem ist einiges passiert: Zum einen hat das die Datenmenge auf 44GB anwachsen lassen, auf ein Vielfaches von dem, als ich angefangen hatte, und zum anderen sind Wünsche dazugekommen, und vor allem ...
...die Auswertung nach Geschlechtern und Altersgruppen und Melde- und Publikationsdaten, alles jeweils neu und kumuliert, hat dazu geführt, dass ein voller Durchlauf mit allen Optionen über 50 Stunden gedauert hat.
Hauptgrund war, das 6 Altersgruppen für sich, dann getrennt nach Geschlecht, und dann die Geschlechter für sich im Endeffekt 20 mal so viele Spalten braucht wie alles zusammen, und die angewachsene Datenmenge und Features taten den Rest.
Das war natürlich eine unhaltbare Situation. Ein paar Stunden, ja, aber wenn die Daten um 3 Uhr nachts da sind, sollten sie früh morgens in der risikotabelle.de sein. Als naheliegenden, schnellen Optimierungsansatz habe eine "inkrementelle" Option eingebaut, wo sich...
...das Programm die Tabellen von Gestern anschaut, die fehlenden Tage bzw. Zeilen ermittelt und dann nur die "fehlenden" Zeilen berechnet und dafür den Großteil der "alten" Daten gar nicht berücksichtigen muss, und statt Daten für hunderte von Tagen auszurechnen nur einen Tag..
...in jeder Spalte hinzuzufügen. Das war etwas komplizierter, weil es auch Spalten gibt, die sich täglich komplett ändern können, nämlich die nach Meldedatum, aber hat es geklappt, und der Geschwindigkeitszuwachs war dramatisch, Faktor 10-50, so dass das es praktikabel wurde ...
...mit unter einer Stunde für den kleinen und ein paar Stunden für großen den Lauf mit Altersgruppen und Geschlechtern. Mit inkrementellem Betrieb hatte ich nun einige Wochen lang den "kleinen" Datensatz für die Risikotabelle jeden Tag aktualisiert, aber es blieben 2 Probleme:
Zum einen ist es etwas innovationshemmend, wenn man Änderungen macht, die ein Neugenerieren der gesamten Datenbasis erfordern und man dann 40, 50 Stunden aufs Ergebnis warten muss, und dann nach 30 Stunden vielleicht der Lauf auch noch abbricht, und man mit "checkpoints" ...
...arbeiten muss, also Zwischenergebnisse speichern, spätestens dann ist man in einer Situation, in der man nicht sein möchte und die effektiv dazu führte, dass ich keinen Regelbetrieb mit Altersgruppen für die risikotabelle.de gewagt habe; zu groß das Risiko, das...
...was schief geht und ich wieder unter Druck bin, das schnell zu fixen, aber mich mit 40h+ Laufzeiten konfrontiert sehen. Also hab ich mich noch mal hingesetzt und überlegt, wie das schneller gehen könnte.
Ganz Deutschland ging ja recht fix, und die 16 Bundesländer dauerten nur 16 mal so lange, aber die über 400 Landkreise dauerten extrem lange. Ohne Landkreise zu rechnen kam für mich nicht in Frage. Die Idee, die ich dann umgesetzt habe, kommt mir im Nachhinein so banal ...
... vor, dass ich mich fast dafür schäme, es nicht gleich so gemacht zu haben, aber am Anfang gab es für mich halt keinen Anlass, über Optimierungen nachzudenken, denn das steigert meist die Komplexität und braucht oft mehr Entwicklungszeit, und oft lohnt es einfach nicht.
Ok, was habe ich gemacht: Mir fiel auf, dass ja, wenn ich am Anfang ganz Deutschland rechne, sämtliche Daten "angefasst" werden, und alle Landkreise zusammen nicht so viel länger brauchen dürften, weil es Ende nicht wesentlich mehr Rechenoperationen sein dürften.
Ich habe dann in meine Abfragen, die die Spalten für eine Region generieren, einfach alle Zahlen für alle Regionen und alle Tage in einer Abfrage errechnet und das Ergebnis verteilt. Eigentlich trivial, aber dazu musste ich die datatables dazu bringen, "join on multiple keys"...
...zu machen, was nicht vorgesehen ist, aber in SQL völlig normal und auch da Datenbankoperationen (aus völlig anderen Gründen) beschleunigen kann. Es war aber auch mit datatables machbar, mit zusammengesetzten Hilfsschlüsseln, und das Ergebnis sehr erfreulich:
Statt 425 mussten nur 3 Operationen durchgeführt werden, Deutschland, Länder, Kreise, wodurch ein Komplettdurchlauf rund 100x schneller wurde, was mir meine alte Version schlagartig peinlich langsam erscheinen ließ. Aber die Pointe kommt noch, falls ihr sich nicht schon ahnt:
Ich konnte jetzt alles komplett mit Altersgruppen in ~22 Minuten statt 40+ Stunden rechnen, aber erinnert ihr euch noch an den inkrementellen Modus? Der ist völlig orthogonal zum neuen Ansatz, also in Kombination nutzbar. Habe gerade so einen Kombinationslauf gemacht: 
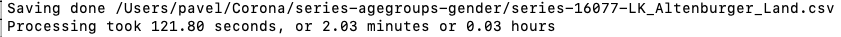
Was mit der ersten Version über 40 Stunden gebraucht hat, nämlich, die Tabelle zu aktualisieren, läuft jetzt in nur 2 Minuten durch. Das ist über 1000 mal schneller. Und mir fast peinlich, weil ich immer auf Laufzeit achte und ich selten überrascht war vom Optimierungsergebnis.
So langsam erschien mir meine alte Software angesichts der Datenmengen gar nicht, und am Anfang war sie es auch nicht, aber jetzt finde ich die alte Variante peinlich langsam und die neue peinlich schnell.
• • •
Missing some Tweet in this thread? You can try to
force a refresh