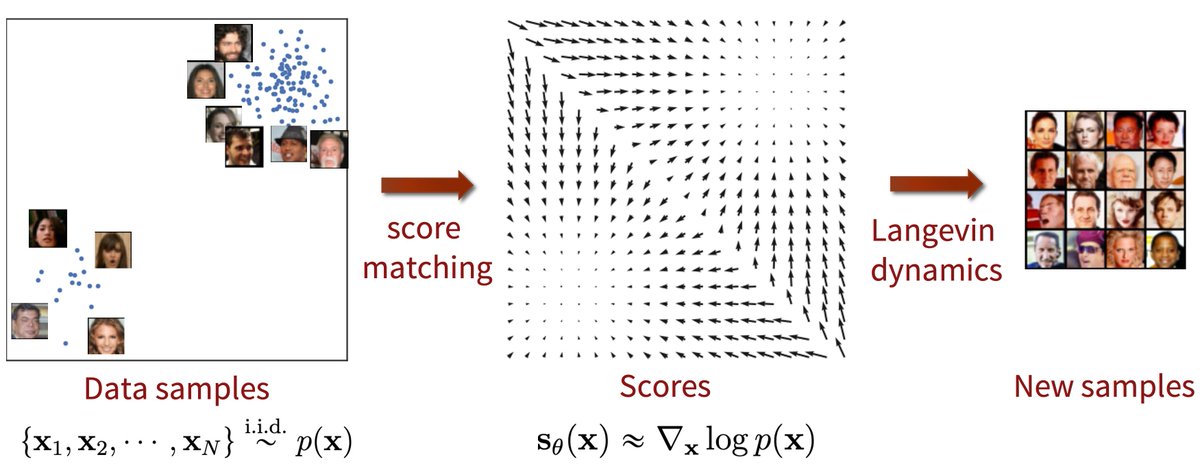
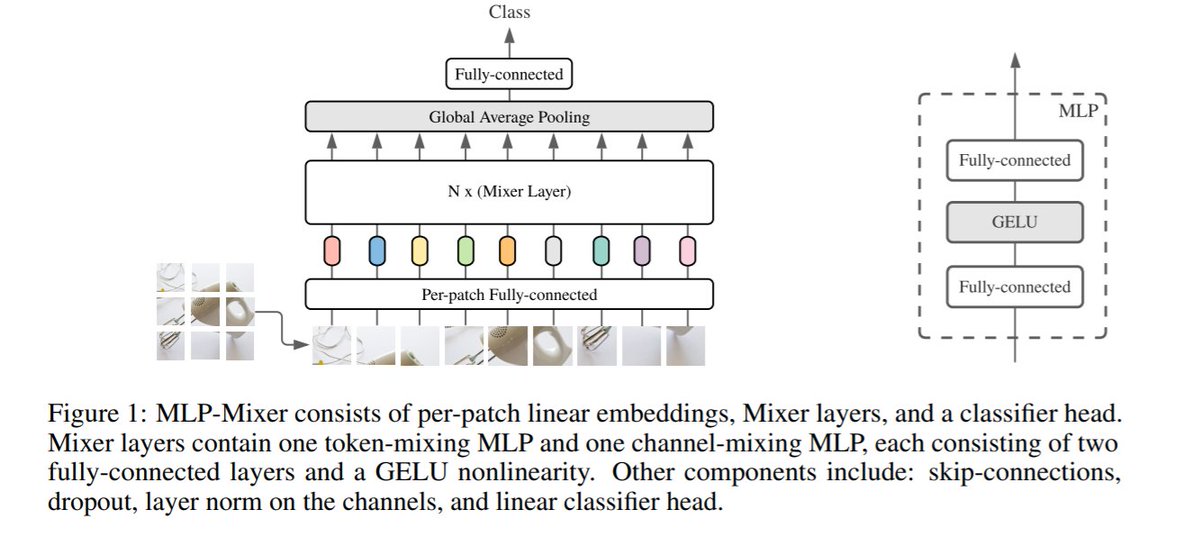
*Reproducible deep learning*: Time for exams!
To a practical course, a practical exam: I asked each student to include a new branch in the repository showcasing additional tools and libraries.
The result? *Everyone* loves some hyper-parameter optimization. 😄
/n
To a practical course, a practical exam: I asked each student to include a new branch in the repository showcasing additional tools and libraries.
The result? *Everyone* loves some hyper-parameter optimization. 😄
/n

Thanks to their work, you'll find practical examples of fine-tuning parameters using @OptunaAutoML, AX (from @facebookai), @raydistributed Tune, and Auto-PyTorch and Talos coming soon.
So many ideas for next year! 😛
github.com/sscardapane/re…
/n
So many ideas for next year! 😛
github.com/sscardapane/re…
/n
You will also find additional exercises on:
- Serving the model with TorchServe;
- Managing experiments with @DVCorg 2.0;
- Set up cron jobs for re-training.
BTW, if you'd like to add something, feel free to contact me or open a pull request. 🙂
github.com/sscardapane/re…
/n
- Serving the model with TorchServe;
- Managing experiments with @DVCorg 2.0;
- Set up cron jobs for re-training.
BTW, if you'd like to add something, feel free to contact me or open a pull request. 🙂
github.com/sscardapane/re…
/n
As for me, it's time for some holidays. Next year: a completely revamped edition of my Neural Networks class (open-source, of course)! 🥳
• • •
Missing some Tweet in this thread? You can try to
force a refresh