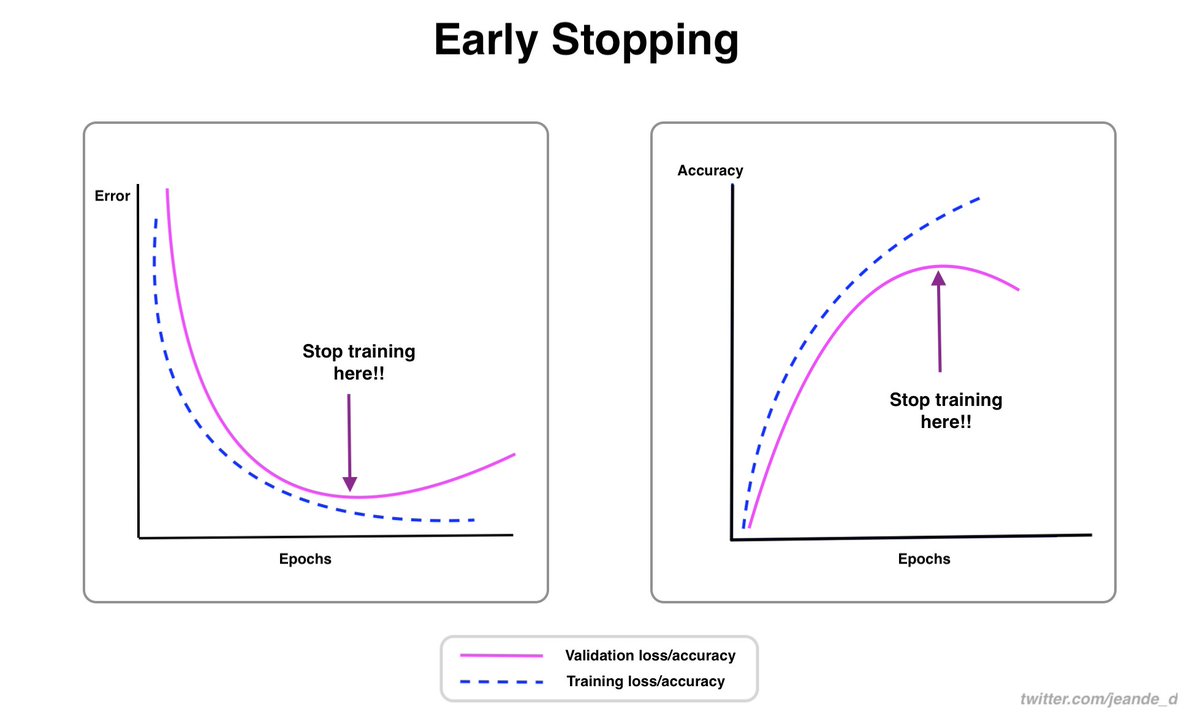
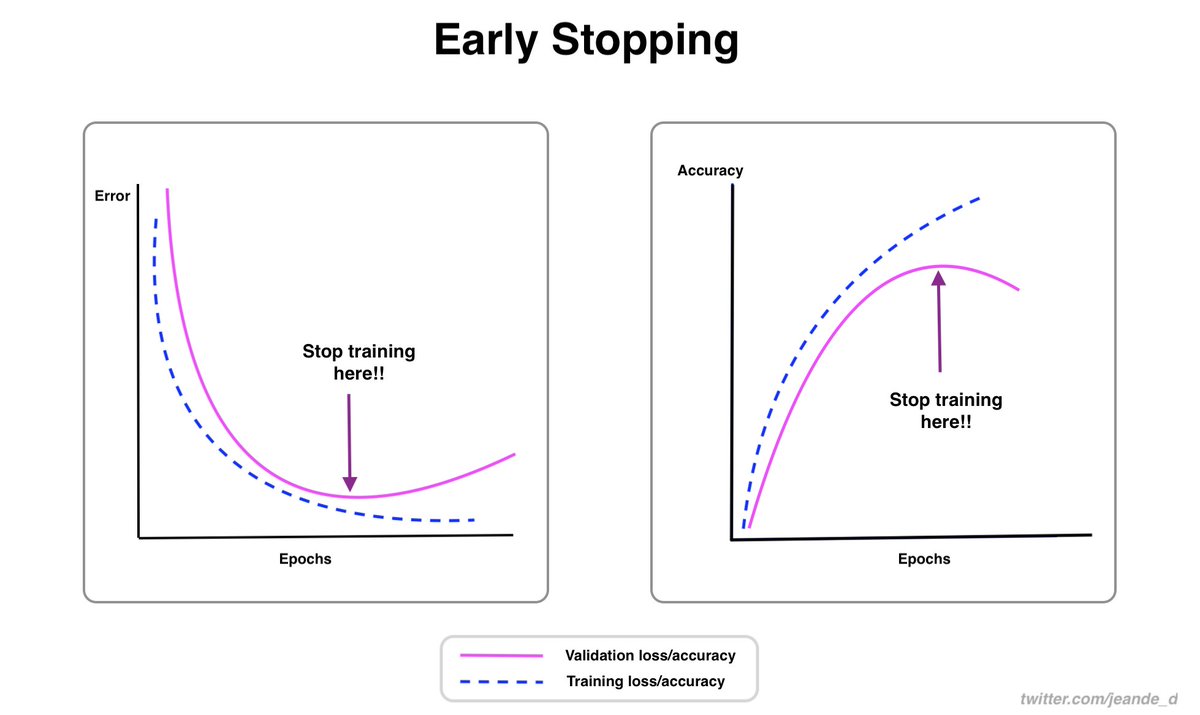
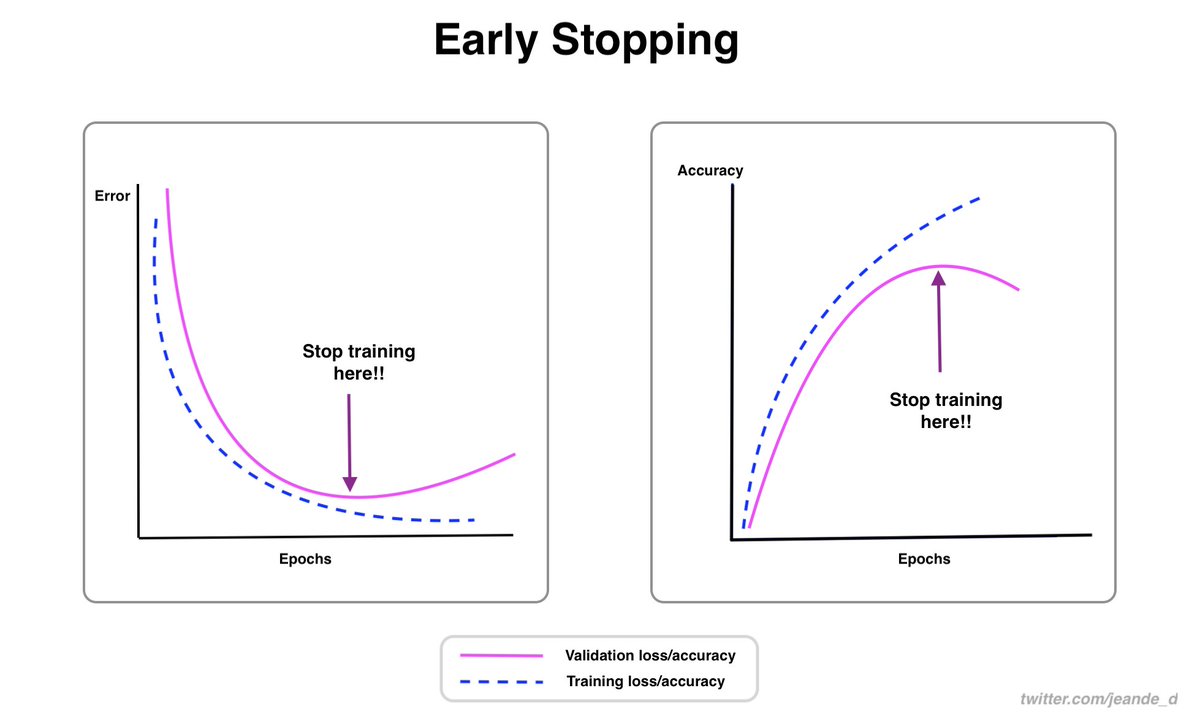
Learning rate is one of the most important hyperparameters to adjust well during the ML model training.
A high learning rate can speed up the training, but it can cause the model to diverge. A low rate can slow the training.
Here are different learning rate curves
A high learning rate can speed up the training, but it can cause the model to diverge. A low rate can slow the training.
Here are different learning rate curves

A low learning rate can also give poor results.
A good recommended practice is to usually start with a high rate and then reduce it accordingly.
There are many techniques that can be used to achieve that. They are called learning rate schedulers.
A good recommended practice is to usually start with a high rate and then reduce it accordingly.
There are many techniques that can be used to achieve that. They are called learning rate schedulers.
Example of learning rate scheduling techniques:
◆Power scheduler
◆Exponential scheduler
◆Piecewise constant or multi-factor scheduler
◆Performance scheduler
◆Cosine schedule
◆Power scheduler
◆Exponential scheduler
◆Piecewise constant or multi-factor scheduler
◆Performance scheduler
◆Cosine schedule
• • •
Missing some Tweet in this thread? You can try to
force a refresh