I am late to the party (was on holidays), but have now read @lpachter's "Specious Art" paper as well as ~300 quote tweets/threads, played with the code, and can add my two cents.
Spoiler: I disagree with their conclusions. Some claims re t-SNE/UMAP are misleading. Thread. 🐘
Spoiler: I disagree with their conclusions. Some claims re t-SNE/UMAP are misleading. Thread. 🐘
https://twitter.com/lpachter/status/1431325969411821572
The paper has several parts and I have too many comments for a twitter thread, so here I will only focus on the core of the authors' argument against t-SNE/UMAP, namely Figures 2 and 3. We can discuss the rest some other time. [2/n]
In this part, Chari et al. claim that:
* t-SNE/UMAP preserve global and local structure very poorly;
* Purposefully silly embedding that looks like an elephant performs as well or even better;
* Even *untrained* neural network performs around as well.
[3/n]
* t-SNE/UMAP preserve global and local structure very poorly;
* Purposefully silly embedding that looks like an elephant performs as well or even better;
* Even *untrained* neural network performs around as well.
[3/n]
These are very strong claims. However, inspection of Figure 2 suggests an even stronger claim: 2D PCA appears to perform much better still, with respect to both, their global & local metrics (on all datasets). See orange dots.
Strangely, this is not emphasized in the text. [4/n]
Strangely, this is not emphasized in the text. [4/n]

IMHO, these claims are bizarre.
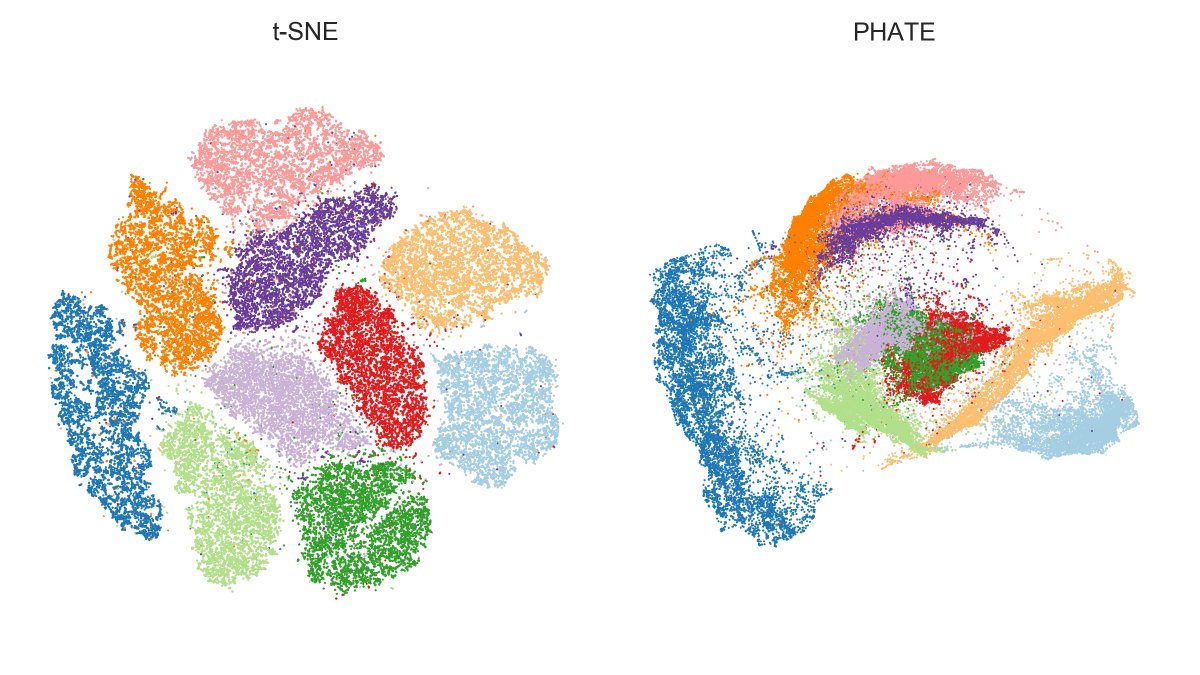
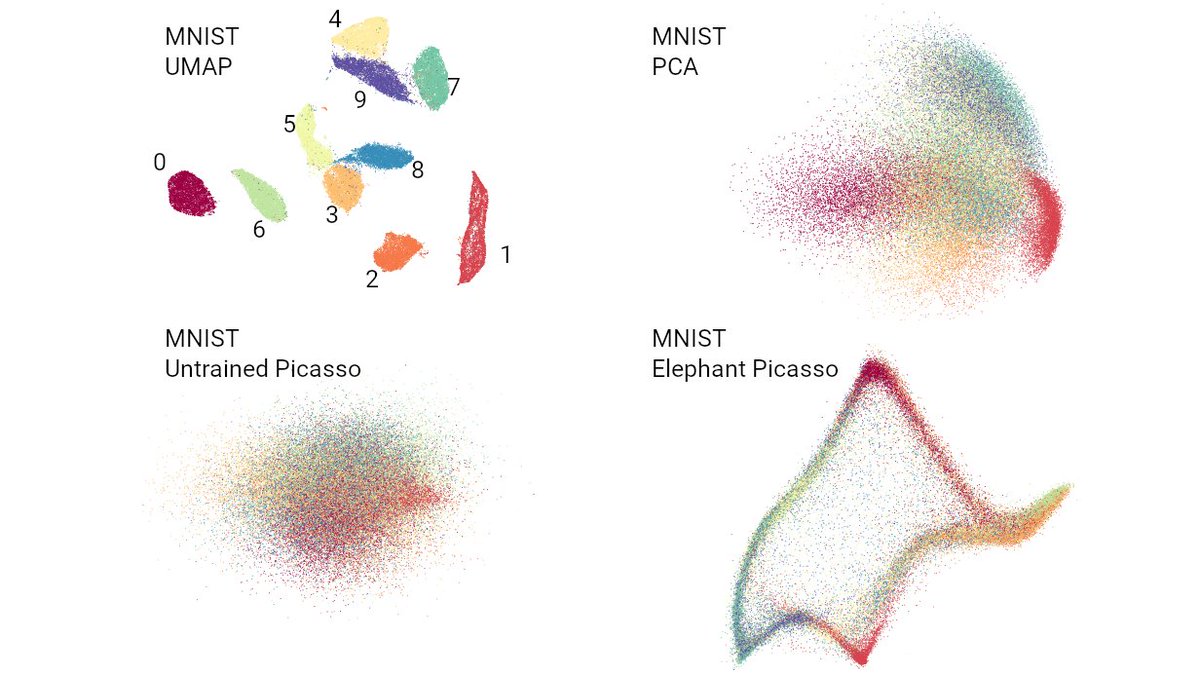
Here are four 2D embeddings of MNIST: UMAP (aka t-SNE with exaggeration); PCA; untrained network; the elephant 🐘.
Chari et al. claim that the latter three are as good as or better than UMAP -- even for local structure preservation. Really? [5/n]
Here are four 2D embeddings of MNIST: UMAP (aka t-SNE with exaggeration); PCA; untrained network; the elephant 🐘.
Chari et al. claim that the latter three are as good as or better than UMAP -- even for local structure preservation. Really? [5/n]

If you have a metric showing that PCA performs better than t-SNE then this metric does not quantify "preservation of local structure".
PCA/Picasso/etc may very well preserve _something_ better than t-SNE, but that "something" is definitely not local structure.
What gives? [6/n]
PCA/Picasso/etc may very well preserve _something_ better than t-SNE, but that "something" is definitely not local structure.
What gives? [6/n]
Turns out, "intra-type" correlations shown in Fig 2 are correlations across t-types between high-dim and low-dim *average* intra-type distances. It's a measure of type variability.
(Took me a while to realize this because Results do not mention averaging, only Methods.) [7/n]
(Took me a while to realize this because Results do not mention averaging, only Methods.) [7/n]
I.e. the message here is that PCA/Picasso/random-network can preserve t-type variances better than t-SNE/UMAP.
Fair enough, but this is not at all what is normally meant by "preservation of local structure"! [8/n]
Fair enough, but this is not at all what is normally meant by "preservation of local structure"! [8/n]
Chari et al. do not use any metrics that would quantify preservation of local structure in the common sense of the word (e.g. kNN recall, kNN classification accuracy, cluster/type Rand score, etc.).
If they did, they would of course find that t-SNE performs much better. [9/n]
If they did, they would of course find that t-SNE performs much better. [9/n]
By the way, I was wondering where the elephant shape came from. The paper calls it "von Neumann elephant" referring to the famous quote but does not explain the exact shape. Googling showed it's taken from this fun paper: aapt.scitation.org/doi/10.1119/1.…
Oddly, it's not cited... [10/n]
Oddly, it's not cited... [10/n]

Acknowledgments: thanks to @jnboehm, @JanLause, and @pavlinpolicar for detailed discussions. MNIST embeddings shown above are taken from a Colab notebook by @akshaykagrawal. [11/n]
The bigger picture of course is that @lpachter believes unsupervised 2D embeddings are useless. "What are they good for?" he asks in twitter discussions.
That is a great question! But I would need a whole other thread to answer it... Maybe later. [12/n]
That is a great question! But I would need a whole other thread to answer it... Maybe later. [12/n]
https://twitter.com/lpachter/status/1432414194712780801
• • •
Missing some Tweet in this thread? You can try to
force a refresh