🥇 FCOS3D won the 1st place out of all the vision-only methods in the nuScenes 3D Detection Challenge of NeurIPS 2020.
Here is a brief description:
📌 FCOS3D is a monocular 3D object detector
📌 It’s an anchor-free model based on FCOS (2D) counterpart
Here is a brief description:
📌 FCOS3D is a monocular 3D object detector
📌 It’s an anchor-free model based on FCOS (2D) counterpart
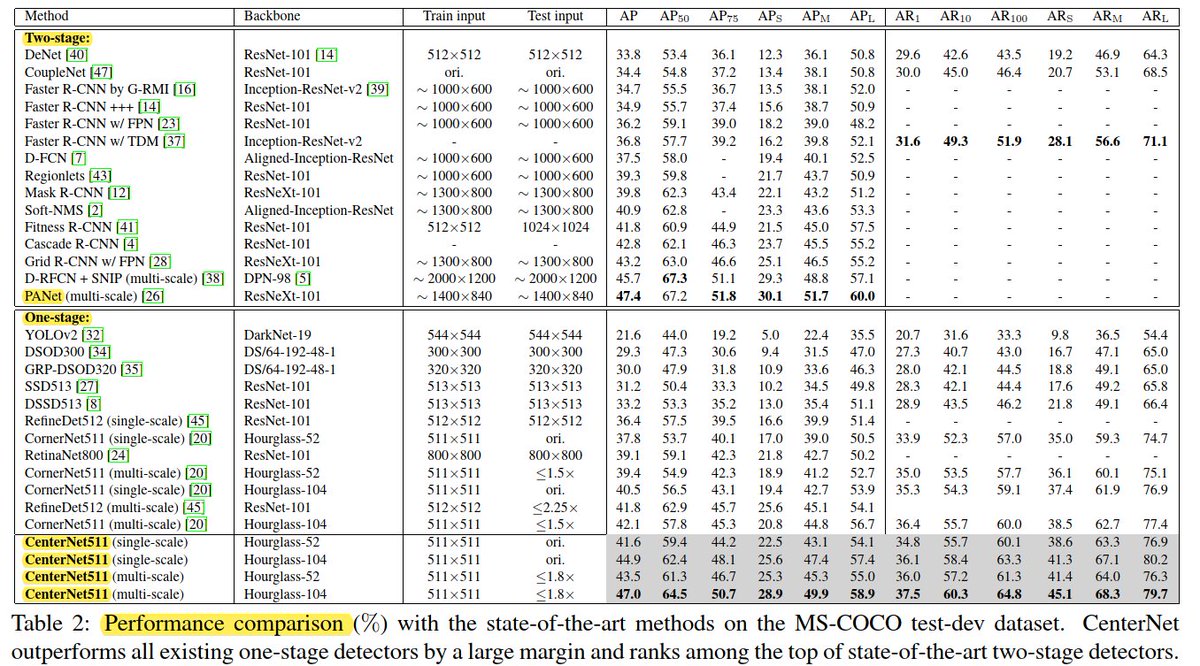
📌 It replaces the FCOS regression branch by 6 branches
📌 The center-ness is redefined with a 2D Gaussian distribution based on the 3D-center
📌 The authors showed some failure cases, mainly focused on the detection of large objects and occluded objects.
📌 The center-ness is redefined with a 2D Gaussian distribution based on the 3D-center
📌 The authors showed some failure cases, mainly focused on the detection of large objects and occluded objects.
⏹ Source code and models are shared in the MMDetection3D repo:
github.com/open-mmlab/mmd…
⏹ MMDetection3D also has many other 3D detection models:
github.com/open-mmlab/mmd…
⏹ MMDetection3D also has many other 3D detection models:
⏹ For those interested in learning more about the original paper of FCOS (2D), I gave a presentation about it here:
📰 Paper: FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection
abs: arxiv.org/abs/2104.10956
pdf: arxiv.org/pdf/2104.10956…
repo: github.com/open-mmlab/mmd…
abs: arxiv.org/abs/2104.10956
pdf: arxiv.org/pdf/2104.10956…
repo: github.com/open-mmlab/mmd…
Thanks for passing by!
and let's make object detection / computer more accessible for all!
🟦Def Follow @ai_fast_track for more Object Detection / CV demystified content.
🟧 If you could give the thread a quick retweet, that would be great!
and let's make object detection / computer more accessible for all!
🟦Def Follow @ai_fast_track for more Object Detection / CV demystified content.
🟧 If you could give the thread a quick retweet, that would be great!
• • •
Missing some Tweet in this thread? You can try to
force a refresh