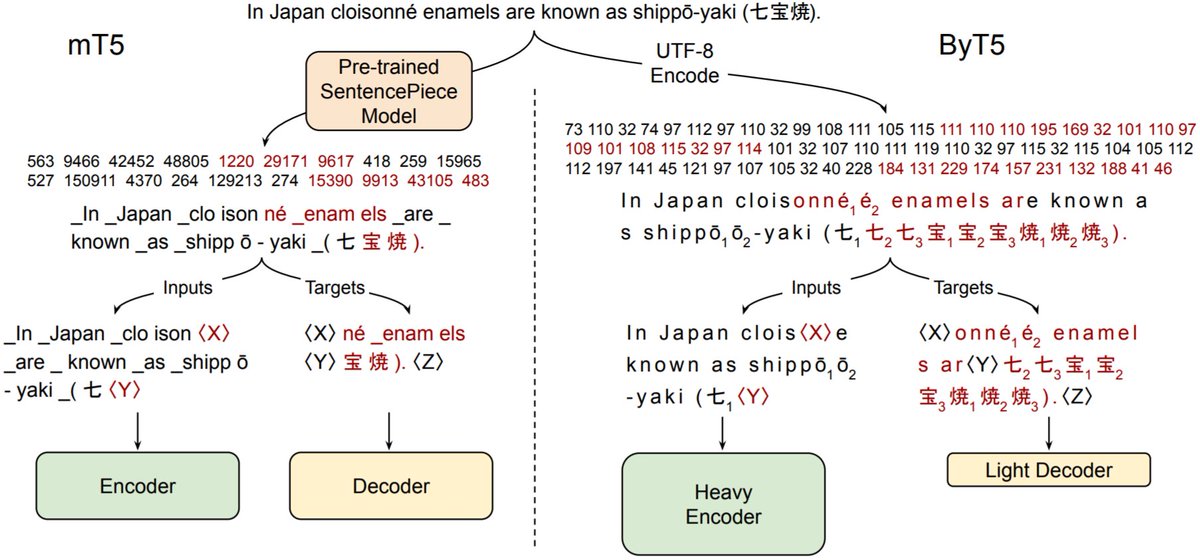
Now that "Do Transformer Modifications Transfer Across Implementations and Applications?" has been accepted to #EMNLP2021, we can finally tweet about it!
Paper 📝: arxiv.org/abs/2102.11972
Code 💾: github.com/google-researc…
Thread summary: ⬇️ (1/8)
Paper 📝: arxiv.org/abs/2102.11972
Code 💾: github.com/google-researc…
Thread summary: ⬇️ (1/8)
After we published the T5 paper where we empirically surveyed many transfer learning methods to find out what works best, we decided to do something similar for Transformer architecture modifications. (2/8)
In the ~3 years since the Transformer was proposed, hundreds of architectural modifications had been proposed but almost none of them are commonly used. In other words, most Transformers people were training were largely the same as proposed in "Attention is All You Need". (3/8)
We were hopeful that by reimplementing many modifications and comparing them in typical settings (transfer learning and supervised learning), we could find some helpful modifications and combine them together to create a best-practice Transformer++ for everyone to use. (4/8)
We recruited a bunch of our colleagues and got to work reimplementing existing modifications. Then, we ran experiments on T5-style transfer learning and machine translation on WMT'14. We were surprised to find that almost none of the modifications actually helped much. (5/8)
What's more, the ones that seemed helpful increased the computational cost or size of the model in some way. So, we pivoted to instead write a paper about this surprising (and somewhat disheartening) finding. (6/8)
We can't conclude from our results that these modifications don't "transfer" to new applications and implementations. However, we tried to rule out other possibilities through some additional experiments that you can find in the paper. (7/8)
We're hopeful that our results will prompt researchers to try out new architectural ideas in more than one codebase, on more than a few tasks, and on more than a few datasets to help ensure their improvement is robust. (8/8)
• • •
Missing some Tweet in this thread? You can try to
force a refresh