
Connaissez-vous #pyCaret ?
Si ce n'est pas le cas, je vous conseille vivement d'y jeter un oeil
Cette bibliothèque vous permet de tester facilement les performances des principaux algorithmes de Machine Learning
illustration >
Si ce n'est pas le cas, je vous conseille vivement d'y jeter un oeil
Cette bibliothèque vous permet de tester facilement les performances des principaux algorithmes de Machine Learning
illustration >
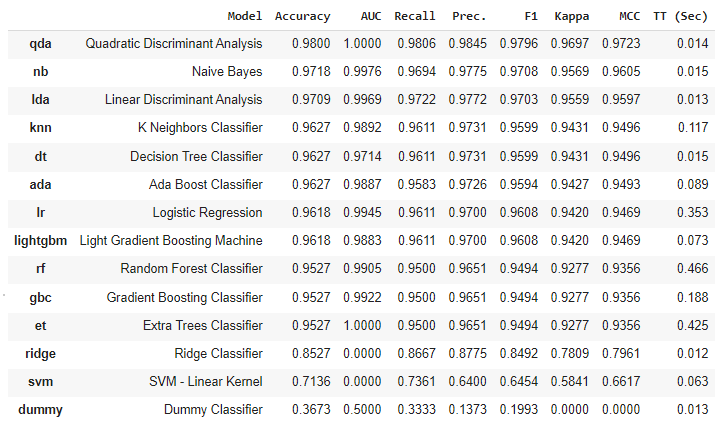
Test sur la classification du dataset IRIS 

on obtient ces résultats :
L'intégration de cette bibliothèque est possible avec toutes les bibliothèques standards de Machine Learning : #Scikit-Learn, #XGBoost, #LightGBM, #spaCy, ...
• • •
Missing some Tweet in this thread? You can try to
force a refresh





