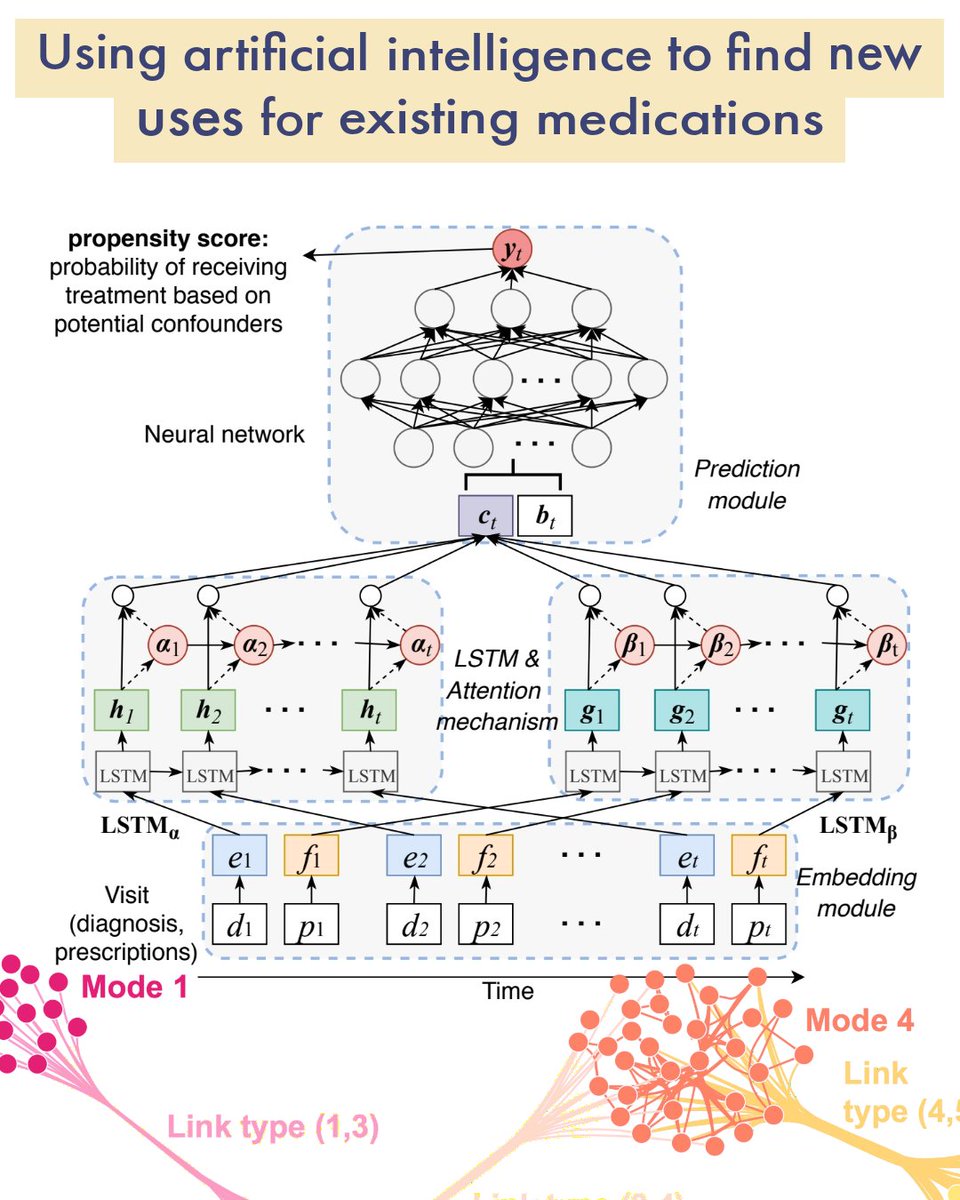
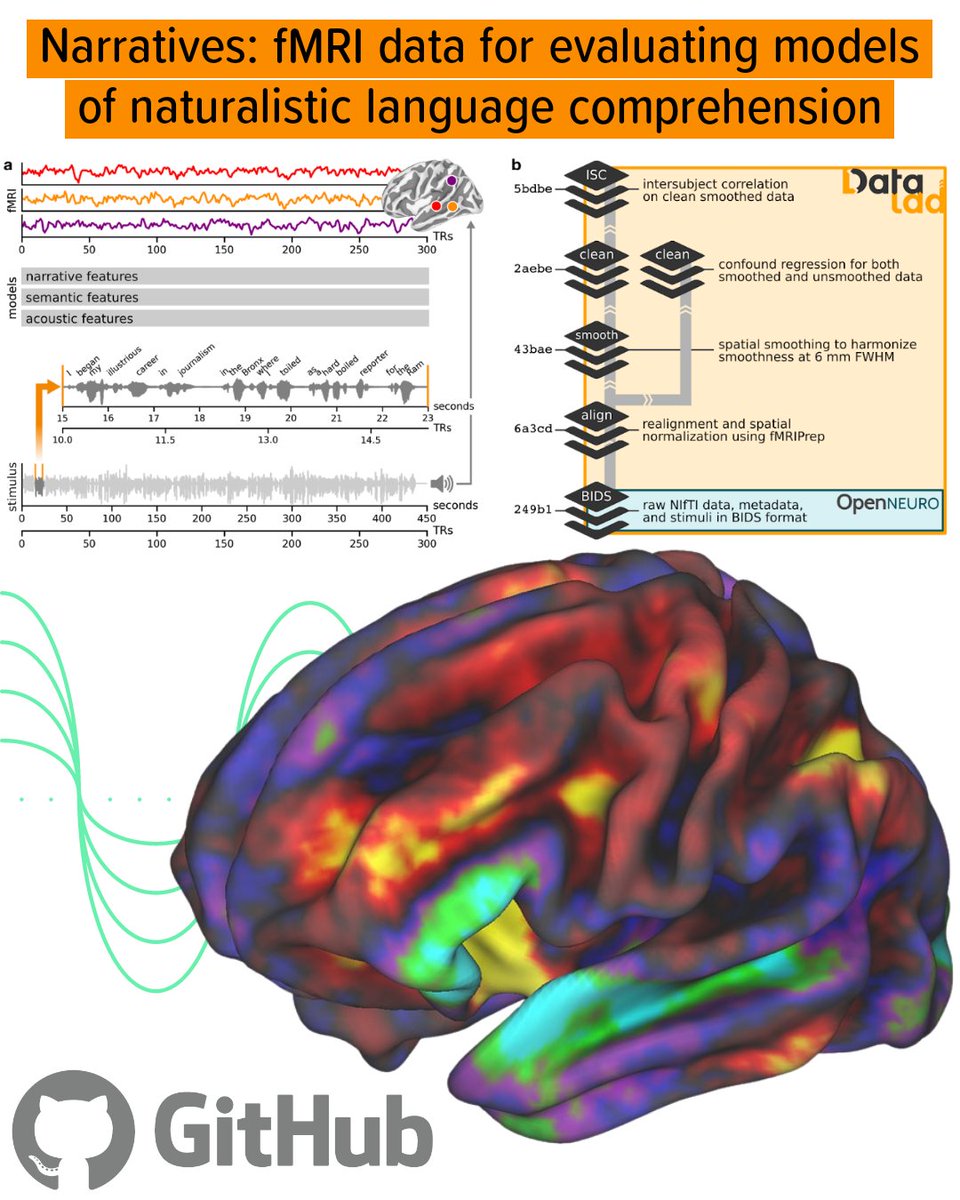
Machine learning from development into production as a team
What about
• Dependencies?
• Reproducibility?
• Continuous integration?
Save the hustle with these simple practices
↓ 1/6
What about
• Dependencies?
• Reproducibility?
• Continuous integration?
Save the hustle with these simple practices
↓ 1/6
Usually you start with a Jupyter notebook to make them robust especially working as a team nbdev is a life saver
GitHub github.com/fastai/nbdevq
↓ 2/6
GitHub github.com/fastai/nbdevq
↓ 2/6
nbdev is a library that allows you to develop a python library in Jupyter Notebooks, putting all your code, tests and documentation in one place. That is: you now have a true literate programming environment, as envisioned by Donald Knuth back in 1983!
↓ 3/6
↓ 3/6
When multiple people work on the project dependencies and reproducibility can become a nightmare. Docker to the rescue!
Docker for Data Science — A Step by Step Guide
towardsdatascience.com/docker-for-dat…
With Docker, you have your ready-made environment at your fingertips.
↓ 4/6
Docker for Data Science — A Step by Step Guide
towardsdatascience.com/docker-for-dat…
With Docker, you have your ready-made environment at your fingertips.
↓ 4/6
Now you have multiple versions of your machine learning model? Also different Configs? How to track?
MLflow github.com/mlflow/mlflow an open source platform for the machine learning lifecycle
@MLflow
↓ 4/6
MLflow github.com/mlflow/mlflow an open source platform for the machine learning lifecycle
@MLflow
↓ 4/6
Use MLflow for tracking your various models, experiments, results and config
Btw. if it is pure ML pipeline approach its also possible to do everything directly in MLflow and skip the Docker step
↓ 5/6
Btw. if it is pure ML pipeline approach its also possible to do everything directly in MLflow and skip the Docker step
↓ 5/6
So how to bring your ML model into production, why not as a micro service with FastAPI?
Step by step guide towardsdatascience.com/how-to-deploy-…
@tiangolo
6/6
Step by step guide towardsdatascience.com/how-to-deploy-…
@tiangolo
6/6
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh