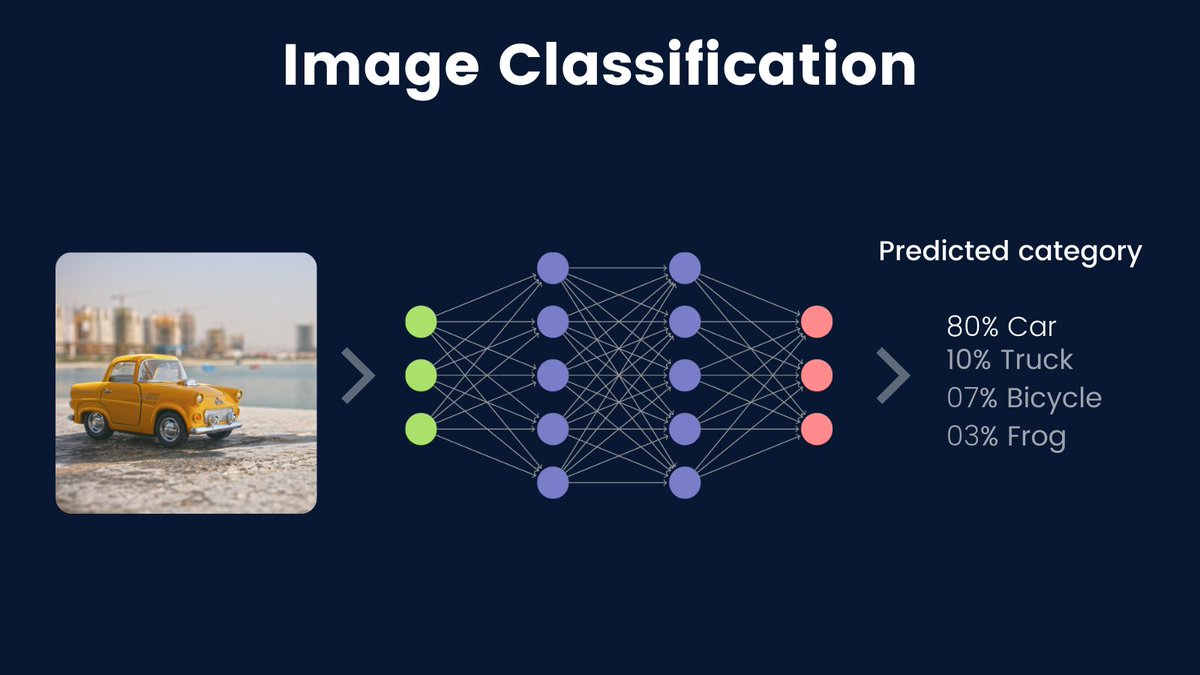
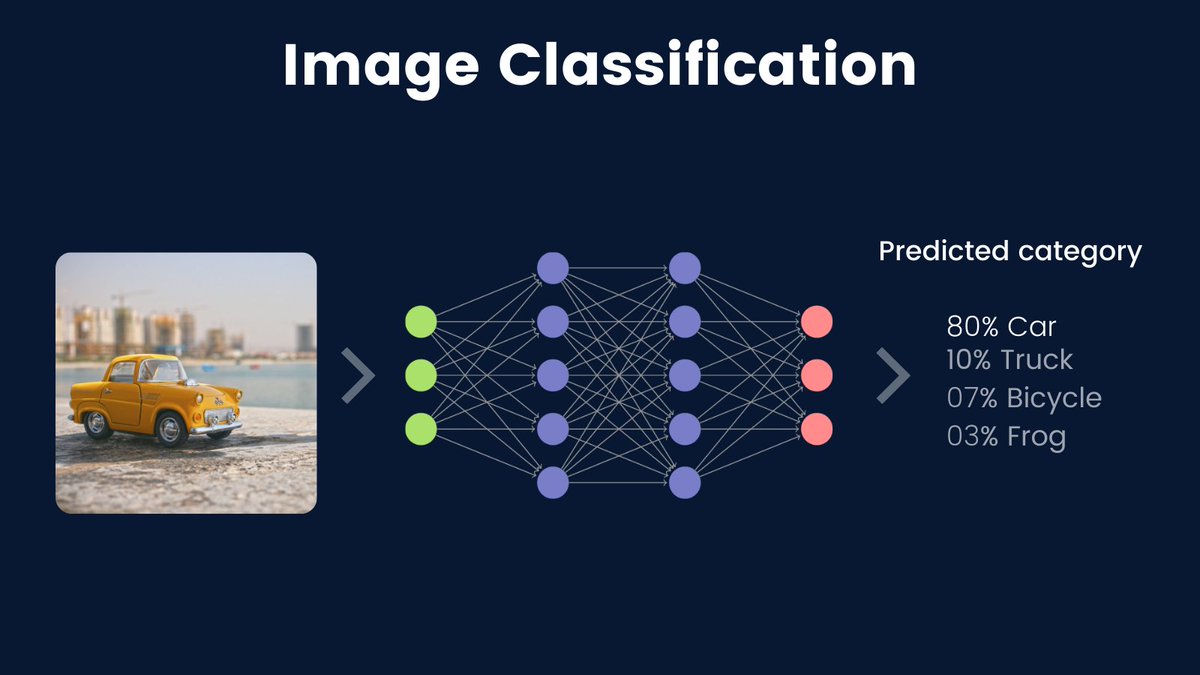
The image you see below is a typical architecture of Convolutional Neural Networks, a.k.a ConvNets.
ConvNets is a neural network type architecture that is mostly used in image recognition tasks.
More about ConvNets 🧵🧵
Image credit: CS 231n
ConvNets is a neural network type architecture that is mostly used in image recognition tasks.
More about ConvNets 🧵🧵
Image credit: CS 231n
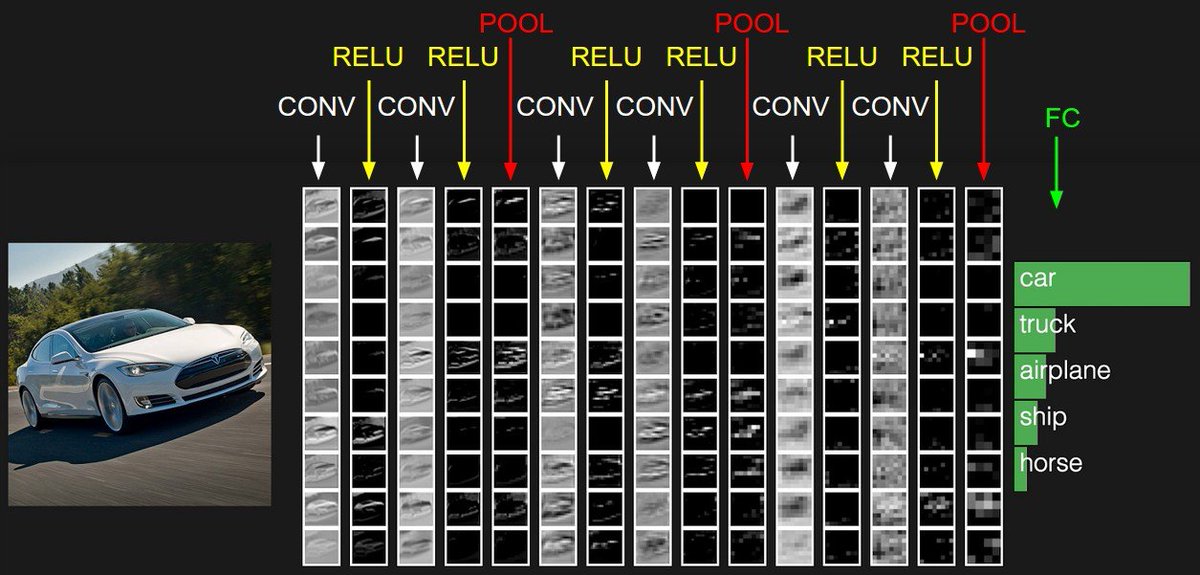
Today, it's a norm to use ConvNets for most recognition tasks such as image classification and object detection.
Although vision transformers are increasingly outperforming most benchmarks in research communities, we probably still have long to go with ConvNets.
Although vision transformers are increasingly outperforming most benchmarks in research communities, we probably still have long to go with ConvNets.
To motivate why ConvNets are so powerful, let's think about what happens when we use fully connected networks for image data.
Fully connected networks or densely connected networks are these kinds of networks where units of any layer are all connected to all other units of the next layer.
Fully connected networks require the input image pixels to be flattened or to be in a 1D dimensional vector.
Fully connected networks require the input image pixels to be flattened or to be in a 1D dimensional vector.
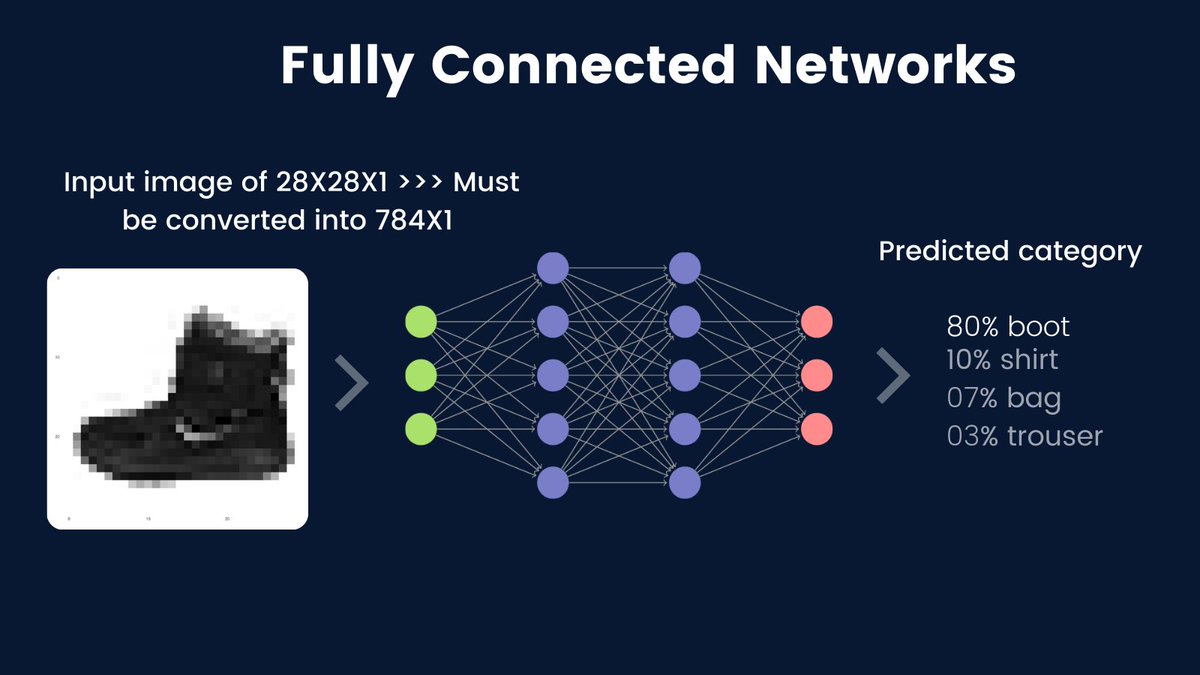
For example, if our input image is a boot (from fashion MNIST) of size 28X28X1, then it must be converted to 784X1.
For Cifar10 with the size of 32X32X3, the input 1D vector must be 3072X1.
For Cifar10 with the size of 32X32X3, the input 1D vector must be 3072X1.
Flattening the input images poses some challenges to the network.
As a consequence, the network can not preserve the spatial features of the images. Also, the network ends up having too many parameters which is not an advantage at all.
As a consequence, the network can not preserve the spatial features of the images. Also, the network ends up having too many parameters which is not an advantage at all.

Now we know why we don't see fully connected layers used for image recognition. It's their inability to learn spatial features from the images.
And that's exactly why we needed to have a network that works well on images. Why? Visual datasets are so abundant nowadays...
And that's exactly why we needed to have a network that works well on images. Why? Visual datasets are so abundant nowadays...
The first Convnets architecture was LeNet-5 by @ylecun. LeNet-5 was used for document recognition in 1998.
yann.lecun.com/exdb/publis/pd…
yann.lecun.com/exdb/publis/pd…
Most architectures that followed looked exactly like LeNet-5 except that they were bigger(like AlexNet that won Imagenet Challenge 2012), or introduced some other tweaks.
And it's after 2012 that people become interested in ConvNets and deep learning in general.
Image: LeNet-5
And it's after 2012 that people become interested in ConvNets and deep learning in general.
Image: LeNet-5

Now that we understand where this thing started, let's discuss the 3 main components of a typical ConvNets that are:
◆Convolution layers
◆Pooling layers
◆Fully connected layers
◆Convolution layers
◆Pooling layers
◆Fully connected layers
1. Convolution layers
Convolution layers are the main part of ConvNets. They contain filters (with learnable weights) for extracting features in images.
ConvNets are also named after a convolution operation as the name implies.
Convolution layers are the main part of ConvNets. They contain filters (with learnable weights) for extracting features in images.
ConvNets are also named after a convolution operation as the name implies.
A convolutional layer performs an elementwise dot product between input image pixels and each unique filter.
The output of convolution layers is called activation maps or feature maps.
The below image illustrates the convolution operation well.
Credit: Cs230 Cheatsheet
The output of convolution layers is called activation maps or feature maps.
The below image illustrates the convolution operation well.
Credit: Cs230 Cheatsheet

This one can be much more intuitive.
ConvNets can be trained with gradient descent. The magical thing about them is that they can automatically determine the appropriate filters that are right for the input image.
More concretely, during the training, the filter values are updated (just like weights are in fully connected networks).
At each step of the training, and as images are being fed into ConvNets, the values of each filter are updated slowly towards the values that minimize the loss/cost function.
Before we talk about pooling layers,let's talk about the typical hyperparameters of convolution layer.
Before we talk about pooling layers,let's talk about the typical hyperparameters of convolution layer.
A convolution layer has 5 main hyperparameters:
◆A number of filters that is also equivalent to the number of output activation maps. There is no proper guide on how many filters you should have but they are typically doubled layer after a layer like 32, 64, 128, 256.
◆A number of filters that is also equivalent to the number of output activation maps. There is no proper guide on how many filters you should have but they are typically doubled layer after a layer like 32, 64, 128, 256.
◆The size of the filter that is usually (3,3) or (5,5) for most tasks. Small sizes are usually better.
◆Stride which denotes the number of pixels that the filter should shift after each convolution operation. A default stride is 1 and it works pretty great.
◆Stride which denotes the number of pixels that the filter should shift after each convolution operation. A default stride is 1 and it works pretty great.
◆Padding: without padding, the pixels at the borderline of the image can not undergo convolution.
We use padding to conserve those pixels and it leads to better performance. The commonly used padding type is zero padding, where we add zeros at the outer part of the image.
We use padding to conserve those pixels and it leads to better performance. The commonly used padding type is zero padding, where we add zeros at the outer part of the image.
◆The last important hyperparameter is the activation function. A convolution is a linear operation. We need some form of non-linearity to prevent the network from being a linear classifier.
A commonly used activation in Conv layers is ReLU. It works great & it trains faster.
A commonly used activation in Conv layers is ReLU. It works great & it trains faster.
So far we have only been talking about 2D convolution, but there is 1D and 3D convolution as well.
1D convolution is used in time series and text tasks, whereas 3D convolution is used in video recognition and volumetric data such as medical scans.
1D convolution is used in time series and text tasks, whereas 3D convolution is used in video recognition and volumetric data such as medical scans.
That's enough about convolution layers. Most deep learning tools have a concise implementation of convolution.
Refer to this image for its implementation in TensorFlow and PyTorch.
Refer to this image for its implementation in TensorFlow and PyTorch.
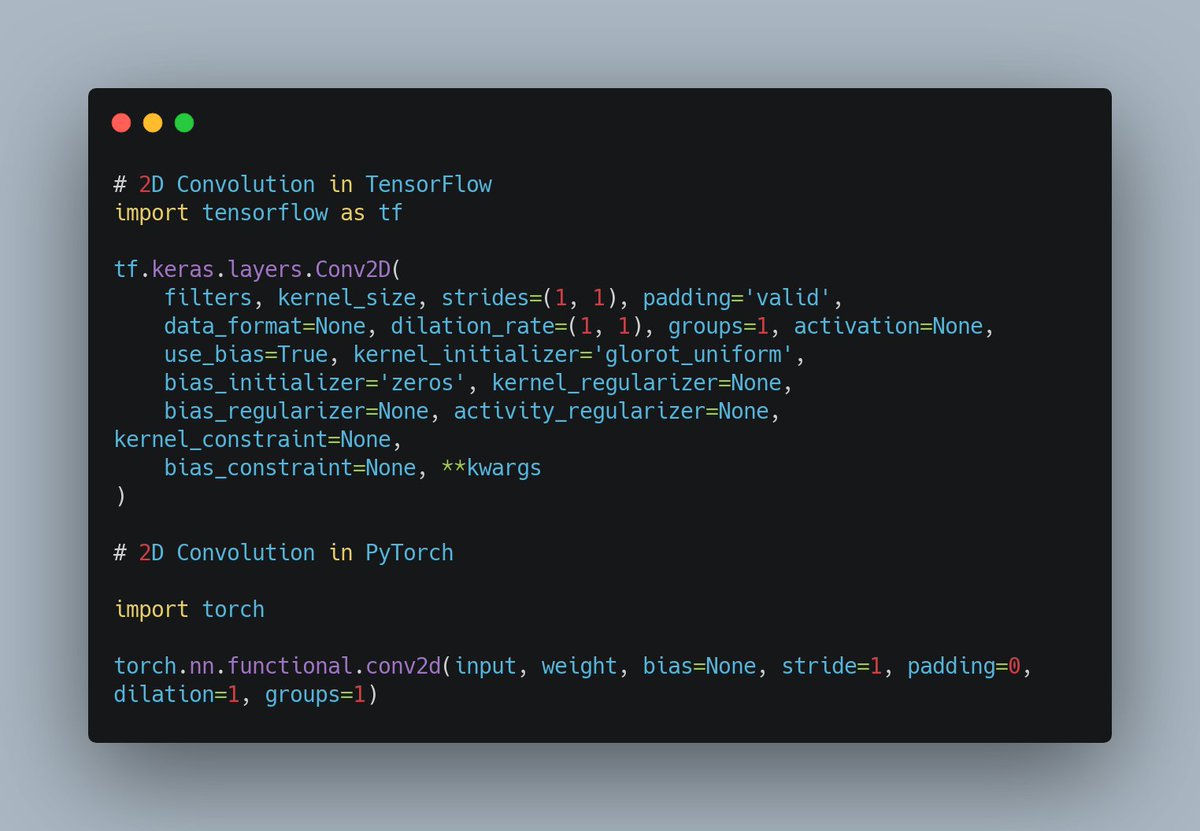
2. Pooling layers
Pooling layers are used for shrinking or downsampling the feature maps produced by convolution layers. This is a crucial thing because, in most tasks, we use a large number of filters, and we increase them layer after layer.
Pooling layers are used for shrinking or downsampling the feature maps produced by convolution layers. This is a crucial thing because, in most tasks, we use a large number of filters, and we increase them layer after layer.
In simple terms, pooling layers reduce the complexity of the network while retaining the best parts of the feature maps.
Using a large number of stride in the Conv layers can also downsample the network, but the advantage of pooling is that it doesn't have parameters.
Using a large number of stride in the Conv layers can also downsample the network, but the advantage of pooling is that it doesn't have parameters.
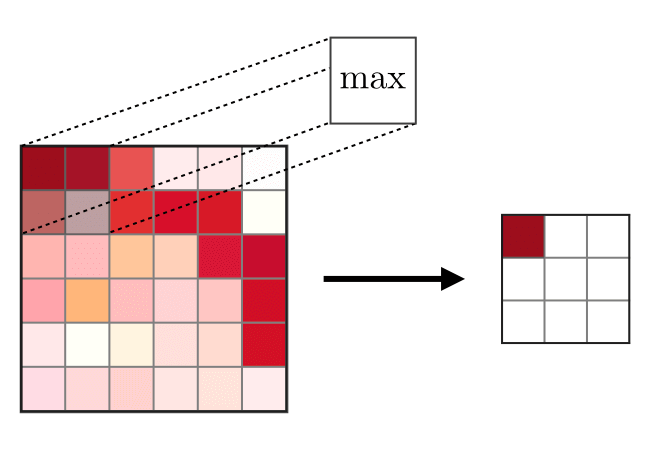
There are two main types of pooling that are max-pooling and average pooling.
Here is how max-pooling is done:
Here is how max-pooling is done:
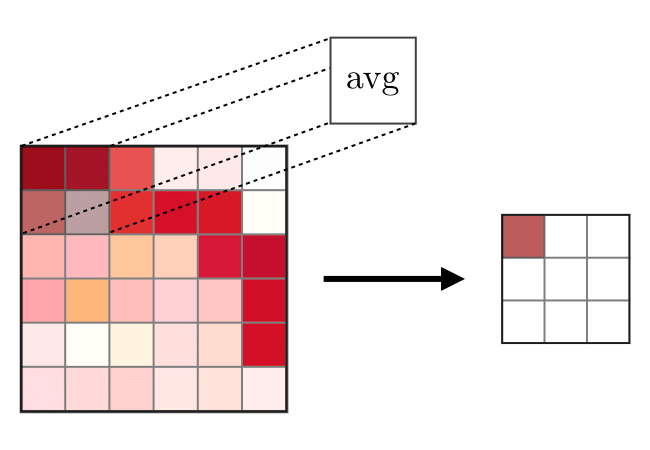
And here is how average pooling is done.
Images: CS 230(links at the end)
Images: CS 230(links at the end)
3. Fully connected layers
We have extracted features in images, downsampled them to reduce network complexity and hence to train faster, but how do we do the actual recognition?
Fully connected layers are used for classification purposes.
We have extracted features in images, downsampled them to reduce network complexity and hence to train faster, but how do we do the actual recognition?
Fully connected layers are used for classification purposes.
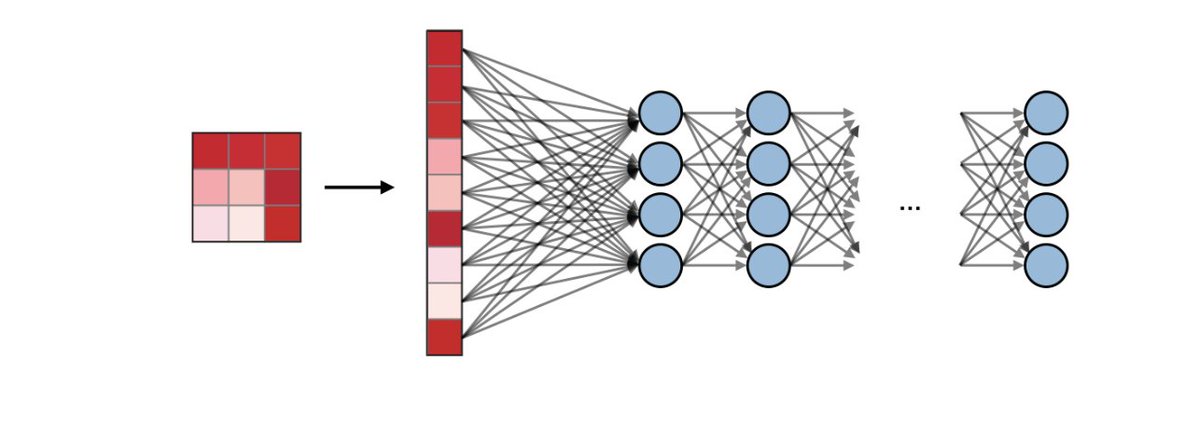
Usually, the number of the fully connected layer is between 1-3. The most important thing to care about here is the last layer.
The number of units in the last layer should be equivalent to the number of classes in classification problems if activated by softmax.
This is the end of the thread that was about convolutional neural networks. To summarize, ConvNets are mostly used in image recognition tasks.
They are made of 3 main components:
◆Convolution layers
◆Pooling layers
◆Fully connected layers
They are made of 3 main components:
◆Convolution layers
◆Pooling layers
◆Fully connected layers
Here are references for used illustrations and for further reading:
◆CNN Explainer: poloclub.github.io/cnn-explainer/
◆CS 230 CNN cheatsheet: stanford.edu/~shervine/teac…
◆CNN Explainer: poloclub.github.io/cnn-explainer/
◆CS 230 CNN cheatsheet: stanford.edu/~shervine/teac…
Thanks for reading.
I actively write about machine learning with the goal of simplifying things.
If you found the thread helpful, you are welcome to retweet or share it with anyone who you think might benefit from reading it.
Follow @Jeande_d for more ML ideas!
I actively write about machine learning with the goal of simplifying things.
If you found the thread helpful, you are welcome to retweet or share it with anyone who you think might benefit from reading it.
Follow @Jeande_d for more ML ideas!
• • •
Missing some Tweet in this thread? You can try to
force a refresh