
Quick Tweet Storm ⛈
How does AI bounding box detection work?
🧠 Learn in 30 seconds
#100DaysOfCode #CodeNewbie #MadeWithTFJS #MachineLearning #ComputerVision
How does AI bounding box detection work?
🧠 Learn in 30 seconds
#100DaysOfCode #CodeNewbie #MadeWithTFJS #MachineLearning #ComputerVision

It looks so simple when #AI does it right?
But #machinelearning doesn't give you an image, it gives you data. It's up to you to make it look simple.
But #machinelearning doesn't give you an image, it gives you data. It's up to you to make it look simple.

You might think a #FrontEnd box gives you four values, and you're right, but it only gives you TWO points. From that you can infer a box to draw with #html5.

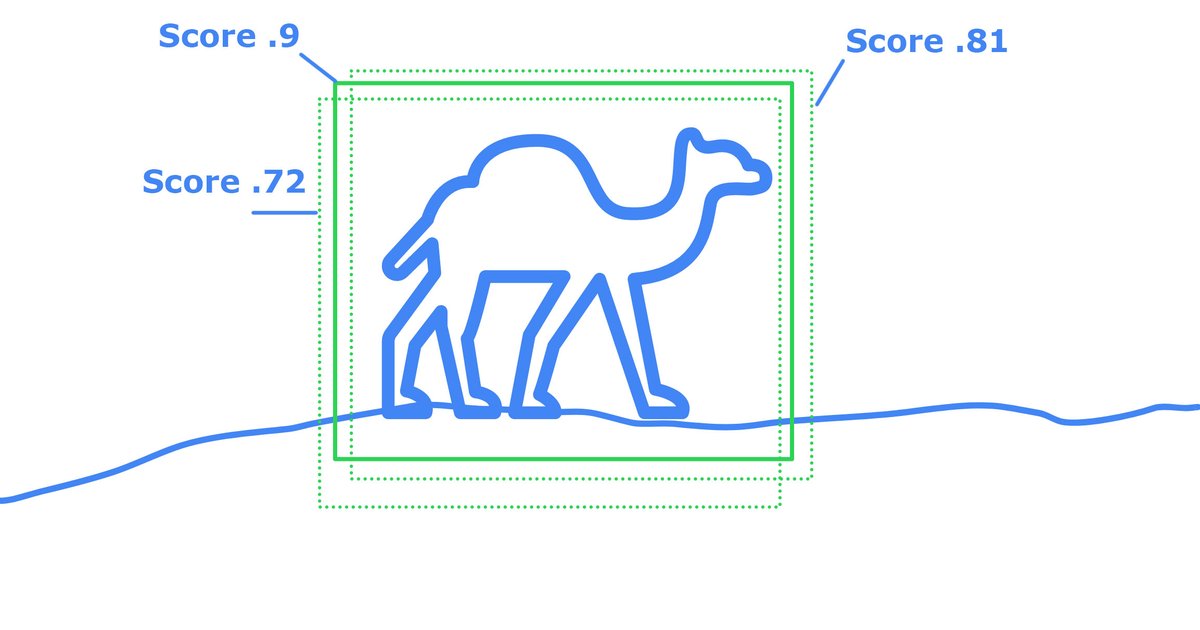
However... it very rarely gives you one box. Lots of times you get a whole bunch of boxes!
This is because the #NeuralNetwork is often trained to return X results no matter what. They just adjust the confidence.
This is because the #NeuralNetwork is often trained to return X results no matter what. They just adjust the confidence.

Each of these boxes will have a score of confidence, and it's your job to identify if they are identifying the same object, or separate objects for proper #DataVisualization.
There's some well known algorithms to take the best of the best from overlapping results.
There's some well known algorithms to take the best of the best from overlapping results.
Once you have the boxes you're interested in, you can draw them easily with a canvas element.
In #JavaScript you just overlay a canvas on the image and draw rectangles there.
In #JavaScript you just overlay a canvas on the image and draw rectangles there.

The final result lets you draw clean object detection on #Web.
Now you have an amazing website that can use #ML to detect objects in photos and video!
Now you have an amazing website that can use #ML to detect objects in photos and video!

Want the code to do this? It's all in Chapter 6 of my @OReillyMedia book with a deep explanation.
If you know JavaScript, you can implement @TensorFlow
Learn more about the book here: infinite.red/learning-tenso…
If you know JavaScript, you can implement @TensorFlow
Learn more about the book here: infinite.red/learning-tenso…
• • •
Missing some Tweet in this thread? You can try to
force a refresh








