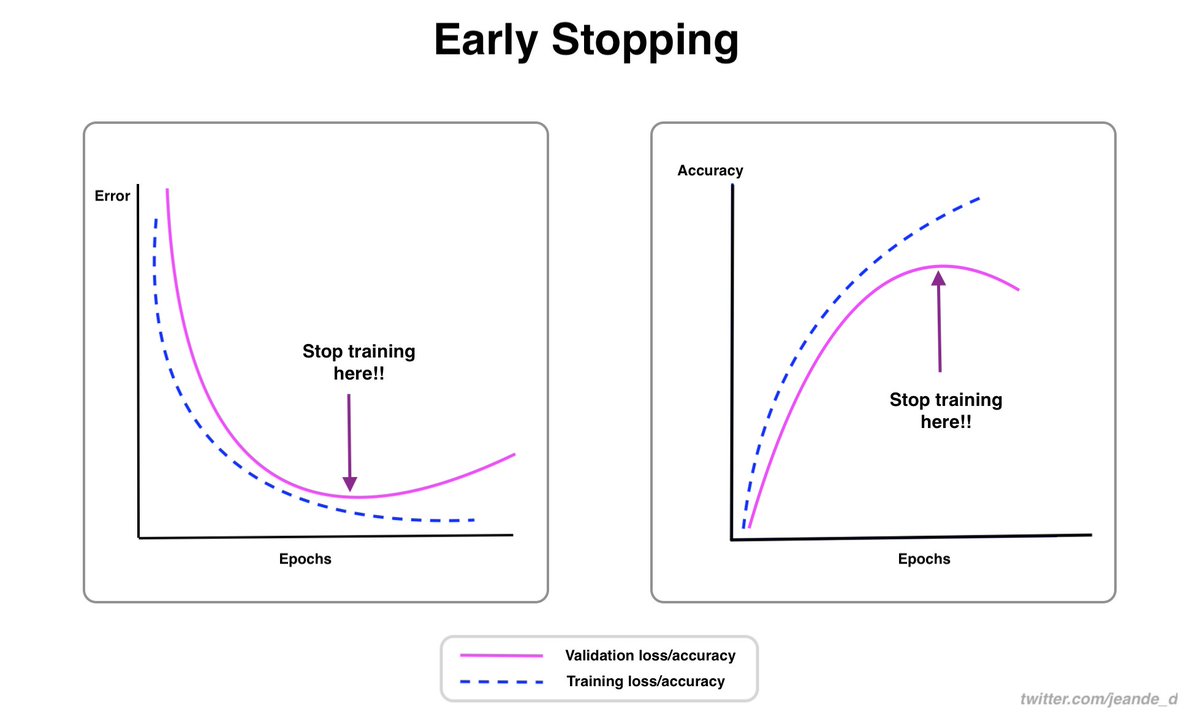
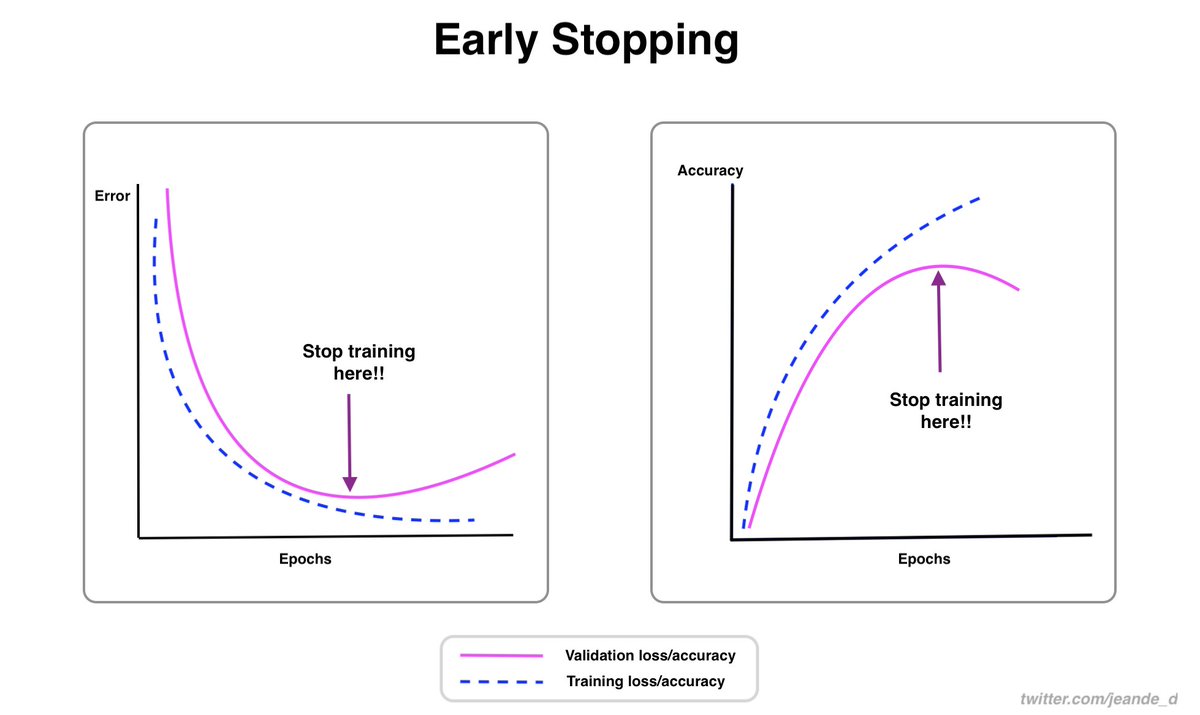
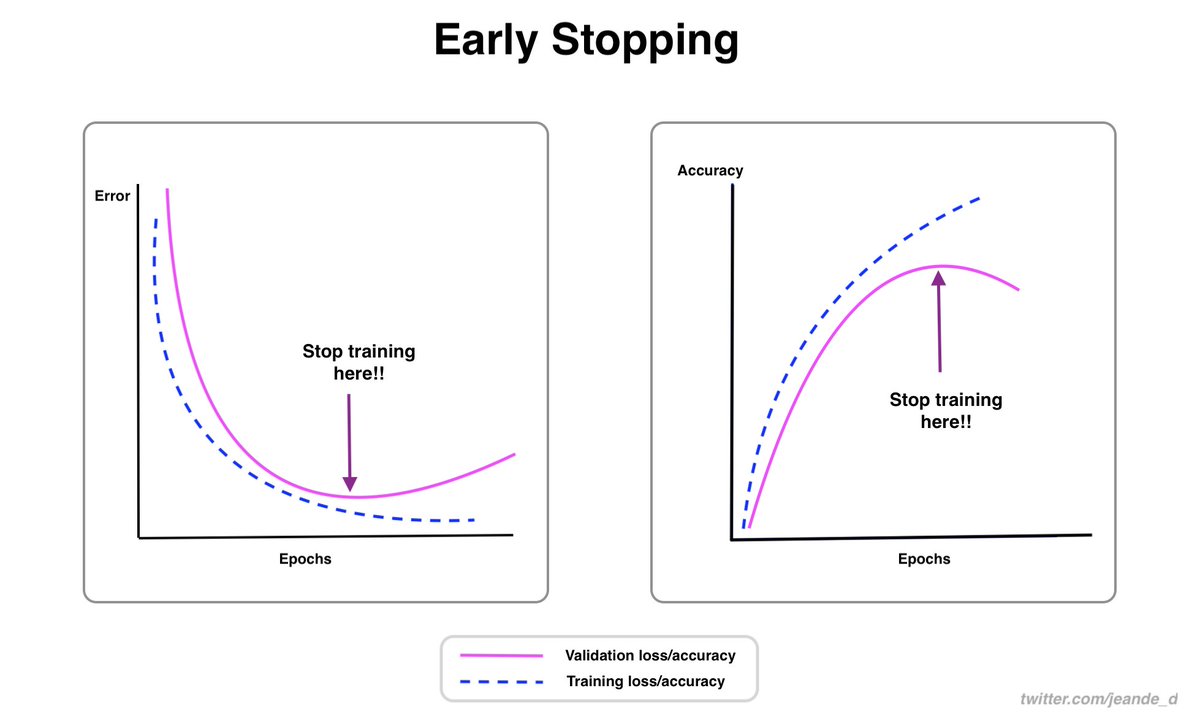
Image classification is one of the most common & important computer vision tasks.
In image classification, we are mainly identifying the category of a given image.
Let's talk more about this important task 🧵🧵
In image classification, we are mainly identifying the category of a given image.
Let's talk more about this important task 🧵🧵
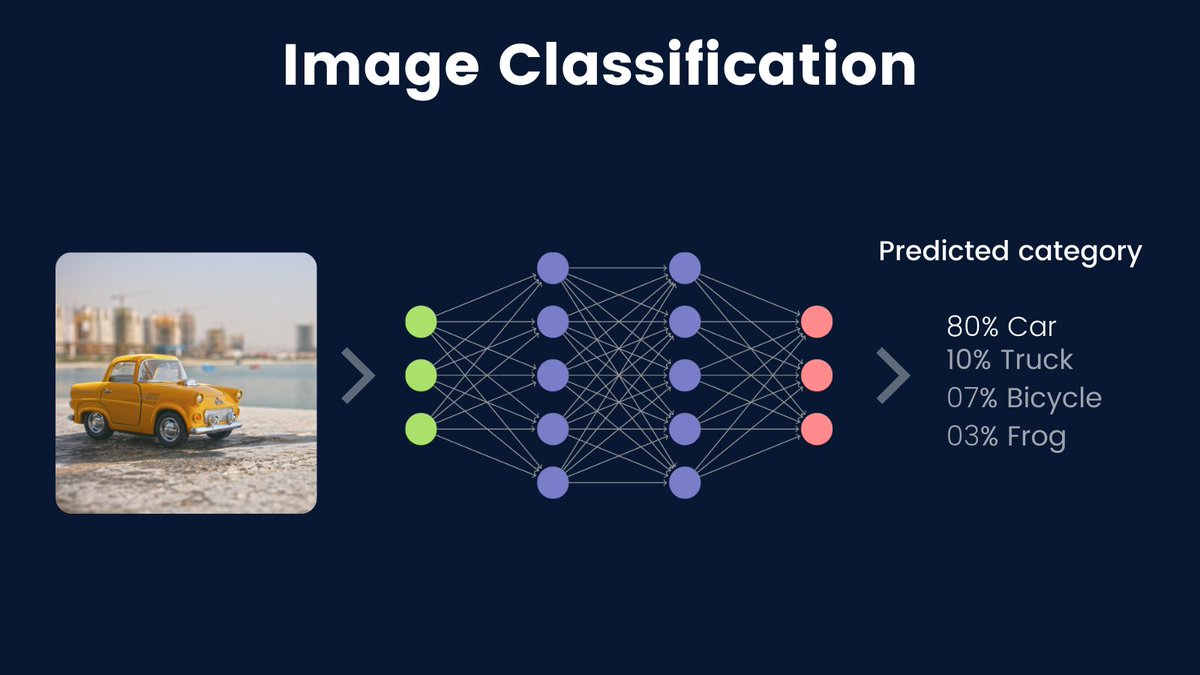
Image classification is about recognizing the specific category of the image from different categories.
Take an example: Given an image of a car, can you make a computer program to recognize if the image is a car?
Take an example: Given an image of a car, can you make a computer program to recognize if the image is a car?
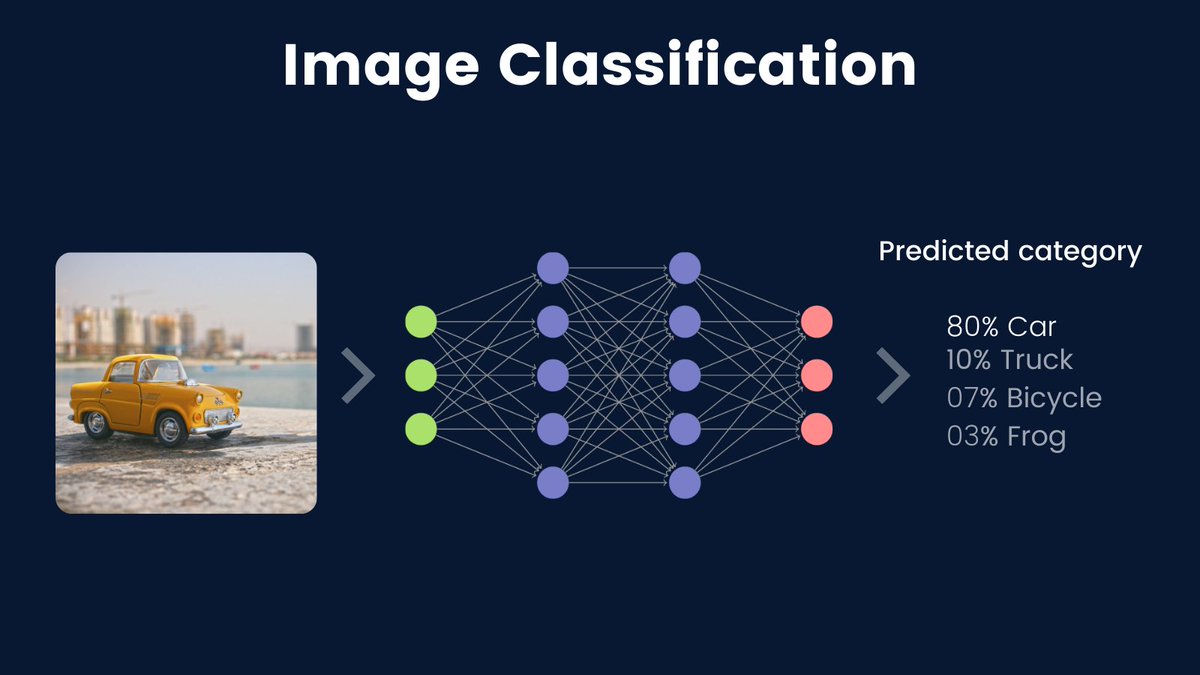
One might ask why we even need to make computers recognize the images. He or she would be right.
Humans have an innate perception system. Identifying or recognizing the objects seems to be a trivial task for us.
But for computers, it's a different story. Why is that?
Humans have an innate perception system. Identifying or recognizing the objects seems to be a trivial task for us.
But for computers, it's a different story. Why is that?
Computers only understand numbers. When you look at a car, you know it's a car. When you feed a car image to a computer, it only sees numbers or pixel values.
To a computer, images are just numbers!
(Pixels values in the image below are just an example)
To a computer, images are just numbers!
(Pixels values in the image below are just an example)

The fact that computers only see numbers make it hard for them to recognize similar images that are in different conditions such as color, or scene difference.
As you might also guess, that's the reason why we need varieties in the training images.
As you might also guess, that's the reason why we need varieties in the training images.
Image classification has enabled many real-world applications such as medical disease diagnosis, where we may for example take a medical scan image, and identify if there is a presence of a particular disease.
Image classification is also useful in many other tasks such as crops classification, food classification(see nutrify.app by @mrdbourke), visual similarity search, product tagging, face recognition, etc...
As you can see, image classification is an important task.
As you can see, image classification is an important task.
Also, image classification is the heart of other computer vision tasks such as object detection.
In object detection, we recognize the objects that are present in the image, localize them, and draw the bounding boxes around them.
In object detection, we recognize the objects that are present in the image, localize them, and draw the bounding boxes around them.

There are 3 main types of classification problems that are:
◆Binary image classification
◆Multi-label classification
◆Multi-class classification
Let's discuss them...
◆Binary image classification
◆Multi-label classification
◆Multi-class classification
Let's discuss them...
1. BINARY IMAGE CLASSIFICATION
In binary image classification, we are dealing with 2 categories.
A well-known example of this type is cats and dogs classification. Given the image of a cat or dog, recognize if the image contains a cat or dog.
In binary image classification, we are dealing with 2 categories.
A well-known example of this type is cats and dogs classification. Given the image of a cat or dog, recognize if the image contains a cat or dog.
2. MULTI-LABEL CLASSIFICATION
Multi-label classification is a special type. In this type, a single image can belong to more than 1 category.
Ex: Given an image of a vehicle, recognize its vehicle type, but also identify the model of such type(among other different models).
Multi-label classification is a special type. In this type, a single image can belong to more than 1 category.
Ex: Given an image of a vehicle, recognize its vehicle type, but also identify the model of such type(among other different models).
3. MULTI-CLASS CLASSIFICATION
Multi-class classification is very common. It is concerned with determining the category of the image from multiple categories(ideally, more than 2).
Ex: 10 fashions classification, rock-paper-scissor classification, etc....
Multi-class classification is very common. It is concerned with determining the category of the image from multiple categories(ideally, more than 2).
Ex: 10 fashions classification, rock-paper-scissor classification, etc....
This is the end of the thread that was about image classification.
Image classification is really an important task. It has enabled a wide range of real-world applications in many industries such as medicine, agriculture, manufacturing industries, etc...
Image classification is really an important task. It has enabled a wide range of real-world applications in many industries such as medicine, agriculture, manufacturing industries, etc...
We saw that there are 3 main types of classification tasks: Binary image classification, multi-label, and multi-class classification.
Thanks for reading.
I regularly write about machine learning and deep learning ideas. My goal is to simplify complex concepts.
If you haven't done it yet, follow @Jeande_d for more machine learning things!
I regularly write about machine learning and deep learning ideas. My goal is to simplify complex concepts.
If you haven't done it yet, follow @Jeande_d for more machine learning things!
• • •
Missing some Tweet in this thread? You can try to
force a refresh