
Logging in #Python is something I want to master. So, starting #30DaysOfLogging from tomorrow.
Time to go from Zero(almost) To Hero.
Time to go from Zero(almost) To Hero.
#Day1 Basics Of Logging
1. We need logging to tell us what's happening in our code
2. Python has an inbuilt logging module which can be imported
3. DEBUG, INFO, WARNING, ERROR & CRITICAL are the level of logging available.
4. WARNING is the default logging level
#100DaysOfCode
1. We need logging to tell us what's happening in our code
2. Python has an inbuilt logging module which can be imported
3. DEBUG, INFO, WARNING, ERROR & CRITICAL are the level of logging available.
4. WARNING is the default logging level
#100DaysOfCode

#Day2
The whole purpose of logging is to be able to write events to a file. This is how you can do it
If you are Python Version > 3.9 then you can use the logging.basicConfig
#100DaysOfCode #Python
The whole purpose of logging is to be able to write events to a file. This is how you can do it
If you are Python Version > 3.9 then you can use the logging.basicConfig
#100DaysOfCode #Python

If you are on a version lower than 3.9 then the encoding option is not available in basicConfig and you can use the alternate option

#Day3 Formatting Log Messages & Default Format
We can customize the format in which log is displayed
>> logging.basicConfig(format="") allows you to set what you want to see in the log
>> The default format i.e. if you do not set any format is as shown below
#100DaysOfCode
We can customize the format in which log is displayed
>> logging.basicConfig(format="") allows you to set what you want to see in the log
>> The default format i.e. if you do not set any format is as shown below
#100DaysOfCode

#Day4
Various possible attributes available for format are as below
> You can combine them to generate logs as suitable for your application
> Logging is optimized to use %s strings over f-strings
e.g. logging.basicConfig(format='%(asctime)s-%(name)s')
#100DaysOfCode #Python
Various possible attributes available for format are as below
> You can combine them to generate logs as suitable for your application
> Logging is optimized to use %s strings over f-strings
e.g. logging.basicConfig(format='%(asctime)s-%(name)s')
#100DaysOfCode #Python

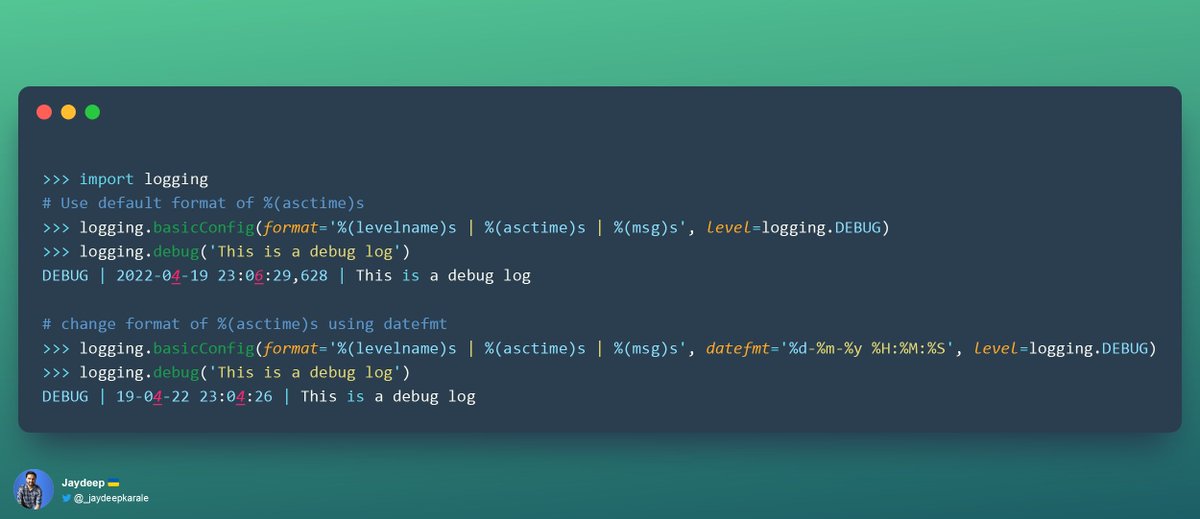
Day 5 :
>> Continuing with formatting of log outputs the date format displayed in the log using %(asctime)s can be altered using the datefmt argument
>> The format of the datefmt argument is the same as supported by time.strftime() [docs.python.org/3/library/time…]
#100DaysOfCode
>> Continuing with formatting of log outputs the date format displayed in the log using %(asctime)s can be altered using the datefmt argument
>> The format of the datefmt argument is the same as supported by time.strftime() [docs.python.org/3/library/time…]
#100DaysOfCode
Day 6:
#Python Logging module components explained ✅
Example of all logging modules combine 🎯
#100DaysOfCode
#Python Logging module components explained ✅
Example of all logging modules combine 🎯
#100DaysOfCode


Day 7: Using a config file for
Having a config file with all components of the logging file is ideal.
It offers:
>> Single point to configure logs, their handlers & their format
>> Ability for non-coders to change the log formats
Having a config file with all components of the logging file is ideal.
It offers:
>> Single point to configure logs, their handlers & their format
>> Ability for non-coders to change the log formats


Day 7:
Since Python 3.2 the config file format has been moved to a YAML which we will see in the coming days
Since Python 3.2 the config file format has been moved to a YAML which we will see in the coming days
Day 8: A dive into various log handlers which with the help of 1. Have a format in which the log is displayed 2. The level of logs to be displayed decide where the log is written

✅StreamHandler >> Writes to the console
✅FileHandler >> Writes to a file on the disk
are the most common types of handlers used.
Below code snippet shows usage of both.
>> Error logs & above are written to a file
>> All logs are written to the console
#100DaysOfCode
✅FileHandler >> Writes to a file on the disk
are the most common types of handlers used.
Below code snippet shows usage of both.
>> Error logs & above are written to a file
>> All logs are written to the console
#100DaysOfCode

Day 9: Implementing a SMTPHandler i.e. sending logs directly to email.
>> devanswers.co/create-applica… --> Use this to create an app specific password if you use gmail
#100DaysOfCode
>> devanswers.co/create-applica… --> Use this to create an app specific password if you use gmail
#100DaysOfCode

Day10:
>> the logging.debug(), info(), etc signature shows a **kwargs parameter.
It can take in 3 arguments
1⃣ exc_info to display traceback data
2⃣ stack_info to display traceback data
3⃣ extra to display use custom formatter attribute
#100DaysOfCode
>> the logging.debug(), info(), etc signature shows a **kwargs parameter.
It can take in 3 arguments
1⃣ exc_info to display traceback data
2⃣ stack_info to display traceback data
3⃣ extra to display use custom formatter attribute
#100DaysOfCode



Correction:
Since Python 3.8 there is a 4th argument available
4⃣ stacklevel which defaults to 1. If greater than 1, the corresponding number of stack frames are skipped when computing the line number and function name set in the LogRecord created for the logging event
Since Python 3.8 there is a 4th argument available
4⃣ stacklevel which defaults to 1. If greater than 1, the corresponding number of stack frames are skipped when computing the line number and function name set in the LogRecord created for the logging event
Day 11:
Looking to add more information to your logs like traceback ? Here is how we can do it.
#Python #100DaysOfCode
Looking to add more information to your logs like traceback ? Here is how we can do it.
#Python #100DaysOfCode

Day 12:
Why not add some colors to the #Python logs ?
Use the coloredlogs packages to achieve it.
> Logging to console & each log level has a distinct color
#100DaysOfCode
Why not add some colors to the #Python logs ?
Use the coloredlogs packages to achieve it.
> Logging to console & each log level has a distinct color
#100DaysOfCode


Day 13:
You can use a #Dictionary to store logging config.
>> Notice the blank logger name to set the module name as the name of the logger.
#100DaysOfCode #Python #30DaysOfLogging
You can use a #Dictionary to store logging config.
>> Notice the blank logger name to set the module name as the name of the logger.
#100DaysOfCode #Python #30DaysOfLogging

Day 14:
> The YAML is the preferred way of Python to store logging configuration
> A sample implementation is shown below
> Code available at my repo github.com/jaydeepkarale/…
#100DaysOfCode #Python #30DaysOfLogging
> The YAML is the preferred way of Python to store logging configuration
> A sample implementation is shown below
> Code available at my repo github.com/jaydeepkarale/…
#100DaysOfCode #Python #30DaysOfLogging

Day 15:
> Python logs are largely meant for humans but sometimes we may need to pass it to log analytics platforms as SPLUNK, Logstash, etc. These platforms consume data in JSON format
> We can use the python-json-logger module to output logs in JSON format
#100DaysOfCode
> Python logs are largely meant for humans but sometimes we may need to pass it to log analytics platforms as SPLUNK, Logstash, etc. These platforms consume data in JSON format
> We can use the python-json-logger module to output logs in JSON format
#100DaysOfCode

Day 16: LoggerAdapter for adding more info to logs
>> The logging module comes with a number of formatters but often you might need to pass additional context info to the logs & display it. This can be done using the LoggerAdapter class
>> The logging module comes with a number of formatters but often you might need to pass additional context info to the logs & display it. This can be done using the LoggerAdapter class
https://twitter.com/_jaydeepkarale/status/1516395787323797517?s=20&t=G7YWqx6qNe1lhB2KZhwLYg
Day 16: In below example
1⃣ Initialize a logger as usual
2⃣ Specify an additional attribute in the formatter
3⃣ We then pass the logger from step #1 & contextual info to LoggerAdapter class
4⃣ The info(), error() & other methods are then called on instance of LoggerAdapter
1⃣ Initialize a logger as usual
2⃣ Specify an additional attribute in the formatter
3⃣ We then pass the logger from step #1 & contextual info to LoggerAdapter class
4⃣ The info(), error() & other methods are then called on instance of LoggerAdapter

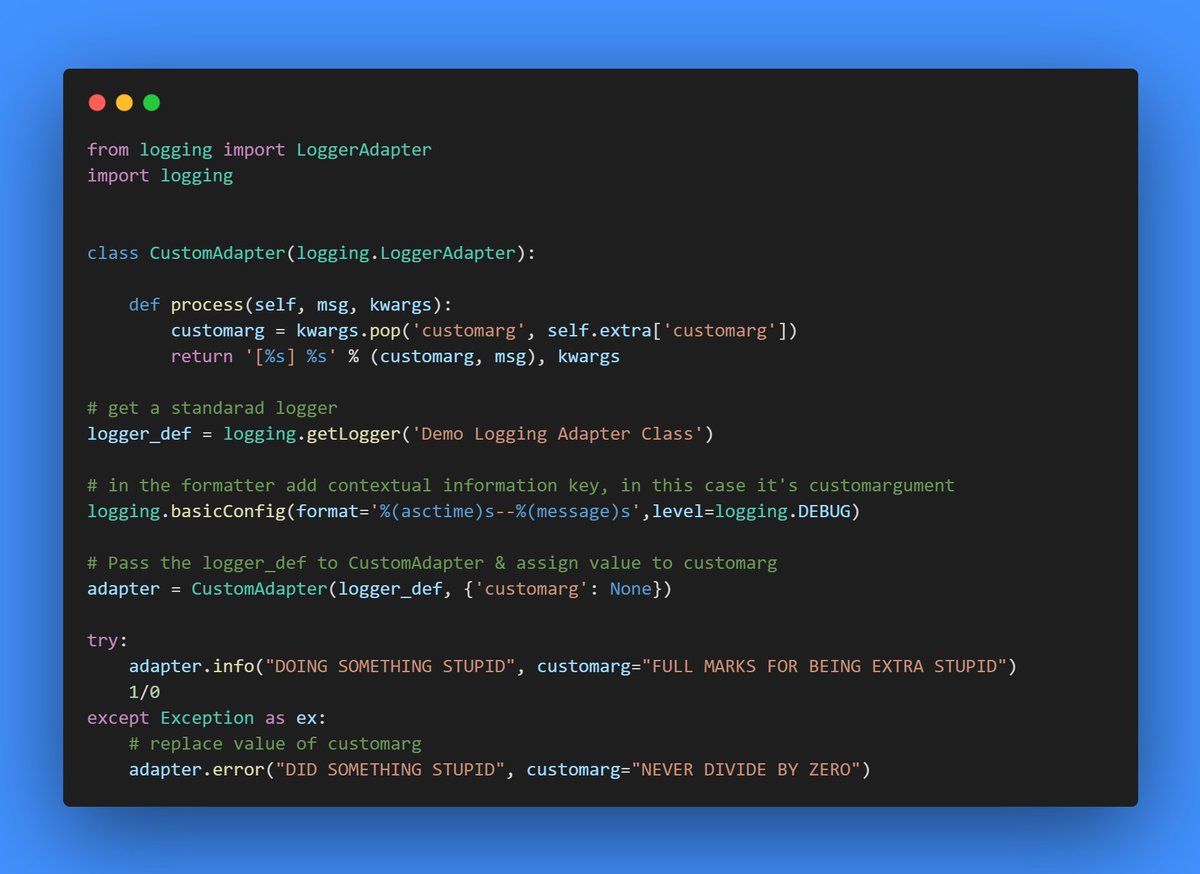
Day17:
>> We can override the process method in the LoggerAdapter class pass contextual/additional information with each log
>> Overriding the process method gives us the ability to pass a unique contextual info with each log
>> We can override the process method in the LoggerAdapter class pass contextual/additional information with each log
>> Overriding the process method gives us the ability to pass a unique contextual info with each log


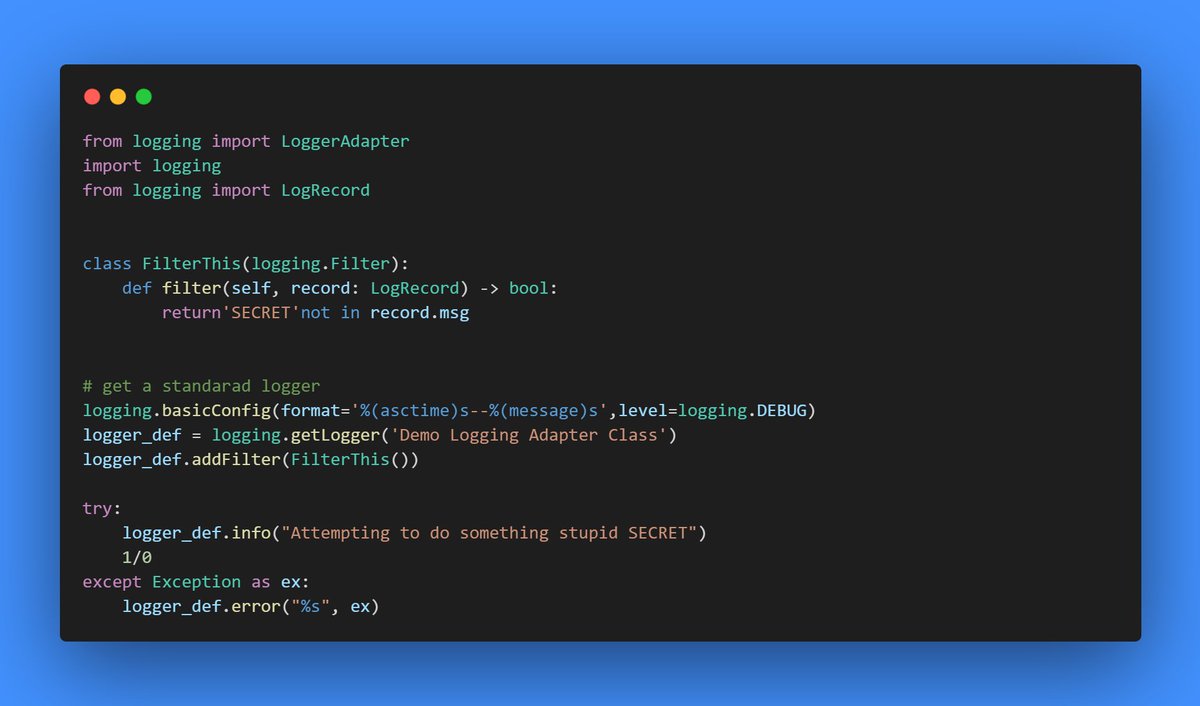
Day 18: Filtering Python Logs
>> Filters allow you to
> Reject records based on certain criteria
> Add custom info to logs
>> We need to override the logging.Filter & then attach it to handler using .addFilter()
>> Filters allow you to
> Reject records based on certain criteria
> Add custom info to logs
>> We need to override the logging.Filter & then attach it to handler using .addFilter()

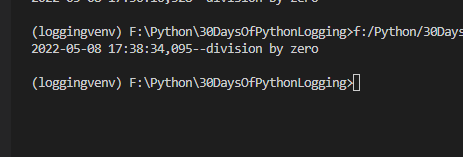
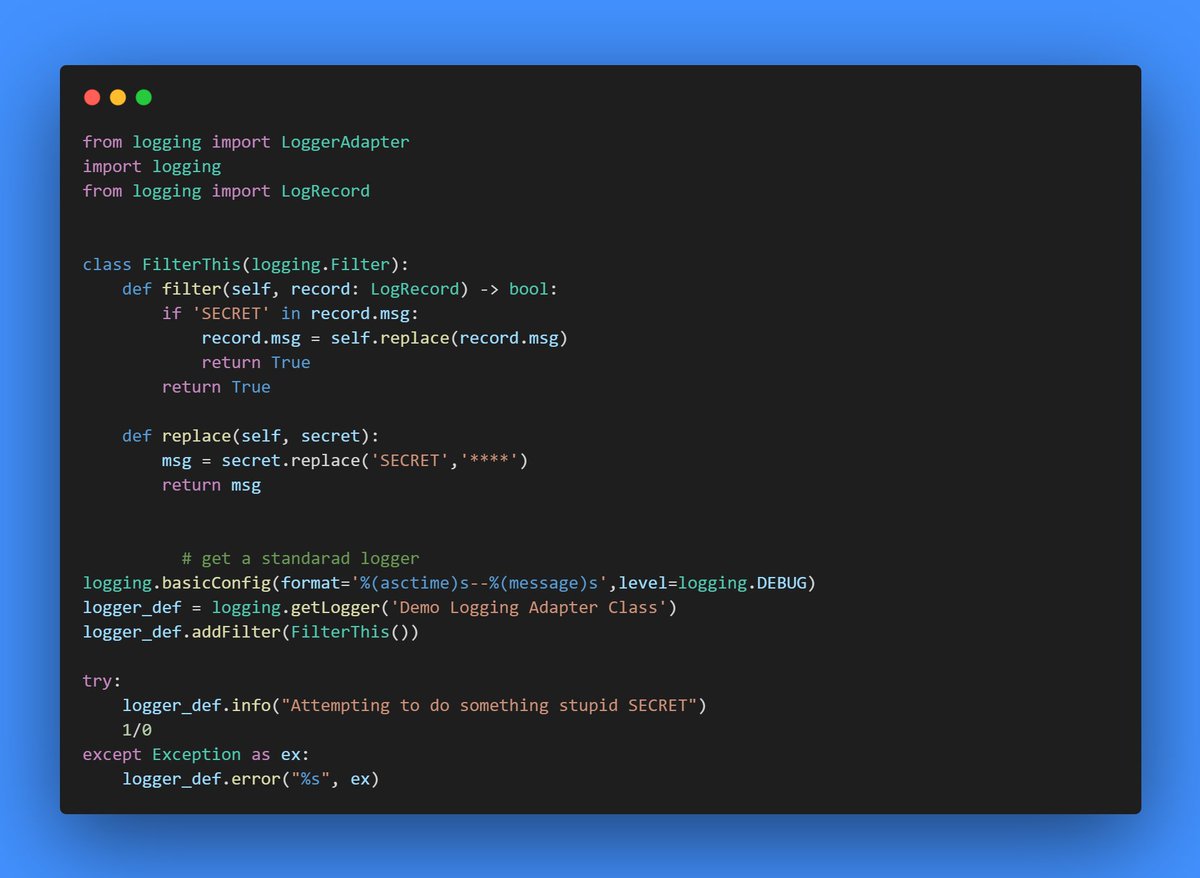
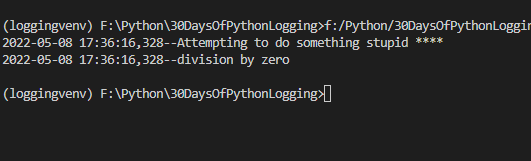
Day 19 Of Python Logging: Filtering
>> Yesterday we saw how we can add filters to logs to prevent certain logs from showing up
>> But what if you need to log to show up but just a part of the log message to be hidden ? Just pass the LogRecord.msg to a new function to do the job
>> Yesterday we saw how we can add filters to logs to prevent certain logs from showing up
>> But what if you need to log to show up but just a part of the log message to be hidden ? Just pass the LogRecord.msg to a new function to do the job

Day 20 Of Python Logging:
>> Logging module is actually implemented in a thread-safe way.
>> Under the hood the logging module uses threading.RLock()
>> Lock vs RLock (stackoverflow.com/questions/2288…)
#100DaysOfCode
>> Logging module is actually implemented in a thread-safe way.
>> Under the hood the logging module uses threading.RLock()
>> Lock vs RLock (stackoverflow.com/questions/2288…)
#100DaysOfCode



Day 21: Logger Class
> Loggers should ALWAYS be instantiated through module-level function logging.getLogger(name)
> The name is potentially a period-separated hierarchical value like foo.bar.baz. The logger name hierarchy is analogous to the Python pkg hierarchy
> Loggers should ALWAYS be instantiated through module-level function logging.getLogger(name)
> The name is potentially a period-separated hierarchical value like foo.bar.baz. The logger name hierarchy is analogous to the Python pkg hierarchy


Day 22:
> error/exception occurring in he logging module methods such as info(), error(), warning() are taken care of by the Handler via the emit() method.
> The emit() calls has a handleError() in Exception block which prints the stack to the console
#100DaysOfCode
> error/exception occurring in he logging module methods such as info(), error(), warning() are taken care of by the Handler via the emit() method.
> The emit() calls has a handleError() in Exception block which prints the stack to the console
#100DaysOfCode




Day 23: a video log about getting started with Python Logging for those who prefer learning by watching videos
#100DaysOfCode
#100DaysOfCode
Day24: RotatingFileHandler() To Create Log Files Of Specified Size
✅ maxBytes controls the file size
✅ backCount controls the number of file of size maxBytes. Default is 0 meaning only 1 file
✅ filename attribute is the filename
#100DaysOfCode #Python
✅ maxBytes controls the file size
✅ backCount controls the number of file of size maxBytes. Default is 0 meaning only 1 file
✅ filename attribute is the filename
#100DaysOfCode #Python



Day 25: TimedRotatingFileHandler()
>> Rotate log files after certain time interval
>> Rotated files are automatically appended with a timestamp
>> Has a rich set of arguments to control the behaviour & output if the Handler.
#100DayOfCode #Python #MachineLearning #DataScience
>> Rotate log files after certain time interval
>> Rotated files are automatically appended with a timestamp
>> Has a rich set of arguments to control the behaviour & output if the Handler.
#100DayOfCode #Python #MachineLearning #DataScience




• • •
Missing some Tweet in this thread? You can try to
force a refresh









