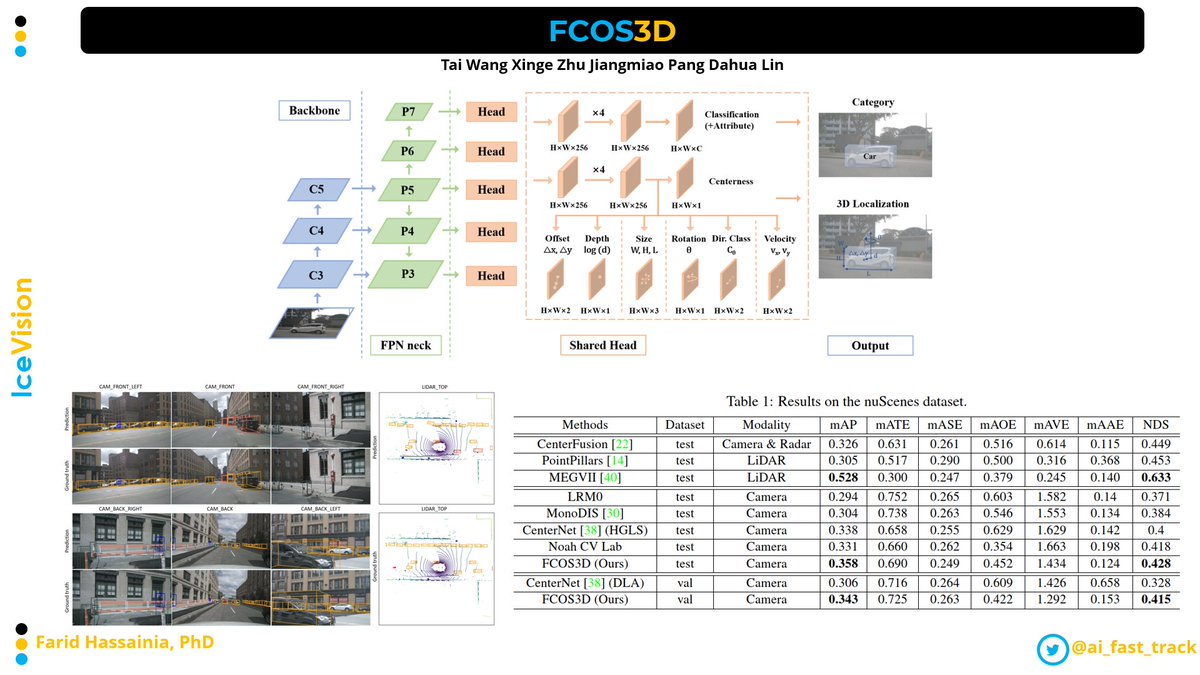
YOLO Real-Time (YOLO-ReT) architecture targets edge devices.
It achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO using MobileNetV2×0.75 backbone.
Here is a brief description of the YOLO-ReT 👇
It achieves 68.75 mAP on Pascal VOC and 34.91 mAP on COCO using MobileNetV2×0.75 backbone.
Here is a brief description of the YOLO-ReT 👇

Both model accuracy and execution time (Frame Per Second) are crucial when deploying a model on edge device. YOLO-ReT is based on these 2 ideas:
⏹ Backbone Truncation: Only 60% of the backbone is initialised with pretrained weights. Using all the weights harms model accuracy
⏹ Backbone Truncation: Only 60% of the backbone is initialised with pretrained weights. Using all the weights harms model accuracy
⏹ Raw Feature Collection and Redistribution (RFCR):
📌 Fuse {C2, C3, C4} into C5 layer (fused feature map)
📌 Discard last CNN layers
📌 Pass the fused feature map through a 5x5 Mobile Convolution block (MBConv)
📌 Fuse {C2, C3, C4} into C5 layer (fused feature map)
📌 Discard last CNN layers
📌 Pass the fused feature map through a 5x5 Mobile Convolution block (MBConv)
📌 At each scale, concatenate (shortcut) the current feature map with the fused feature map from the previous step
Both YOLO-ReT tricks (Backbone & RFCR) could be used in other models too.
Both YOLO-ReT tricks (Backbone & RFCR) could be used in other models too.
Thanks for passing by!
🟧 Def Follow @ai_fast_track for more Object Detection / CV demystified content.
🟦 and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
🟧 Def Follow @ai_fast_track for more Object Detection / CV demystified content.
🟦 and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
https://twitter.com/ai_fast_track/status/1455585130446270471
👩💻 Source Code: github.com/prakharg24/yol…
• • •
Missing some Tweet in this thread? You can try to
force a refresh