Machine Learning Weekly Highlights 💡
◆3 things from me
◆2 things from other people and
◆2 from the community
🧵🧵
◆3 things from me
◆2 things from other people and
◆2 from the community
🧵🧵
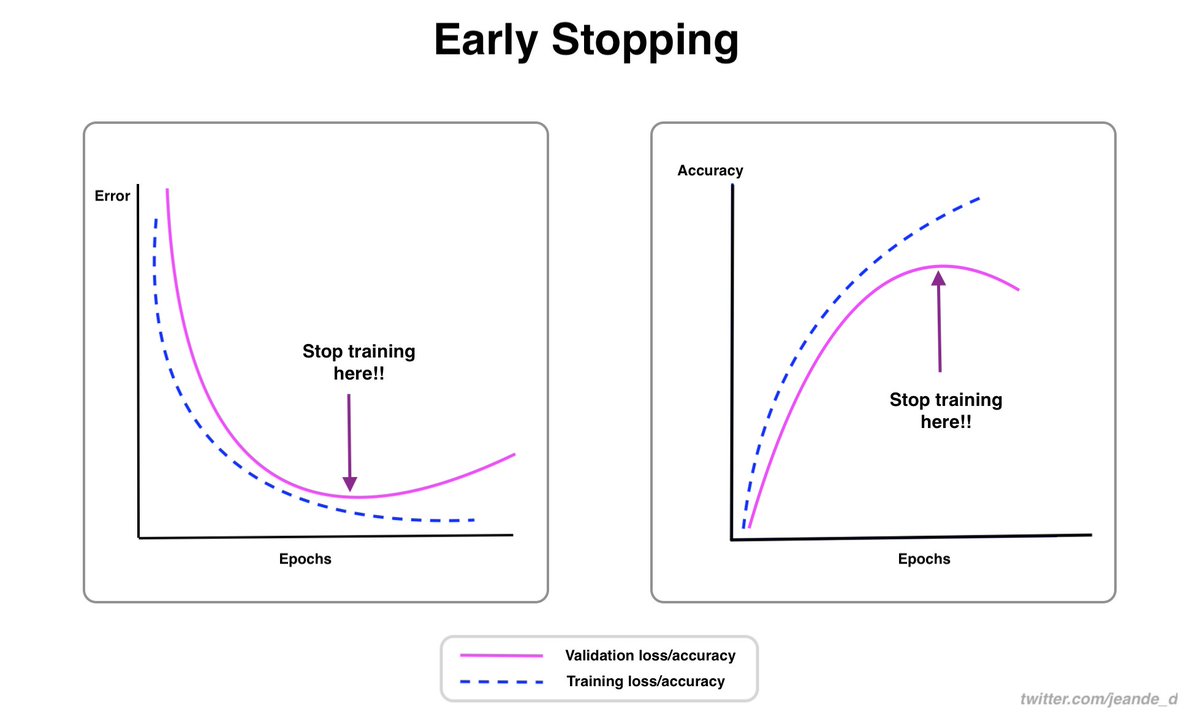
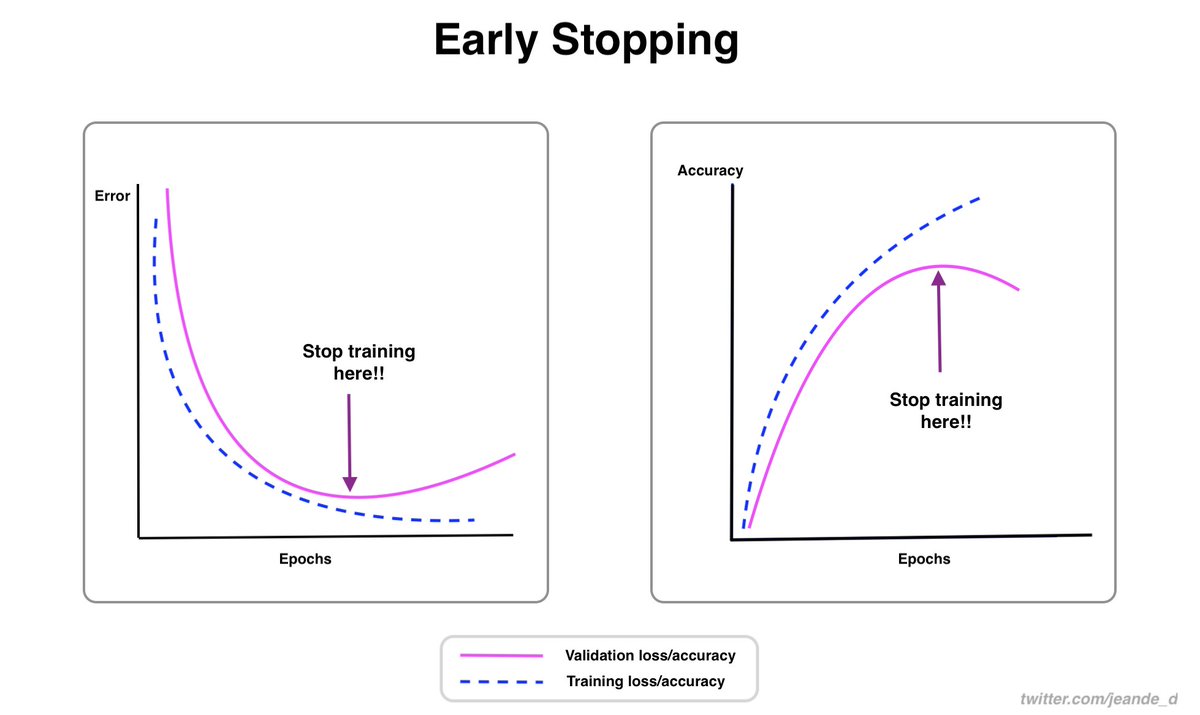
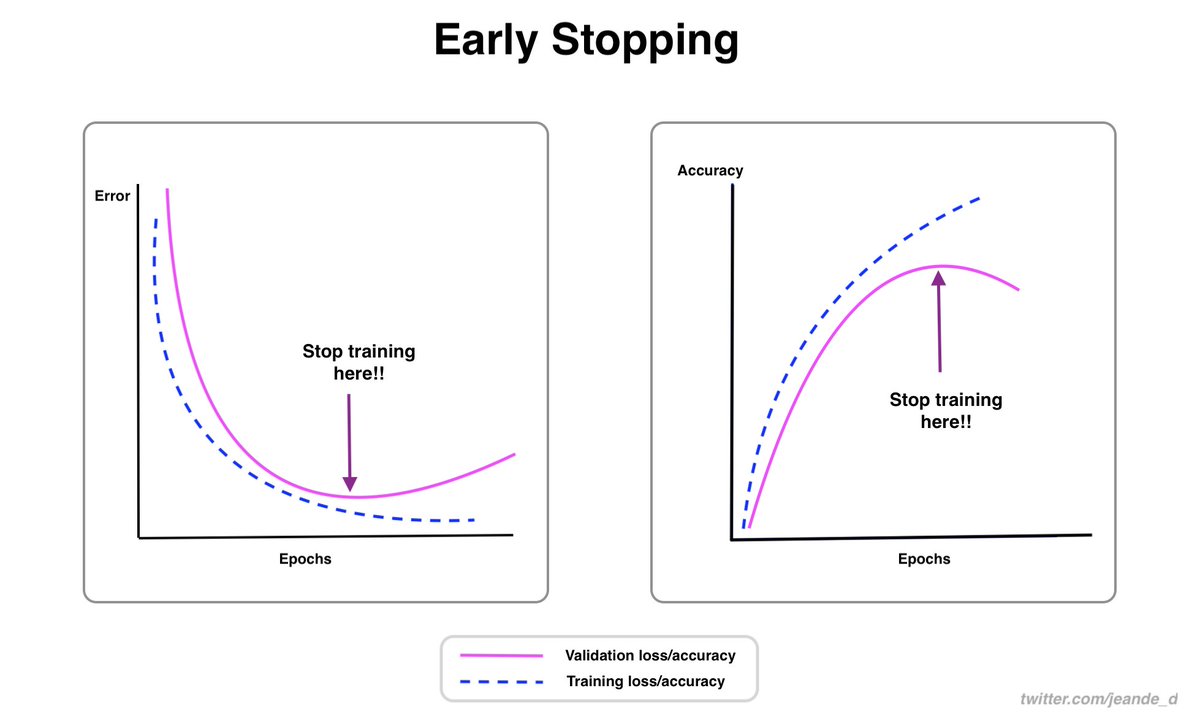
This week, I wrote about what to consider while choosing a machine learning model for a particular problem, early stopping which is one of the powerful regularization techniques, and what to know about the learning rate.
The next is their corresponding threads!
The next is their corresponding threads!
1. What to know about a model selection process...
https://twitter.com/Jeande_d/status/1457706252616617987?s=20
3. And what you should know about learning rates, their different curves, and techniques used to schedule them.
https://twitter.com/Jeande_d/status/1459222900066586625?s=20
Two things from other people:
1. @rasbt shared 170 deep learning videos that he recorded in 2021. Not merely from this week, but I got to know about them this week. Thanks to @alfcnz for retweeting them...
Check those 170 videos out!
1. @rasbt shared 170 deep learning videos that he recorded in 2021. Not merely from this week, but I got to know about them this week. Thanks to @alfcnz for retweeting them...
Check those 170 videos out!
https://twitter.com/rasbt/status/1413549925217013763?s=20
Two things from the community
1. @Nvidia GTC 2021: Lots of updates from NVIDIA which is on a mission of designing powerful deep learning accelerators.
1. @Nvidia GTC 2021: Lots of updates from NVIDIA which is on a mission of designing powerful deep learning accelerators.
I watched the keynote. It's great. There are lots of amazing news and updates from Omniverse, NVIDIA Drive, more accessibility to vision and language pre-trained models, to Jarvis AI accurate conversational bot...
Give it a watch! It's a great event!!
Give it a watch! It's a great event!!
2. Gradients all not all you need
This paper from @Luke_Metz discusses the potential chaos of using gradients-based optimization algorithms. Most optimizers compute the gradients of the weights in order to minimize the loss function.
This paper from @Luke_Metz discusses the potential chaos of using gradients-based optimization algorithms. Most optimizers compute the gradients of the weights in order to minimize the loss function.
That usually works (but there is no theoretical guarantee that proves it always will).
The paper highlights the issues of gradients and adds that they are not all you need sometimes. Thanks to @rasbt for sharing this.
The paper highlights the issues of gradients and adds that they are not all you need sometimes. Thanks to @rasbt for sharing this.
https://twitter.com/Luke_Metz/status/1458661090326286336?s=20
This is the end of this week's highlights. I plan to keep doing them.
Also, I am thinking a lot about going deep into some particular topics/concepts in my newsletter.
While I haven't yet put it together, you can sign up right away here:
getrevue.co/profile/deepre…
Also, I am thinking a lot about going deep into some particular topics/concepts in my newsletter.
While I haven't yet put it together, you can sign up right away here:
getrevue.co/profile/deepre…
Thanks for reading!
For more ideas about machine learning, follow @Jeande_d!
Until the next week, stay safe!
For more ideas about machine learning, follow @Jeande_d!
Until the next week, stay safe!
• • •
Missing some Tweet in this thread? You can try to
force a refresh