
An "RL" take on compression: "super-lossy" compression that changes the image, but preserves its downstream effect (i.e., the user should take the same action seeing the "compressed" image as when they saw original) sites.google.com/view/pragmatic…
w @sidgreddy & @ancadianadragan
🧵>
w @sidgreddy & @ancadianadragan
🧵>

The idea is pretty simple: we use a GAN-style loss to classify whether the user would have taken the same downstream action upon seeing the compressed image or not. Action could mean button press when playing a video game, or a click/decision for a website.
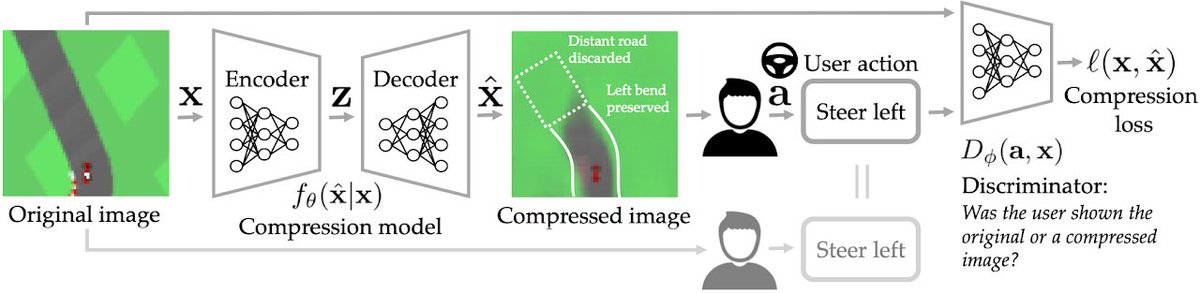
The compression itself is done with a generative latent variable model (we use styleGAN, but VAEs would work great too, as well as flows). PICO basically decides to throw out those bits that it determines (via its GAN loss) won't change the user's downstream decision.
This is obviously a proof of concept, and we crank up the compression factor way too high. See below for example: if the user's downstream goal is to check if a person is wearing glasses, eventually PICO scrambles *everything* else, including their gender, but keep the glasses!

While this sort of "pragmatic compression" is in its infancy, I think it could be tremendously valuable in the future: it's easy to do the A/B testing necessary to train the discriminator, and PICO does not need knowledge of the downstream task, just which action users took.
Website: sites.google.com/view/pragmatic…
Paper: siddharth.io/files/pico.pdf
Talk video:
(the paper is currently held up for moderation on arxiv, we'll post the arxiv link as soon as that goes through... its been stuck for several weeks)
Paper: siddharth.io/files/pico.pdf
Talk video:
(the paper is currently held up for moderation on arxiv, we'll post the arxiv link as soon as that goes through... its been stuck for several weeks)
• • •
Missing some Tweet in this thread? You can try to
force a refresh








