
Yakin pemain bola favorit kamu ga under/over value?⚽️🏃
Tentuiin market valuenya pakai machine learning yuk!
.
.
.
A thread
Tentuiin market valuenya pakai machine learning yuk!
.
.
.
A thread
Malem ini pada malmingan apa nontonin Euroo nihh?
Yang ngikutin Euro, mimin penasaran dehh, siapa sih pemain sepak bola favoritmu main di Euro? Kalo mimin sih ngefans banget sama duet pogba-kante di lini tengahnya perancis. Asli cakep banget mainnya hahaha
Tapi nih guyss, kalian tau ga sii kira kira berapa ya market valuenya setelah Euro nantii? Buat yang suka bola, setelah ajang kompetisi selesai pasti selalu nungguin kabar bursa transfer kan?
Dengan harapan tim favoritnya beli pemain bagus supaya performa musim depan lebih bagus lagi. Setiap tahun, sejumlah besar uang diinvestasikan oleh klub sepak bola pada bursa transfer untuk jual beli pemain. Ini juga yang jadi aspek menarik dari sepak bola untuk para fans.
Tapi kadang ada aja kan klub yang salah beli pemain. Udah beli mahal-mahal, eh performanya ga sesuai harapan. Sedangkan ada klub lain yang beli pemain murah atau bahkan free transfer ternyata bisa berkembang cepat dan bagus performanya.
Pastinya kita gamau dong salah beli pemainn. Nah, gimana caranya supaya ga salah beli? 🧐
Salah satunya dengan menentukan berapa market value yang paling tepat untuk seorang pemain. Manajer klub punya tugas penting untuk memperkirakan value pemain.
Dengan mengetahui market value pemain, kita bisa tau kalo klub yang jual mahal pemainnya, apakah harganya masih wajar atau udah ketinggian. Klub juga bisa liat pemain mana yang potensial tapi harganya masih terlalu murah.
Gimana caranya tau harga pasar pemain? Buat kita yang hanya penikmat bola, sejauh ini ada situs transfermarkt.com yang sering jadi patokan. Tapi apakah bisa dipercaya?🤔 

Penentuan market value pemain di transfermarkt.com itu menggunakan crowd estimate, maksudnya estimasi yang diberikan berasal dari diskusi dan perkiraan member situs tersebut dalam menilai value pemain.
Jelass, cara ini punya batasan dan kelemahan. Member yang kurang berpengalaman bisa mengurangi akurasi estimasi. Selain itu, sangat mungkin ada bias pada pemain dari klub, liga, atau negara tertentu karena nilainya ditentukan dari opini orang-orang.
Mungkin hasilnya bisa bagus untuk pemain terkenal, tapi untuk pemain yang tidak main di kompetisi atau klub terkenal bisa kurang akurat. Ini kurang efektif untuk mendeteksi ‘hidden gem’. Datanya juga kurang sering diupdate karena harus mengumpulkan opini orang dulu.
Padahal, kadang market value pemain bisa berubah sangat cepat karena performa di kompetisi tertentu, kaya Euro yang sekarang lagi berjalan ini nihh.
Makanyaa, biar kita ga kehilangan ‘hidden gem’ ini, kita bisa prediksi value market pemain pakai machine learning. Kali ini, mimin akan coba untuk bahas sedikit tentang topik inii.
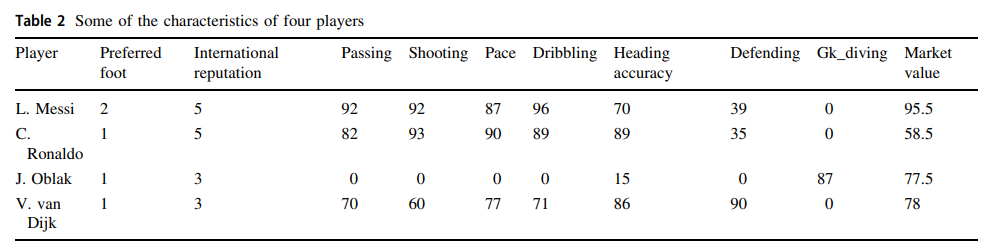
Data yang digunakan untuk membuat model kita di thread kali ini adalah data pemain dari game FIFA yang terus diupdate. Kalian bisa cek apa aja data yang dipakai di tabel ini nih:

Sebenarnya data ini masih bisa diperdebatkan karena sebagian orang kurang setuju dengan penilaian skill pemain di game FIFA, tapi sejauh ini data game FIFA adalah salah satu data terbaik yang membahas skill pemain bola.
Model pertama yang digunakan adalah Particle Swarm Optimization (PSO). Konsep model PSO adalah menemukan solusi titik optimum fungsi objektif menggunakan populasi individu, yang disebut partikel.
Awalnya, partikel dihasilkan secara acak. Kemudian, nilai kecocokannya dihitung menggunakan fungsi objektif. Setelah mendapat partikel terbaik sebagai ‘leader’, partikel mulai bergerak di ruang solusi. Ini gambaran flowchart dari proses pada metode PSO.

Model PSO tadi akan digunakan untuk memilih fitur terbaik dari data yang nantinya akan digunakan dalam model berikutnya, yaitu Support Vector Regression.
Model selanjutnya yang digunakan adalah Automatic PSO clustering (APSO-clustering). APSO-clustering adalah metode pengelompokan otomatis yang dapat menemukan jumlah cluster yang tepat serta posisi centroid.
Kelebihan utama dari metode ini adalah akurasinya yang tinggi dalam mempartisi kumpulan data yang kompleks dan besar dibandingkan dengan metode pengelompokan otomatis lainnya seperti k-means.
Metode pengelompokan ini bekerja pada dua fase. Fase pertama: menemukan jumlah cluster yang sesuai. Fase kedua: mendeteksi posisi centroid yang tepat.

Model selanjutnya yang digunakan adalah Particle Swarm Optimization - Support Vector Regression (PSO-SVR). Karena pemain memiliki skill berbeda berdasarkan posisi, market value pemain harus diperkirakan berdasarkan posisi dan skill yang sesuai dengan posisi.
PSO digunakan untuk menemukan fitur terbaik dan mendeteksi nilai kernel Gaussian yang tepat. Kemudian, SVR dilatih dengan kernel Gaussian dan nilai parameter yang sesuai serta training data berisi fitur yang dipilih untuk memberikan prediksi.

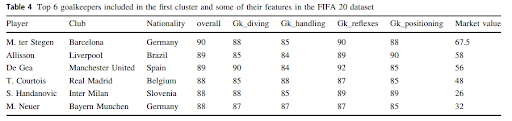
Cluster pertama terdeteksi dengan APSO-clustering adalah goalkeeper. Selanjutnya metode PSO digunakan untuk menemukan fitur terbaik menghilangkan fitur yang berlebihan selain menemukan nilai optimal untuk parameter kernel Gaussian.

Metode APSO-clustering menempatkan striker di klaster kedua. Selanjutnya digunakan metode PSO untuk menentukan fitur terpenting untuk striker.


Klaster ketiga yang dihasilkan oleh APSO-clustering adalah defender. Berikut adalah beberapa fitur terbaik defender yang dipilih oleh PSO.


Midfielder adalah cluster keempat yang dihasilkan dari APSO-clustering. Berikut adalah beberapa fitur yang dipilih dari PSO.


Setelah mengetahui 4 klaster dan fitur terpentingnya dari PSO, digunakan Support Vector Regression untuk mendapatkan perkiraan market value-nya. Data pada training dataset dibagi menjadi 4 klaster lalu diprediksi market value-nya sesuai fitur penting setiap klaster.

Penentuan value dengan SVR dari metode ini juga bisa dipakai bersama 3 model metaheuristik lainnya (GWO, IPO, dan WOA) dan ternyata PSO masih yang terbaik. Ini hasil perbandingan 4 metode (PSO-SVR, GWO-SVR, IPO-SVR, dan WOA-SVR) diukur dengan 5 metrik evaluasi berbeda.

Koefisien determinasi (R2) untuk PSO-SVR adalah 0,74 yang berarti akurasi dari PSO-SVR sekitar 74%. Artinya model ini udah cukup baik nih untuk prediksi market value pemain. Dengan menerapkan model ini, klub bisa lebih hati-hati nih buat memilih pemain yang mau dibeli.
Hal yang cukup penting dalam membuat prediksi market value pemain adalah menemukan dataset yang cukup lengkap berisi karakteristik dan skill pemain. Kenapa gituu?
Yaaa, garbage in garbage out guys🤪🤪 Dalam statistik dan machine learning, mau modelnya sebagus apapun kalau datanya jelek, hasilnya akan tetap jelek.
Kira kira gitu guyss penjelasan singkat cara nentuiin market value pemain bola menggunakan machine learning. Keren juga sih, kegunaan machine learning bisa sampai buat hal kaya gini.
Gimana, kalian tertarik untuk jadi Data Scientist di industri olahraga? Bisa banget nih belajar dasar nya dulu di non degree program Data Scientist / Business Intelligence Pacmann.AI! Kepoiin kelasnya lebih lanjut di bit.ly/PacmannioTwitt… yaa!

Referensi:
link.springer.com/article/10.100…
link.springer.com/article/10.100…
• • •
Missing some Tweet in this thread? You can try to
force a refresh





