Activations functions are one of the most important components of any typical neural network.
What exactly are activation functions, and why do we need to inject them into the neural network?
A thread 🧵🧵
What exactly are activation functions, and why do we need to inject them into the neural network?
A thread 🧵🧵
Activations functions are basically mathematical functions that are used to introduce non linearities in the network.
Without an activation function, the neural network would behave like a linear classifier/regressor.
Without an activation function, the neural network would behave like a linear classifier/regressor.
Or simply put, it would only be able to solve linear problems or those kinds of problems where the relationship between input and output can be mapped out easily because input and output change in a proportional manner.
Let me explain what I mean by that...
Let me explain what I mean by that...
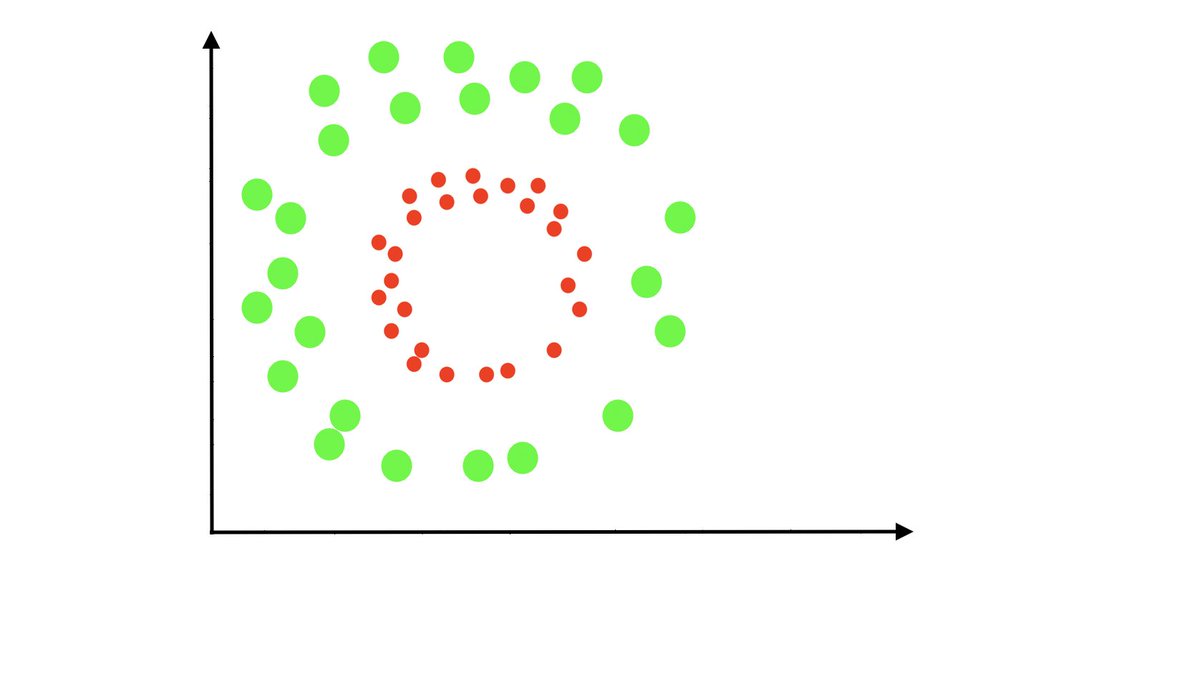
Let's say that you want to classify or separate two categories in a given data. To make that simple, for example, you want to separate red and green points. Just an example!
Your dataset looks like this 👇
Your dataset looks like this 👇
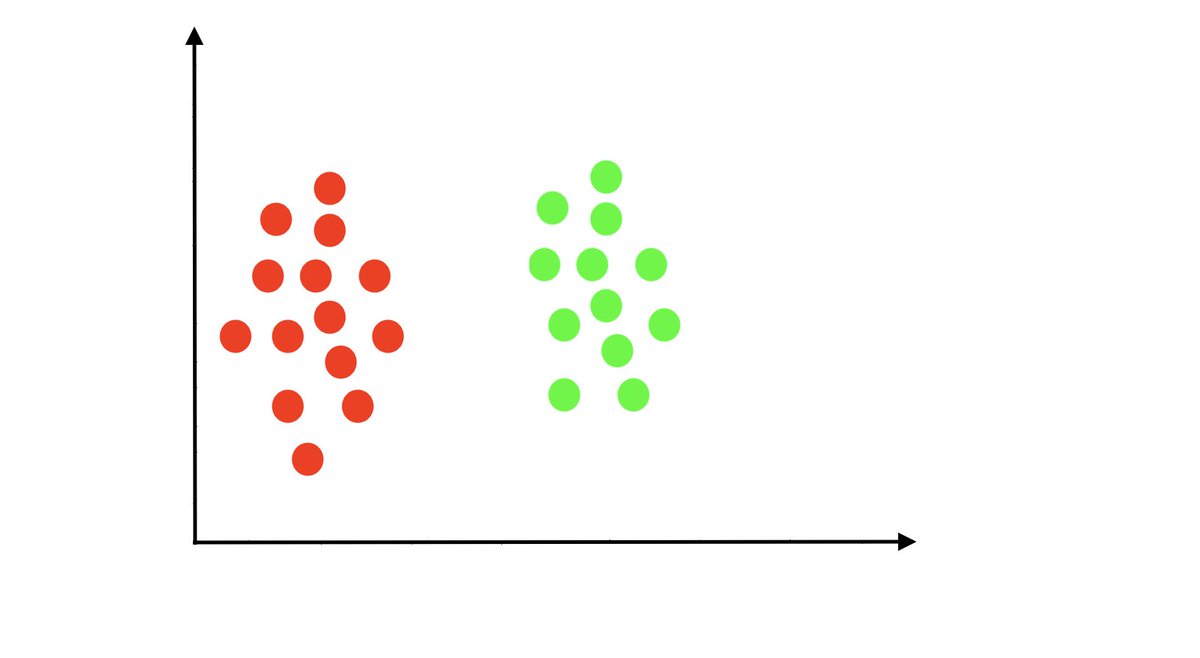
To classify those two points, all you have to do is to draw a straight decision line. You do not need to inject any non-linearities.

We can also try using TensorFlow Playground to simulate similar problem.
Take a loot at the configuration in the image or trying running it yourself: Similar input data as we have above (with little bit of noise), no non-linear activation function.
playground.tensorflow.org/#activation=li…
Take a loot at the configuration in the image or trying running it yourself: Similar input data as we have above (with little bit of noise), no non-linear activation function.
playground.tensorflow.org/#activation=li…

As you can see in the output, the network tried to separate the orange and blue points. Not 100% accurate, but not so bad. Also consider there are some noises in the data.
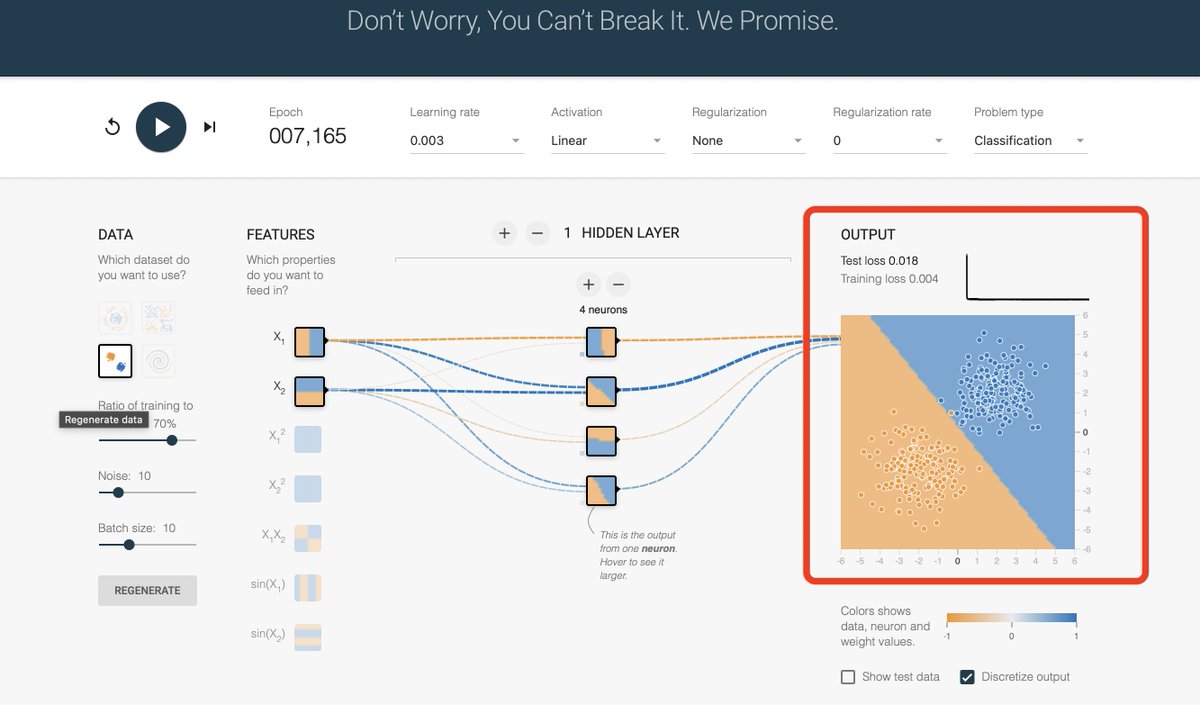
But we are very limited on the problems we can solve without non linearities. Why?
Well, the real world problems and data are rarely linear.
Well, the real world problems and data are rarely linear.
Take an example in cat and dog classification. If you take the image of a cat and change some pixels values, it will still be a cat.
The change in input pixels doesn't necessarily results in change of output. Pixels values and what they represent are not linear.
The change in input pixels doesn't necessarily results in change of output. Pixels values and what they represent are not linear.
Usually, two things are linear if change in one thing is directly proportional to change in other thing. Otherwise, they are not linear.
For most real world problems, the mapping between data and the output is not directly proportional. Cat & dog classification was on example.
In order to solve those complex non-linear problems, we need to use non linearities. We need to give the network the ability to solve high order functions(mathematically speaking).
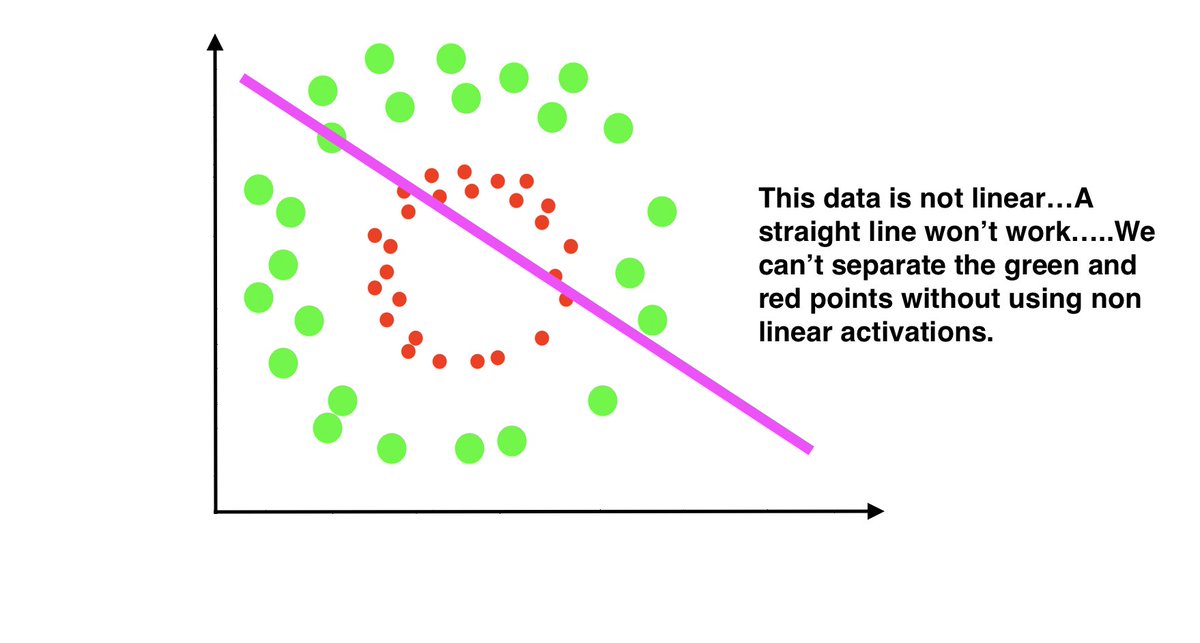
Take a look below..As you can see, straight line won't work here....We need to add something else.
Take a look below..As you can see, straight line won't work here....We need to add something else.
Below we illustrate that just drawing a straight boundary line won't work.
We can again use TF Playground to simulate the above.
At first, let's try a linear activation function.
As you can see, it can't work. Whether you can regularize, or train for thousands of epochs, it's not possible to solve a nonlinear problem with linear methods.
At first, let's try a linear activation function.
As you can see, it can't work. Whether you can regularize, or train for thousands of epochs, it's not possible to solve a nonlinear problem with linear methods.

But with just changing the activation function from Linear to ReLU or Sigmoid, the results are quite different.
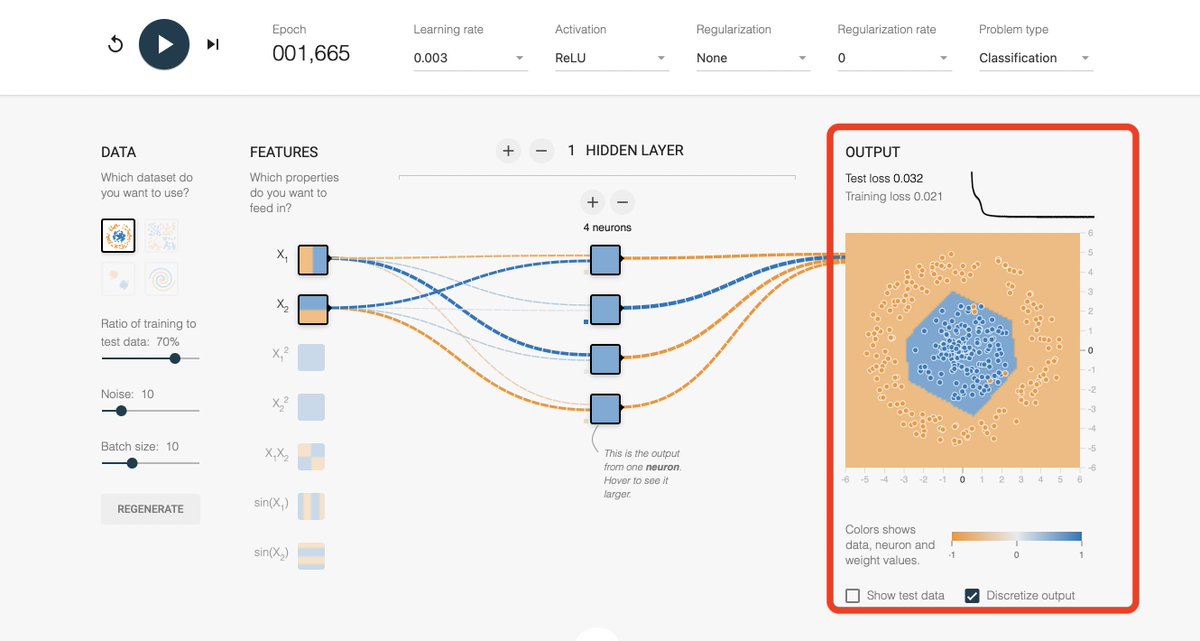

ReLU and Sigmoid that we used above are the mostly used activation function.
There are many other activation functions such as Tanh, Leaky ReLU, SeLU, ELU, Maxout...
Here are their graphical representation.
Image: Internet, no proper credit, used in multiple places
There are many other activation functions such as Tanh, Leaky ReLU, SeLU, ELU, Maxout...
Here are their graphical representation.
Image: Internet, no proper credit, used in multiple places

There are some known specifics about the proper usage of activation functions.
Here are some:
◆First and foremost, always use ReLU in the hidden layers. It's fast and it works great. Try its versions like Leaky ReLU when you want extra boost in the accuracy or other metrics.
Here are some:
◆First and foremost, always use ReLU in the hidden layers. It's fast and it works great. Try its versions like Leaky ReLU when you want extra boost in the accuracy or other metrics.
◆Avoid using sigmoid and tanh in the first layers of the network or generally in all hidden layers. They can cause the gradients to vanish quickly and that's a quick ride to getting poor results.
I talked about gradients problems in my past tweets.
I talked about gradients problems in my past tweets.
https://twitter.com/Jeande_d/status/1455486459876569091?s=20
Sigmoid and Tanh are also computationally expensive due to the presence of exponent in their formula.
◆As a rule for what activation function should be in the last layer, use sigmoid for binary classification and multi-label classification problems, and use softmax for multi-class classification problems.
If you are merely doing regression, then you can use ReLU or leave it!
If you are merely doing regression, then you can use ReLU or leave it!
◆As the last rule, always use ReLU at first.
This is the end of the thread. It was long, but let's try summarizing it.
Activation functions are used to introduce non linearities in the neural network. A network that doesn't have activation function is like a linear classifier/regressor.
Activation functions are used to introduce non linearities in the neural network. A network that doesn't have activation function is like a linear classifier/regressor.
Real world problems are rarely linear.
In order to solve them, we have to inject non-linearities into the network to give it the ability to solve those non linear problems.
It's actually like allowing the network to bend itself to fit the problem.
In order to solve them, we have to inject non-linearities into the network to give it the ability to solve those non linear problems.
It's actually like allowing the network to bend itself to fit the problem.
Plugging in nonlinearities into neural network makes them so powerful enough to handle complex problems.
The choice of activation function depends on the problem, but as a general rule, you should always use ReLU in the hidden layers.
It works great, it's cheap, and it's awesome :)
It works great, it's cheap, and it's awesome :)
If you would like to learn more, I recommend you go to TensorFlow Playground and play with different types of data and activations functions.
You will see how changing them affects the behavior of the neural network.
playground.tensorflow.org
You will see how changing them affects the behavior of the neural network.
playground.tensorflow.org
Thanks for reading.
I regularly write about machine learning and deep learning ideas.
Machine learning theories can be complex despite having low actual value in what someone can produce. My goal is to simplify them.
Follow @Jeande_d for more machine learning ideas!
I regularly write about machine learning and deep learning ideas.
Machine learning theories can be complex despite having low actual value in what someone can produce. My goal is to simplify them.
Follow @Jeande_d for more machine learning ideas!
• • •
Missing some Tweet in this thread? You can try to
force a refresh