Hi,
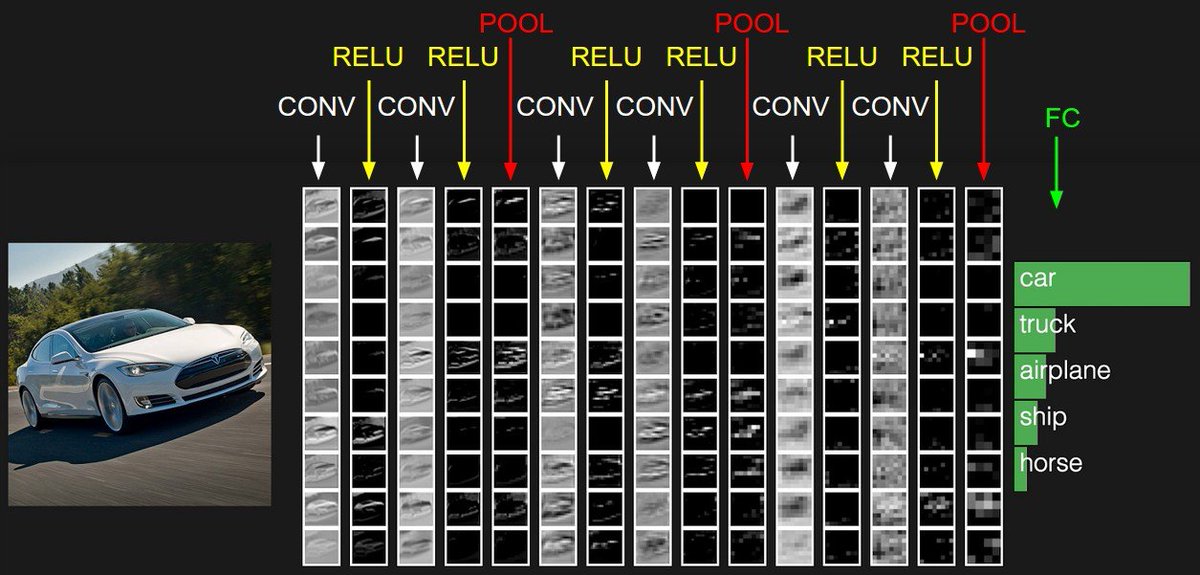
The number of layers depends on the size of the dataset, but there is no way to know the right number of layers although it's somewhere between 1-10 for an initial trial at least.
The number of layers depends on the size of the dataset, but there is no way to know the right number of layers although it's somewhere between 1-10 for an initial trial at least.
https://twitter.com/Jeeva_G/status/1466705828468064259
Everything in deep networks is not clearly predefined. It's all experimenting, experimenting, and experimenting.
ReLU activation is a good starting point always. You can later try other non-saturating activations like SeLU, ELU, etc, but avoid using sigmoid or Tanh.
ReLU activation is a good starting point always. You can later try other non-saturating activations like SeLU, ELU, etc, but avoid using sigmoid or Tanh.
The common pattern in convolution layers is to double the filters, layer after layer, like 16, 32, 64... but again, this is not guaranteed to work well. The size of filters is usually 3X3, or 5X5.
The pooling size is usually 2 by 2.
The pooling size is usually 2 by 2.
Nowadays, unless you want to do some self-experimentation to learn how hyperparameter plays with another, it's safe to use existing architectures (like ResNet) than trying to build your own from scratch.
Most new architectures build on the existing ones and improve their performance or reduce the size, or introduce some little tweaks.
As you can imagine, that's all experimentation.
As you can imagine, that's all experimentation.
This is at least the reason why most things work but they are not clearly understood why & how they work.
Ex: We know batch normalization helps train faster and can lead to better performance, but we don't understand what it means that it 'reduces the internal covariate shift'.
Ex: We know batch normalization helps train faster and can lead to better performance, but we don't understand what it means that it 'reduces the internal covariate shift'.
Your question is very broad. And thus, my response may not be enough.
But if all you want is to build something that works, take an existing thing that works, and customize it on your dataset. That said though, you still have to experiment, experiment, and experiment.
But if all you want is to build something that works, take an existing thing that works, and customize it on your dataset. That said though, you still have to experiment, experiment, and experiment.
• • •
Missing some Tweet in this thread? You can try to
force a refresh