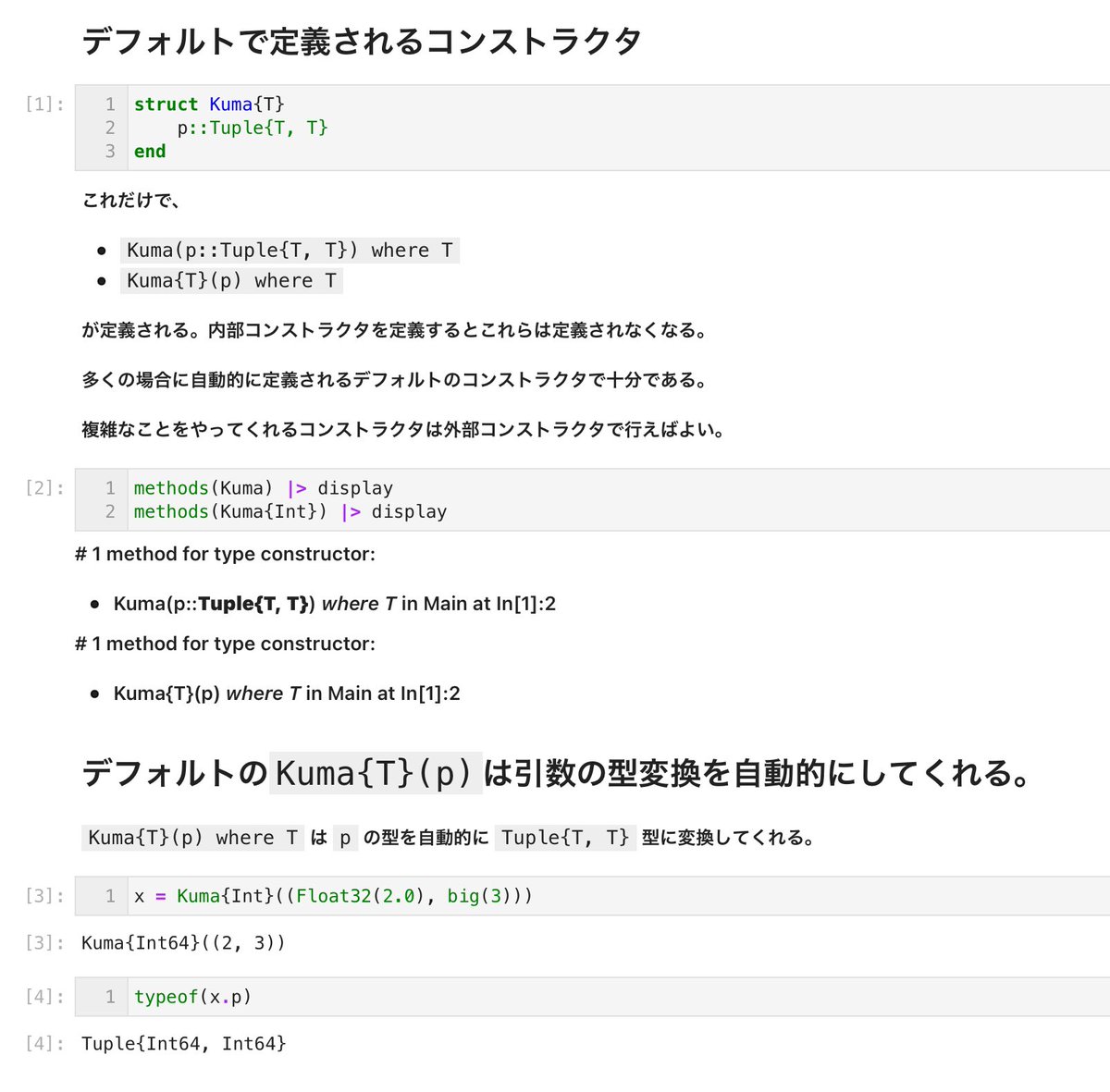
#統計 slideshare.net/simizu706/waic を見ているのかな?
もしもそうなら松浦健太郎さんの
statmodeling.hatenablog.com/entry/waic-wit…
階層ベイズモデルとWAIC
が参考になると思います。StanやRの世界が当時より進歩しているので、もっと良い方法があるかもしれませんが、WAICの実装での考え方を学ぶことができます。
もしもそうなら松浦健太郎さんの
statmodeling.hatenablog.com/entry/waic-wit…
階層ベイズモデルとWAIC
が参考になると思います。StanやRの世界が当時より進歩しているので、もっと良い方法があるかもしれませんが、WAICの実装での考え方を学ぶことができます。
https://twitter.com/e0_rainy/status/1458379096967168008
#統計 階層モデル(階層ベイズモデル)達のモデル選択は結構大変だよという話関連。Stanなどの確率プログラミング言語で記述される「モデル」の情報だけから、予測分布の定義は確定しないので、情報量規準による予測精度の推測によるモデル選択は注意を要する。
↓
↓
https://twitter.com/genkuroki/status/1245255976699101184
#統計 WAICやLOOCV(およびその変種)の類にのみ頼るのではなく、MCMC後に数値積分無しで作れる予測分布のサンプルを使った統計的検定を適切に利用することも考えた方が良いかもしれません。
https://twitter.com/genkuroki/status/1446659603572264967
#統計 ベイズ法その他の方法で得られた予測分布のサンプルを利用して、統計的検定を使う方法の利用の仕方についてはGelman-Shalizi (2013)に詳しく書いてあります。
https://twitter.com/genkuroki/status/1340989272057237505
#統計 重要なポイントは、情報量規準を使う場合であっても、予測分布を統計的検定にかけてみる場合であっても、統計学の道具は「学習の手段」として使われているのであり、お墨付きを得るために使われているのではないこと!
統計学を科学的お墨付きを得る手段とみなす困りものの「哲学」には要注意。
統計学を科学的お墨付きを得る手段とみなす困りものの「哲学」には要注意。
#統計 よくある俗な解説では、検定についてFisher流とNeyman-Pearson流の違いが強調されていたりするが、そういうつまらない解説はやめて、Pearsonさんの言葉を引用して、検定は「学習の手段」であると解説した方がよいと思います。
「お墨付きを得るための手段」的な説明は全廃するべき。
「お墨付きを得るための手段」的な説明は全廃するべき。
https://twitter.com/genkuroki/status/1343177053302976512
#統計 Neyman-PearsonのPearsonさんによる率直な反省の言葉を引用しているのは、検定の数理統計の教科書でも有名な超大物統計学者のErich Lehmannさんです。
統計学の専門家の言葉を重要視するなら、これ以上の人を見つけることは困難。
errorstatistics.com/2017/11/19/eri…
統計学の専門家の言葉を重要視するなら、これ以上の人を見つけることは困難。
errorstatistics.com/2017/11/19/eri…
https://twitter.com/genkuroki/status/1343177053302976512
#統計 そういう統計学専門家の側が、検定についてFisher流とNeyman-Pearson流の違いを強調することは誤解を招くという主旨のことを言っていることを知らずに、俗な解説のコピー&ペーストのごとく「FとNPの検定は違う」と強調し続けることはやめるべきだと思います。
#統計 俗な解説のコピペを知的行為だと誤解しているように見える場合が多過ぎ。
そういうことはググって
errorstatistics.com/2017/11/19/eri…
を発見するだけで確認できる。
そういうことはググって
errorstatistics.com/2017/11/19/eri…
を発見するだけで確認できる。
#統計 ベイズ統計と検定が思想的に水と油であるかのように解説している人達も俗な解説のコピペをしているに過ぎない。
Stan開発の親玉的な存在としても有名なGelmanさんは全然違うことを言っており、実際に、ベイズ統計を使った論文でも予測分布のP値を計算してモデルチェックを行なっていたりする。
Stan開発の親玉的な存在としても有名なGelmanさんは全然違うことを言っており、実際に、ベイズ統計を使った論文でも予測分布のP値を計算してモデルチェックを行なっていたりする。
#統計 俗な解説のコピペを学生に教えている大学の先生達がかなり多いので、この問題は当分のあいだ解決しないと思われます。
#統計 統計学の専門家の別のビッグネームとして赤池弘次さんの名前を挙げることは適切だと思う。赤池さんが書いた40年以上前の論説を見ても、検定とベイズ統計が思想的に水と油であるかのような考え方には全然なっていないことが分かります。
https://twitter.com/genkuroki/status/1449926498752741387
#統計 統計学についてずさんな考え方が俗な解説のコピペとして蔓延しているという問題は日本語圏だけの問題ではありません。
だから、LehmannさんやGelmanさん達が論文を書いたり、赤池さんも英語での論争論文を書くことになった。
だから、LehmannさんやGelmanさん達が論文を書いたり、赤池さんも英語での論争論文を書くことになった。
#統計 統計学における思想や哲学については、Lehmannさんや、Gelman-Shaliziや、赤池弘次さんのような筋の通ったことを言っている人達の意見を参考にし、俗な解説のコピペで各種の主義について語る人達の意見にあまり影響されないように注意した方がよいです。
#統計 特に参考にしてはいけない人達は「Royallの3つの問い」の線に沿って統計学について語る人達です。そのような人達は、尤度主義、ベイズ主義、頻度主義(この3つが「3つの問い」)というような無用でかつ初学者が触れるとまともな理解への道が閉されかねない言説を再生産しているので本当に要注意。
• • •
Missing some Tweet in this thread? You can try to
force a refresh