
Sitting in with @Suzzicks, and @ruthburr with @iPullRank’s webinar on Entity #SEO. Expect some annoying tweets from me.
bit.ly/3JdfI4U twitter.com/i/web/status/1…
bit.ly/3JdfI4U twitter.com/i/web/status/1…
❯ 2010 Google acquired Metaweb to get Freebase, then shut down Metaweb
❯ Freebase forms Google’s Knowledge Vault
❯ Google eventually transitioned from Freebase to Wikidata
❯ Wikidata could eventually integrate some legacy Freebase data
❯ Freebase forms Google’s Knowledge Vault
❯ Google eventually transitioned from Freebase to Wikidata
❯ Wikidata could eventually integrate some legacy Freebase data
❯ Schema.org rolled out around the same time in mid-2011, to build the “Semantic Web.”
❯ Ways to describe people, places and things
❯ Before the blockchain, before “Web3” was the Semantic Web with linked data that was actually “Web 3.0”
❯ Ways to describe people, places and things
❯ Before the blockchain, before “Web3” was the Semantic Web with linked data that was actually “Web 3.0”
❯ The Semantic data started out usig RDF, and all the entities were identified by ID
❯ Underpinned by DBPedia and Wikidata/Wikipedia, Yago, Satori, etc.
❯ Before Schema LD+JSON there was RDF and SPARQL
❯ All conceptualized by Time Berners Lee
❯ Underpinned by DBPedia and Wikidata/Wikipedia, Yago, Satori, etc.
❯ Before Schema LD+JSON there was RDF and SPARQL
❯ All conceptualized by Time Berners Lee

❯ Semantic markup makes it easier to identify entities
❯ But what is an entity?
❯ Google uses a “Topic Layer” that takes various ontologies and semantic understandings and us ultimate made up of entities.
❯ An entity ≠ keywords & synonyms
❯ But what is an entity?
❯ Google uses a “Topic Layer” that takes various ontologies and semantic understandings and us ultimate made up of entities.
❯ An entity ≠ keywords & synonyms
❯ An entity is a thing in relationship with other things–@Suzzicks
❯ This relationship between entities helps Google take concepts and relationships in one language and apply them to other languages more accurately
❯ This relationship between entities helps Google take concepts and relationships in one language and apply them to other languages more accurately
❯ This allows you to move away from keywords to using entities to map the concepts on the web rather than langage-based keywords
❯ Google thus can distinguish between “red stoplight” (a traffic signal) vs “stoplight red” (a lipstick color)
❯ Google thus can distinguish between “red stoplight” (a traffic signal) vs “stoplight red” (a lipstick color)
❯ Google understands queries by breaking them into entities
❯ This allows queries to be expanded and related entities with attributes to be discovered
❯ Not only is Google looking to understand queries with entities, they’re also EXPANDING your query with additional entities
❯ This allows queries to be expanded and related entities with attributes to be discovered
❯ Not only is Google looking to understand queries with entities, they’re also EXPANDING your query with additional entities
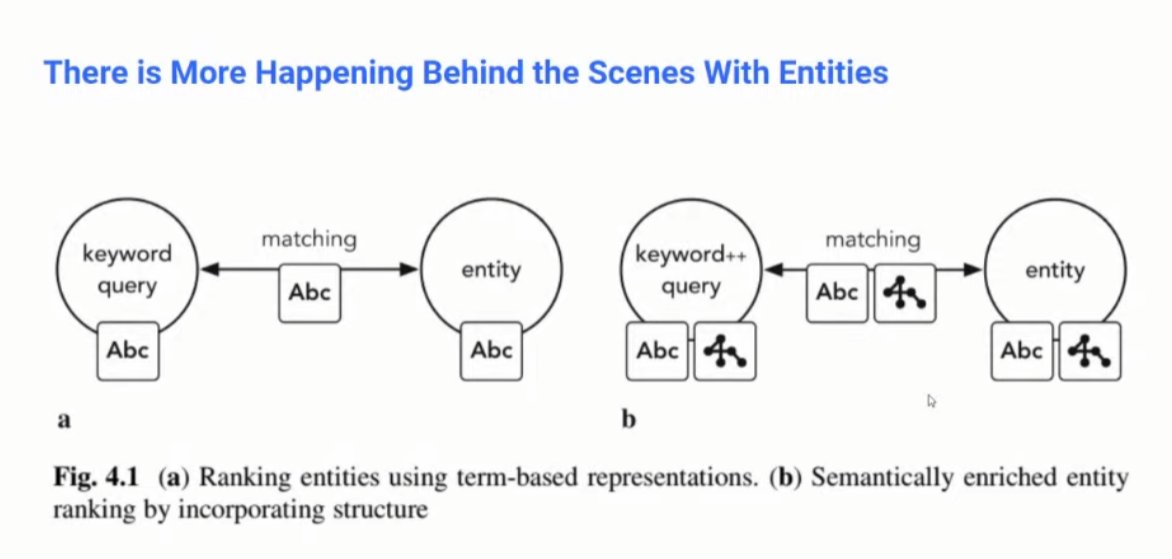
❯ @haahr gave examples of Google stacking and expanding queries in the background.
❯ A series of patents explain this in great depth
❯ A series of patents explain this in great depth
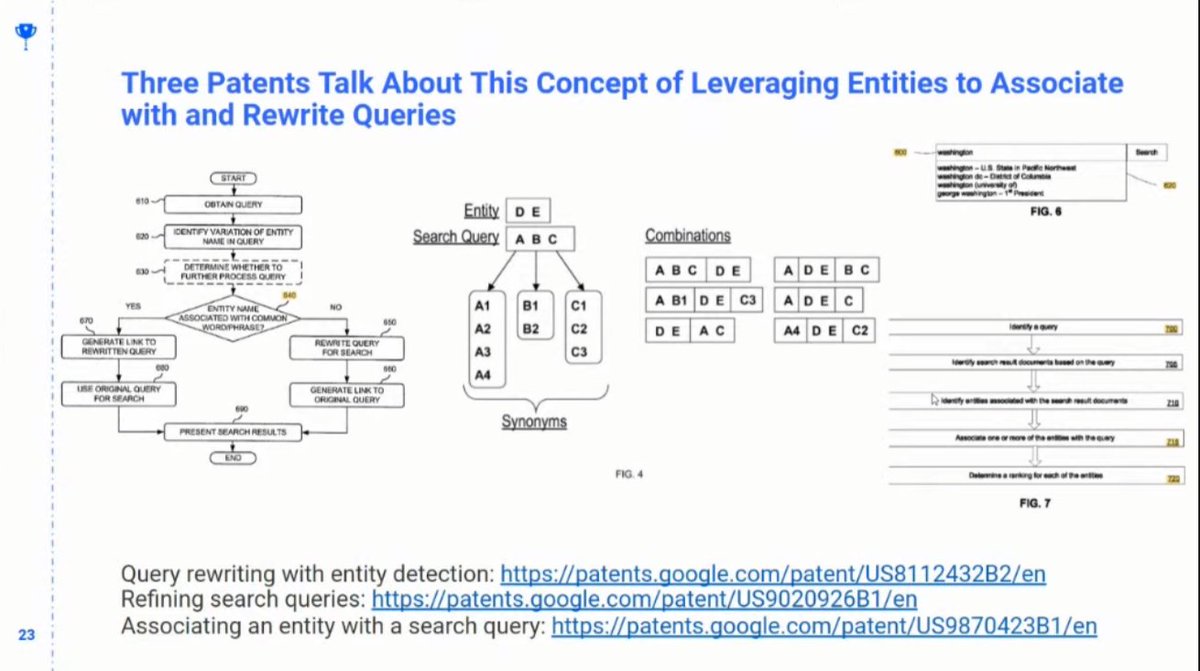
❯ The algorithm isn' t just one thing, it’s a series of scoring functions, the winning search result is an output of the chained scoring functions
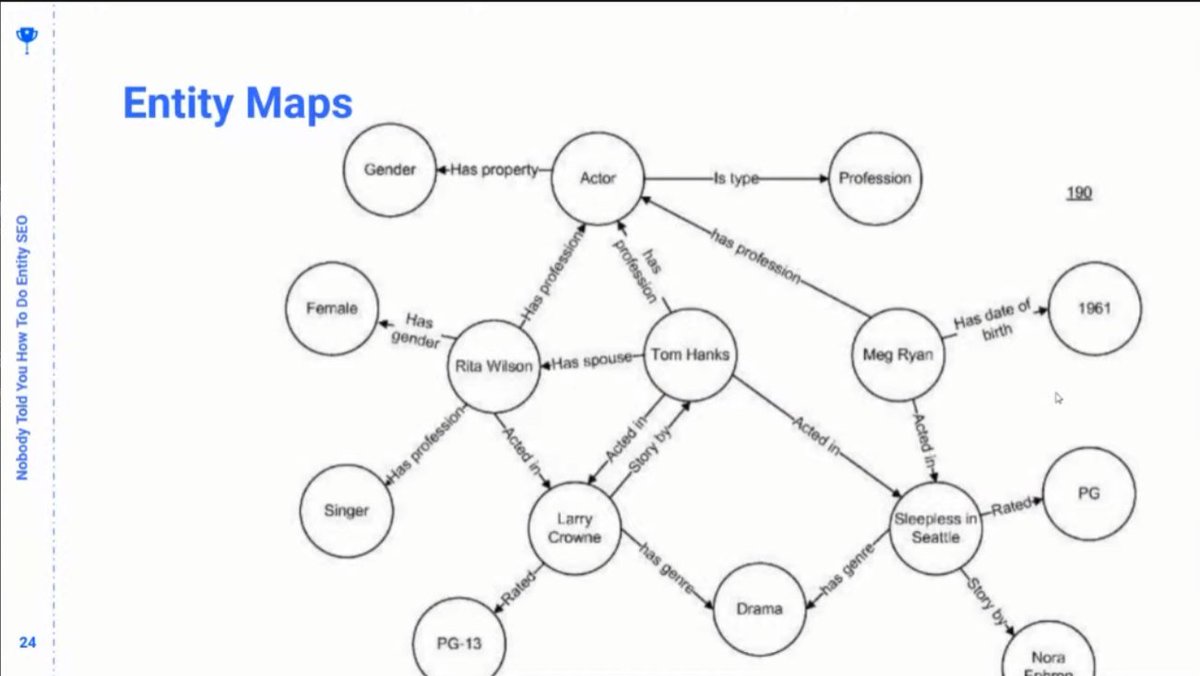
❯ Entity Maps are a topography of entities clustered and connected by relationships and attributes.
❯ Your job as an SEO is to mimic the kind of entity map that Google uses to understand the world. Does your content entity map cohere with the entity map that Google uses?
❯ Your job as an SEO is to mimic the kind of entity map that Google uses to understand the world. Does your content entity map cohere with the entity map that Google uses?
❯ Identify the entity clusters/relationships/attributes that are missing from your website’s entity map so that it is more congruent with Google’s entity map of the world
❯ Map the entities on the top competing sites and yours to identify what’s missing and where to focus time.
❯ Map the entities on the top competing sites and yours to identify what’s missing and where to focus time.
❯ SERP features like People Also Ask and People Also Search and other specific query refinements are actually entity disambiguation tools
❯ When Google looks at entities in queries, it also looks at entities in your content, and also the entities in their own dataset
❯ When Google looks at entities in queries, it also looks at entities in your content, and also the entities in their own dataset

❯ Google can then make inferences of connections between your content and other content across the web because of these entity relationships
❯ It’s not just about the markup, but these relationships can be extracted based on natural language: Subject → Predicate → Object.
❯ It’s not just about the markup, but these relationships can be extracted based on natural language: Subject → Predicate → Object.
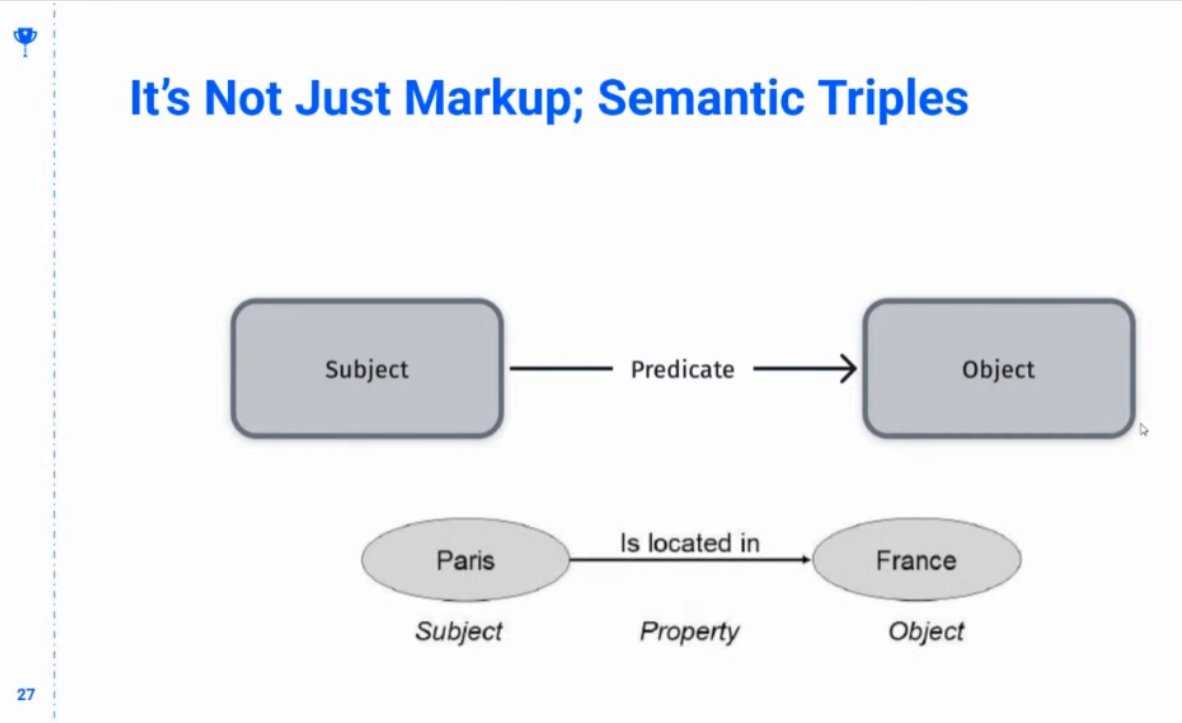
❯ Use explicit semantic triples in your content so that it’s easier to parse. @iPullRank

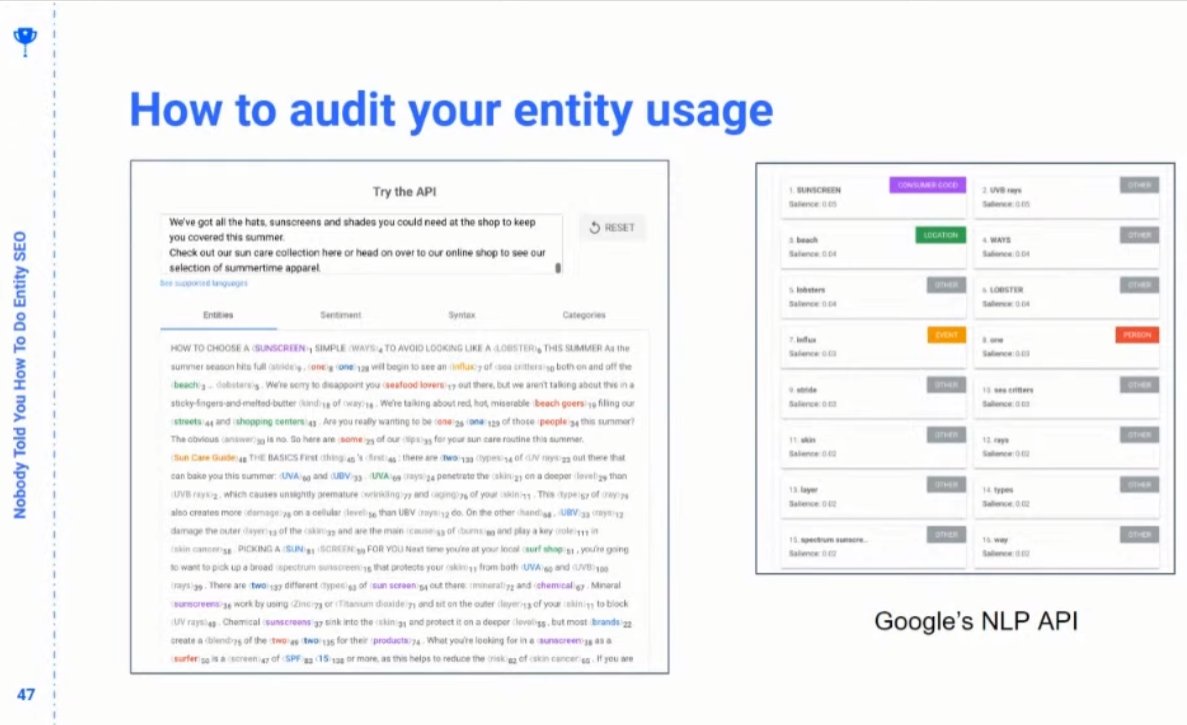
❯ How do you know if Google understands an entity?
❯ Use cloud.google.com/natural-langua… to understand text with named entity recognition
❯ Use cloud.google.com/vision/docs/de… to understand images
❯ Use cloud.google.com/natural-langua… to understand text with named entity recognition
❯ Use cloud.google.com/vision/docs/de… to understand images
❯ Look at the top-ranked sites, and make sure that you use the same entities and achieve similar salience scores as the competitors
❯ The language you use can cause Google to mislable the entities that you expect it to find.
❯ The language you use can cause Google to mislable the entities that you expect it to find.
❯ You want Google to not only find the thing, but find the right kind of thing
❯ Note: Just because Google doesn’t identify a wikidata ID or Wikipedia article in its named entity recognition, doesn’t mean Google doesn’t understand it’s an entity – @ruthburr
❯ Note: Just because Google doesn’t identify a wikidata ID or Wikipedia article in its named entity recognition, doesn’t mean Google doesn’t understand it’s an entity – @ruthburr
❯ Google can also understand the entities featured in images
❯ Use: cloud.google.com/vision/docs/de…
❯ Make sure you’re using meaningful images on your site to provide context and strengthen entity relationships
❯ Make them clear, not esoteric, or vague. Be direct with your images
❯ Use: cloud.google.com/vision/docs/de…
❯ Make sure you’re using meaningful images on your site to provide context and strengthen entity relationships
❯ Make them clear, not esoteric, or vague. Be direct with your images

❯ Also note: There may be holes in Google’s own understanding of the entity map.
❯ You can also help fill the holes in Google’s understanding
❯ If there are industry lists, you need to be on them (not just for backlinks, but to associate your brand with the industry entity)
❯ You can also help fill the holes in Google’s understanding
❯ If there are industry lists, you need to be on them (not just for backlinks, but to associate your brand with the industry entity)
❯ You can also see a lot of entity relationships exposed in Google’s Image search tab
❯ Image searches give you hints of the relationships Google is inferring between entities
❯ If things are showing up that don’t belong you’ll need to work on entity disambiguation
❯ Image searches give you hints of the relationships Google is inferring between entities
❯ If things are showing up that don’t belong you’ll need to work on entity disambiguation

❯ Make sure you’re giving Google all the information you can in specific channels Google trusts, such as Google Business Profiles. Make sure you have all that information filled out
❯ GBP descriptions may not help ranking in local, but they help Google understand your entities
❯ GBP descriptions may not help ranking in local, but they help Google understand your entities
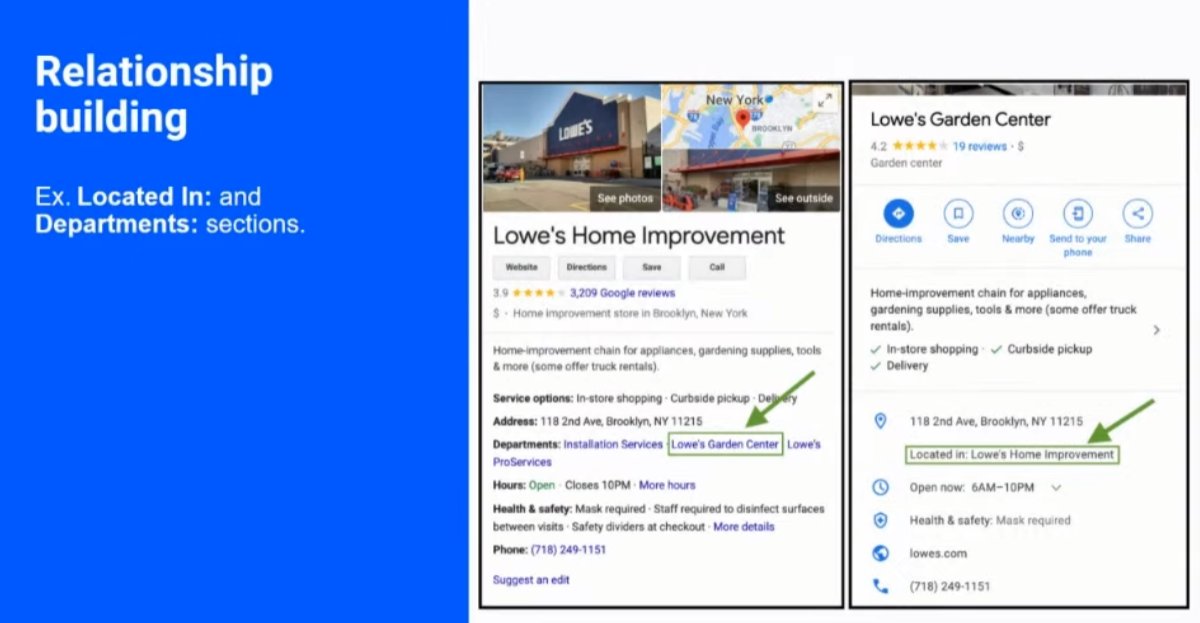
❯ How to ID, build, and strengthen entities
❯ “Just create good content” but what does that mean? That’s bothered me for 10 years! @ruthburr
❯ “Just create good content” but what does that mean? That’s bothered me for 10 years! @ruthburr
❯ You pretty much know the entities you want to rank for in your category
❯ A lot of this you know at a high level and may conflate topics and entities a bit
❯ A lot of this you know at a high level and may conflate topics and entities a bit
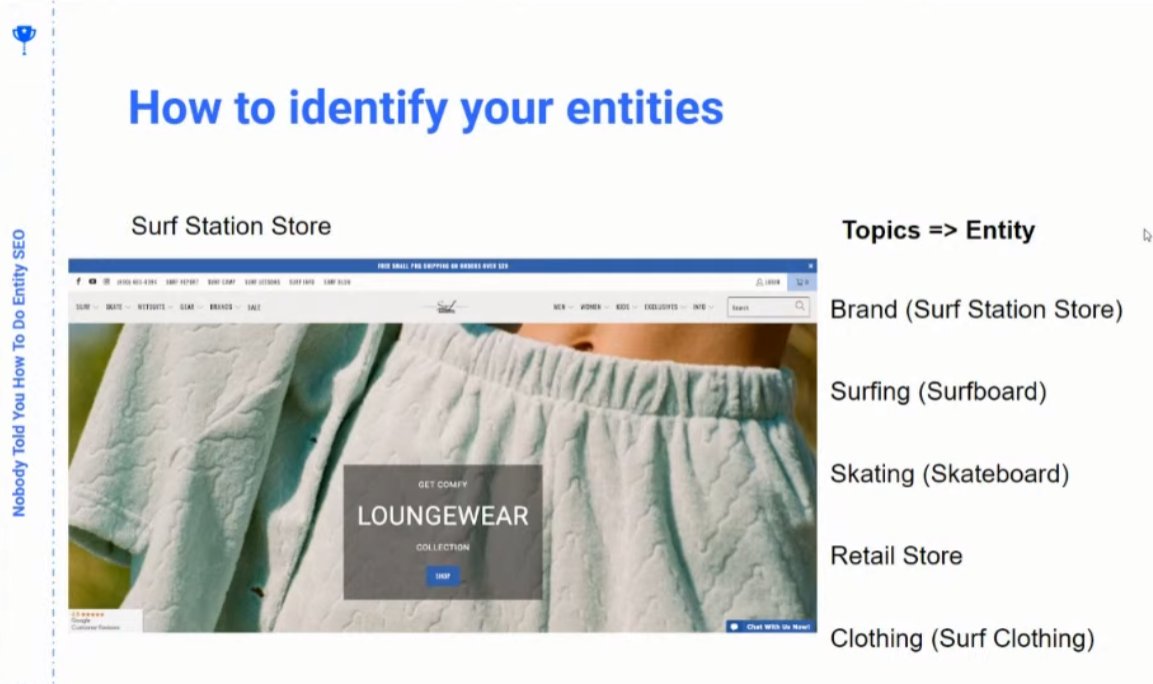
❯ But from there you can get a sense of how Google understands your entities
❯ Googles NLP API
❯ Wikipedia
❯ Knowledge Graph API
❯ Knowledge panels
❯ Googles NLP API
❯ Wikipedia
❯ Knowledge Graph API
❯ Knowledge panels
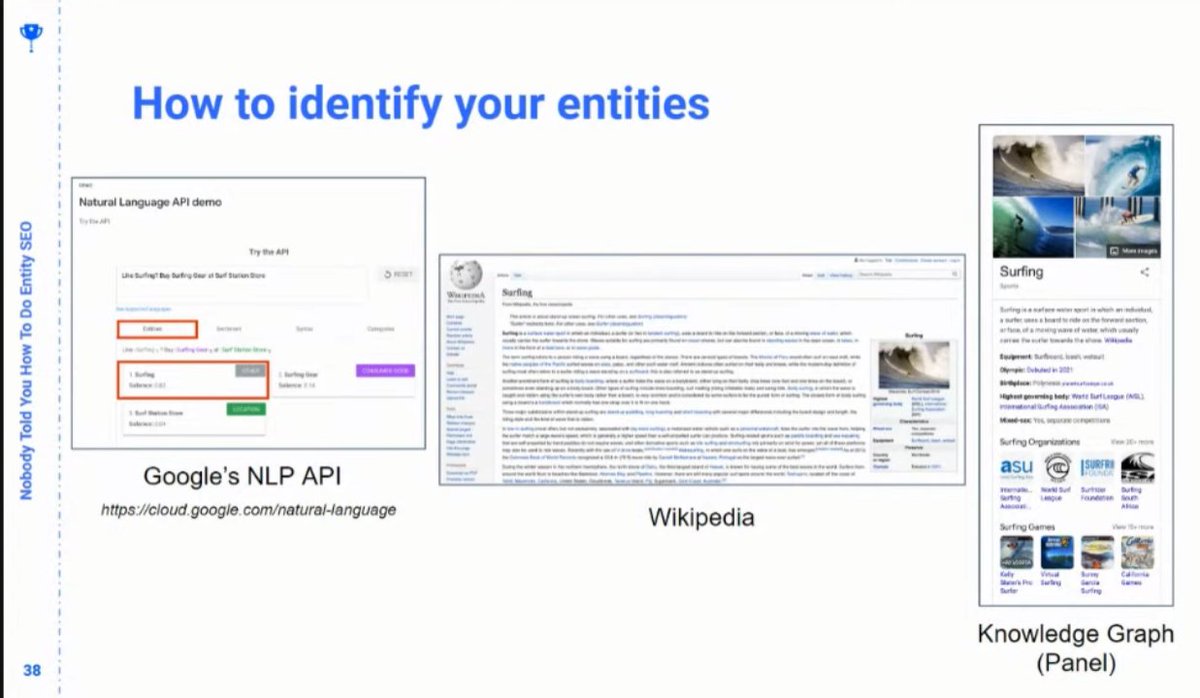
❯ Example: Robots.txt. There’s no Wikipedia page for "Robots.txt", but there is one for "Robots Exclusion Standard"
❯ We’re beyond exact match keywords
❯ When you’re naturally writing a bout a topic you'll naturally fold in proper entities
❯ We’re beyond exact match keywords
❯ When you’re naturally writing a bout a topic you'll naturally fold in proper entities

❯ Look at Wikipedia and Google Trends “Related Topics”
❯ Look at the SERP for the topic, what do the top-ranked pages talk about
❯ Look at the Knowledge Panel, PAA, Top Stories People Also Search, look at navigational chips in shopping SERPs
❯ Look at the SERP for the topic, what do the top-ranked pages talk about
❯ Look at the Knowledge Panel, PAA, Top Stories People Also Search, look at navigational chips in shopping SERPs
❯ Look for commonalities, and repeating themes
❯ “I still really like the hub-and-spoke model, but am currently thinking of it more as a pillar model.” @ruthburr
❯ “I still really like the hub-and-spoke model, but am currently thinking of it more as a pillar model.” @ruthburr
❯ You don’t really want the “Ultimate Guide” content. For an entity-based strategy, you want to know where the related entities need to go and lead to sub-pillar pages
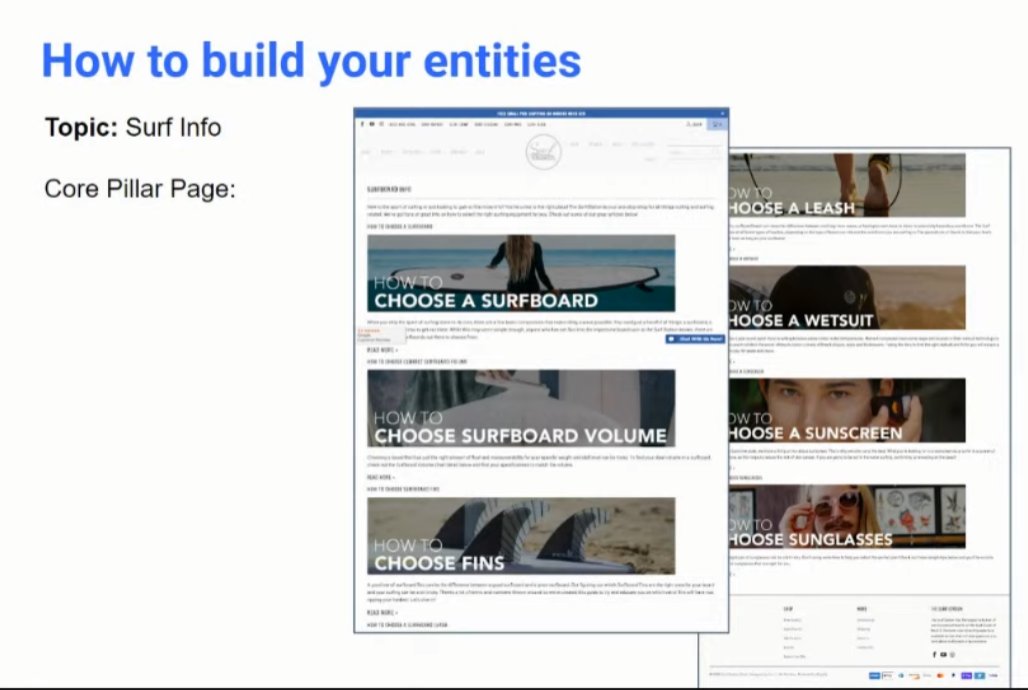
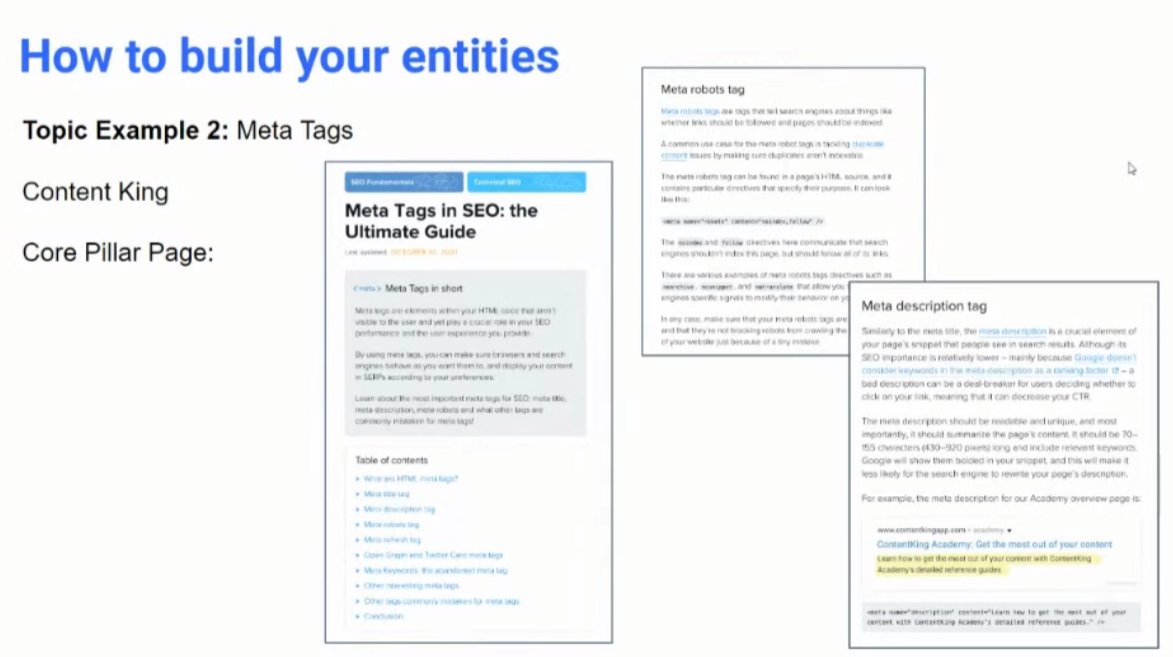
❯ Drill down from the top pillar page and get super specific in the lower pages
❯ It doesn’t matter if they drill all the way down, what matters is whether the searcher is staying
❯ Present the content that makes it easy to go deep or shallow as needed
❯ It doesn’t matter if they drill all the way down, what matters is whether the searcher is staying
❯ Present the content that makes it easy to go deep or shallow as needed
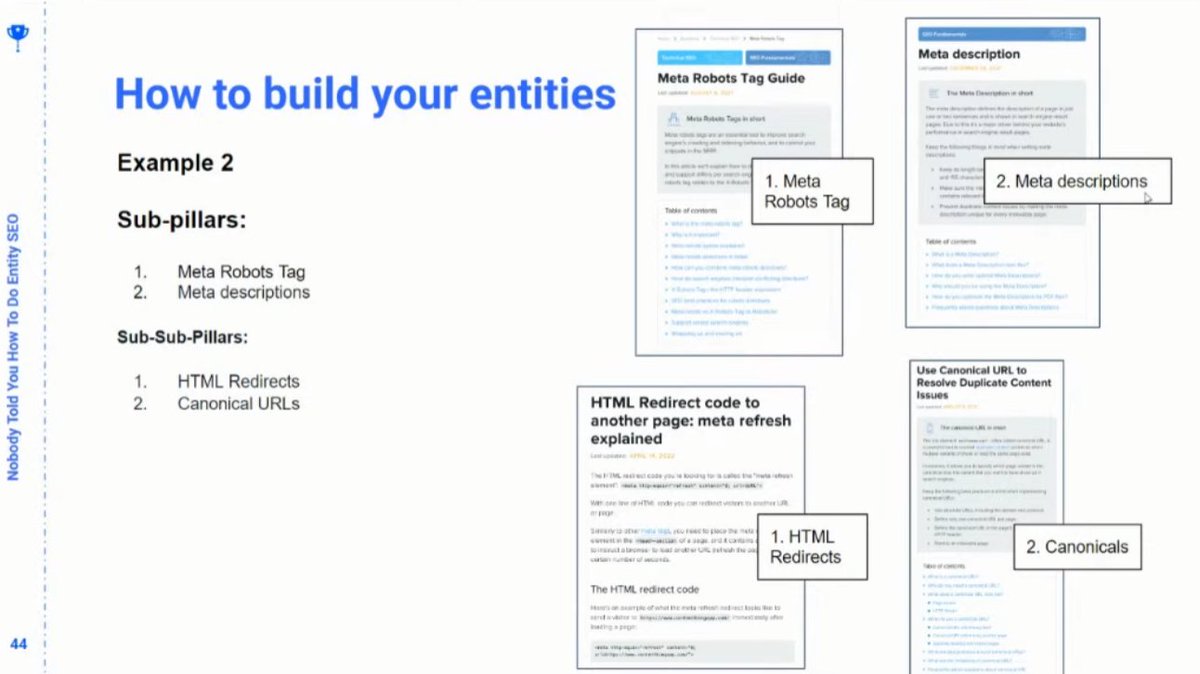
❯ If this sounds like classic SEO content strategy — it is!
❯ But we can use entities and entity relationships to build out the topics as Google understands and that are closely related in Google’s topic map
❯ Its harder for a non-expert to create this kind of content
❯ But we can use entities and entity relationships to build out the topics as Google understands and that are closely related in Google’s topic map
❯ Its harder for a non-expert to create this kind of content
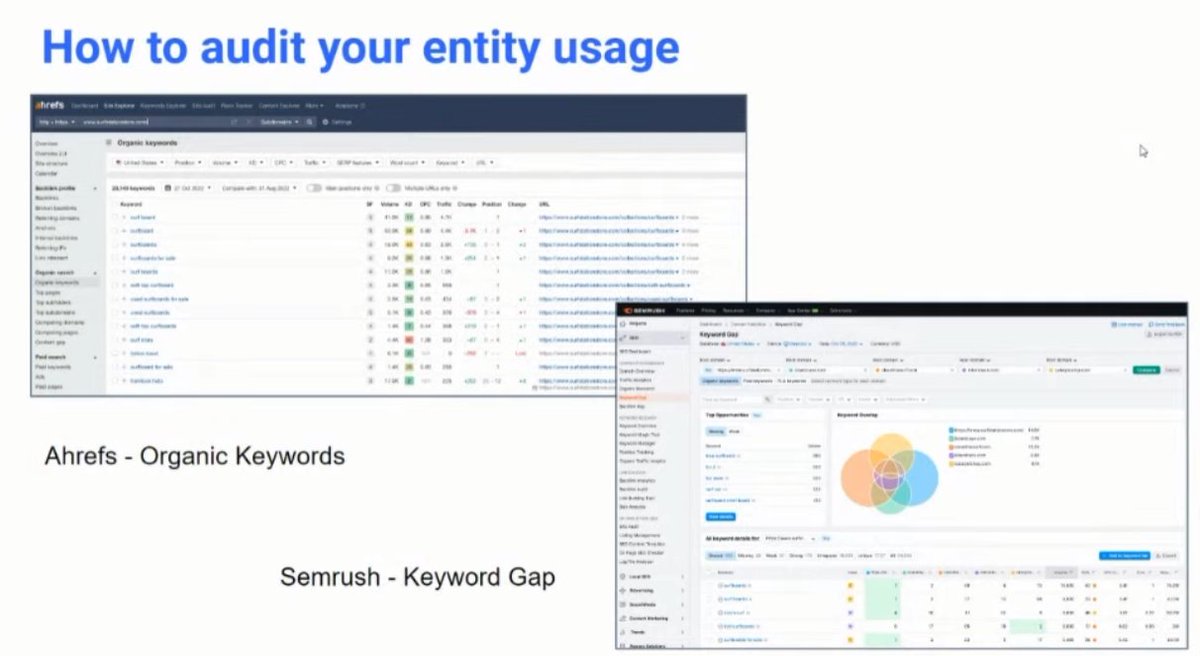
❯ You can go top-down or bottom up
❯ What are the organic keywords you’re currently ranking on, say, page 2–5, where you have topical significance but not salient?
❯ Build more content
❯ Build relationships with links
❯ What are the organic keywords you’re currently ranking on, say, page 2–5, where you have topical significance but not salient?
❯ Build more content
❯ Build relationships with links
❯ Even capitalization and punctuation can change entity understanding and salience
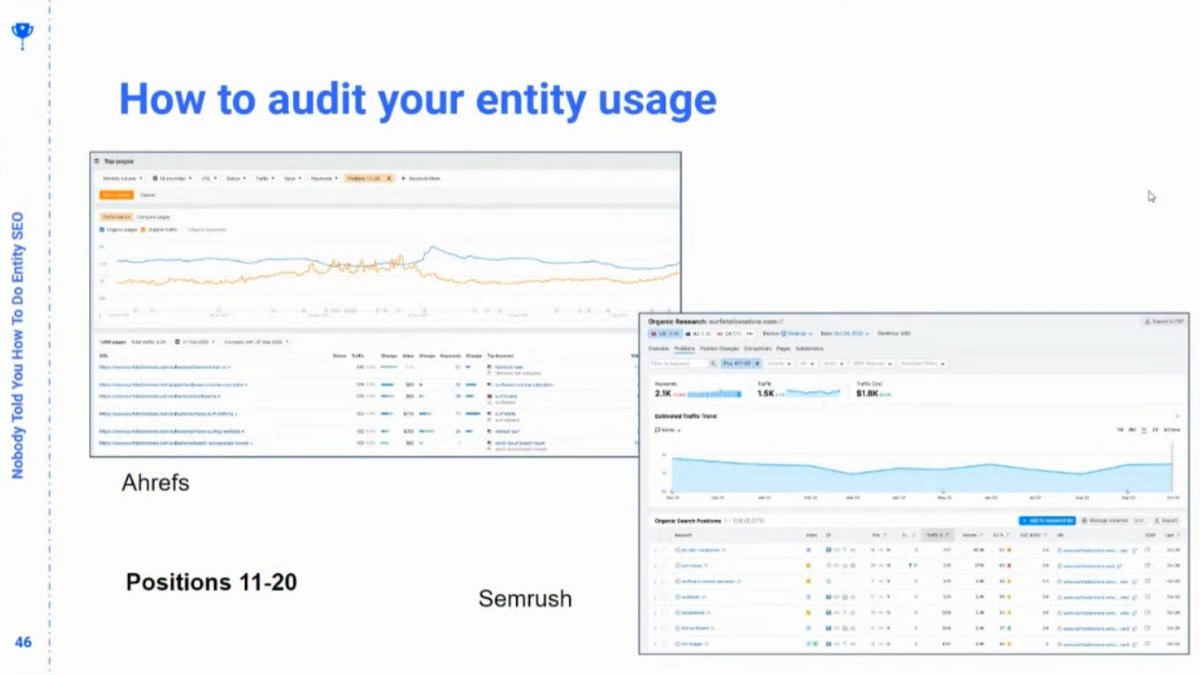
❯ Using Google’s API can help you understand how Google understands your content, but it doesn’t always score with with the right salience
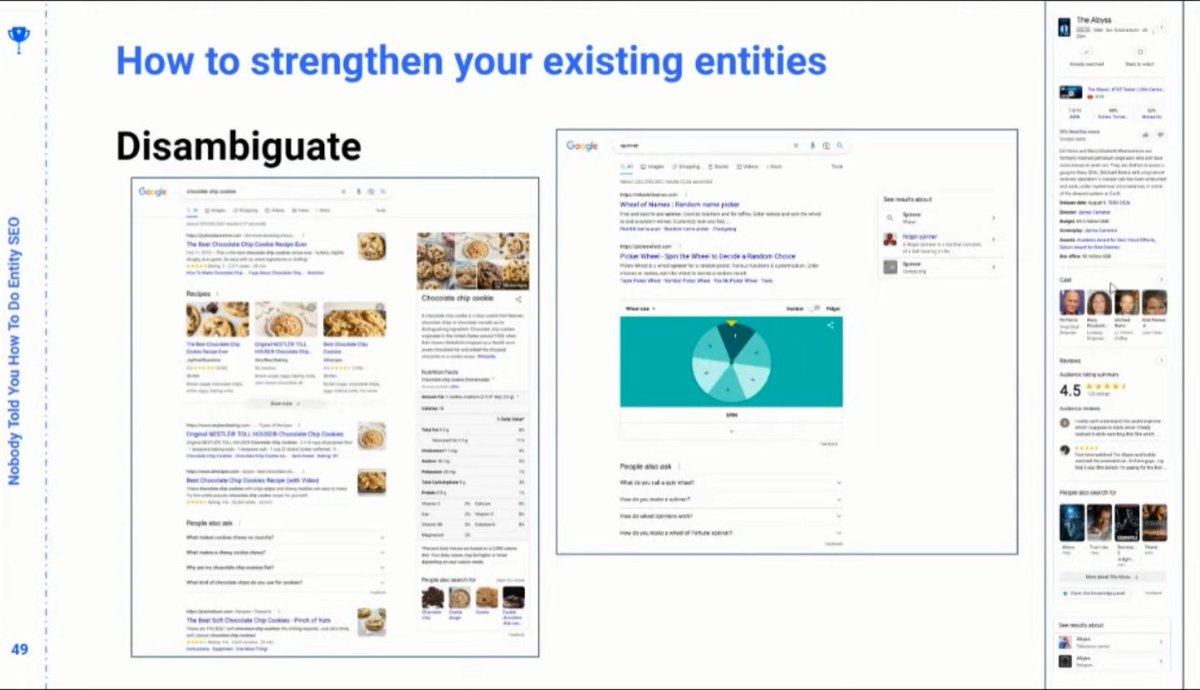
❯ We need to disambiguate and make it clear which our entities are NOT
❯ We need to disambiguate and make it clear which our entities are NOT
❯ Don’t bury the lede and reduce the semantic distance between entities @ruthburr
❯ Classic example: recipe blogs that lead with a lot of historical/narrative content before the recipe
❯ Serve quick search intent up front
❯ It’s a better UX and much clearer to search engines
❯ Classic example: recipe blogs that lead with a lot of historical/narrative content before the recipe
❯ Serve quick search intent up front
❯ It’s a better UX and much clearer to search engines

❯ Strengthen and disambiguate existing entities
❯ Surround entities with related entities
❯ Be careful with excessive pronoun use, replace the pronoun with the entity
❯ Create content deep in topic but highly machine readable
❯ Surround entities with related entities
❯ Be careful with excessive pronoun use, replace the pronoun with the entity
❯ Create content deep in topic but highly machine readable
<Had to exit meeting />
Returning to recorded video to finish meeting!
❯ Use semantic triples to strengthen relationships within your copy
❯ Be clear, consistent, concise, readable
❯ It’s better writing, and people like to read it.
❯ If you’re saying “it” or “them,” to what are you referring?
❯ Use semantic triples to strengthen relationships within your copy
❯ Be clear, consistent, concise, readable
❯ It’s better writing, and people like to read it.
❯ If you’re saying “it” or “them,” to what are you referring?
❯ Link to subjections with HTML anchors
<a href="#content">TOC Anchor</h2>
…
<h2 id="content">Heading of Content</h2>
<a href="#content">TOC Anchor</h2>
…
<h2 id="content">Heading of Content</h2>
❯ Use semantic Markup
❯ Avoid <div> soup
Why using semantic markup is important in web design and development
seekbrevity.com/semantic-marku…
❯ Avoid <div> soup
Why using semantic markup is important in web design and development
seekbrevity.com/semantic-marku…

❯ Use Schema:
❯ Don’t forget "about" and "mentions" to disambiguate
Why Is No One Talking About Entity SEO?
inlinks.net/p/insight/why-…
❯ Don’t forget "about" and "mentions" to disambiguate
Why Is No One Talking About Entity SEO?
inlinks.net/p/insight/why-…
❝Mark up judiciously, don’t mark up things that aren’t there or lie in your markup because that’s a waste of your time and you’re embarrassing yourself.❞ – @ruthburr #SEO
❯ The whole point of markup is to help search engines understand what a piece of information is and where it is on your page
❝If someone is using ids inconsistently, and putting everything in a <div>, and it’s not very what the order is – that’s very bad for accessibility as well.❞ -@iPullRank
❯ We need to stop thinking about only marking up something to appear in the search. It’s better to mark up everything that’s relevant on the page so there are more opportunities to have information extracted the way we ant and use them in the SERPs.
❯ Markup is also used on the backend of things not just for SERP features, but also to help search engines just understand the page
❯ Be clear, consistent, and readable
❯ Use a readability tool
@yoast, @Grammarly, @HemingwayApp (@INK_4all – Rich)
❯ It’s not about getting to “grade four” reading level, but achieving consistency, clarity, and avoiding jargon
❯ A tool gets you out of your head
❯ Use a readability tool
@yoast, @Grammarly, @HemingwayApp (@INK_4all – Rich)
❯ It’s not about getting to “grade four” reading level, but achieving consistency, clarity, and avoiding jargon
❯ A tool gets you out of your head

❯ Link both internally and externally
❯ The links out to related entities help strengthen the connections between the main entities of the pages and within anchors, etc.
❯ Linking to expert and semantically related entities is also useful for users
❯ The links out to related entities help strengthen the connections between the main entities of the pages and within anchors, etc.
❯ Linking to expert and semantically related entities is also useful for users

❯ Connect questions and answers, reduces semantic distance between entities
❯ Don’t bury the lede
❯ Don’t be annoying
❯ Don’t ask the question and take 500 words to answer it
❯ Google will forget the question by the time it gets to the answer
❯ Don’t bury the lede
❯ Don’t be annoying
❯ Don’t ask the question and take 500 words to answer it
❯ Google will forget the question by the time it gets to the answer

❯ Have a point of view
❯ If you are not adding anything to what the top-ranked pages already say, why should you rank?
❯ Add unique information, like Content King’s <meta> TL;DR content shown below
❯ (Sometimes called “Information Gain” – Rich)
❯ If you are not adding anything to what the top-ranked pages already say, why should you rank?
❯ Add unique information, like Content King’s <meta> TL;DR content shown below
❯ (Sometimes called “Information Gain” – Rich)

❯ Entity Optimization Checklist
❯ PDF available after Webinar
❯ PDF available after Webinar

❯ A related issue is Google’s use of the Multitask Unified Model (MUM), which allows you to do search that is multimodal (multi-search features). Entities are deeply important because the keyword is GONE. Google’s entity understanding drives this multimodal search. – @Suzzicks
❯ It’s the future, but it’s also here now, like when you walk up to a monument ask Google "Hey, Google, what am I standing in front of?" Google figures it out based on your location, and so on. –@iPullRank
❯ How do we measure entity SEO performance?
❯ At the end of the day: Did what we do improve rankings?
❯ At the end of the day: Did what we do improve rankings?
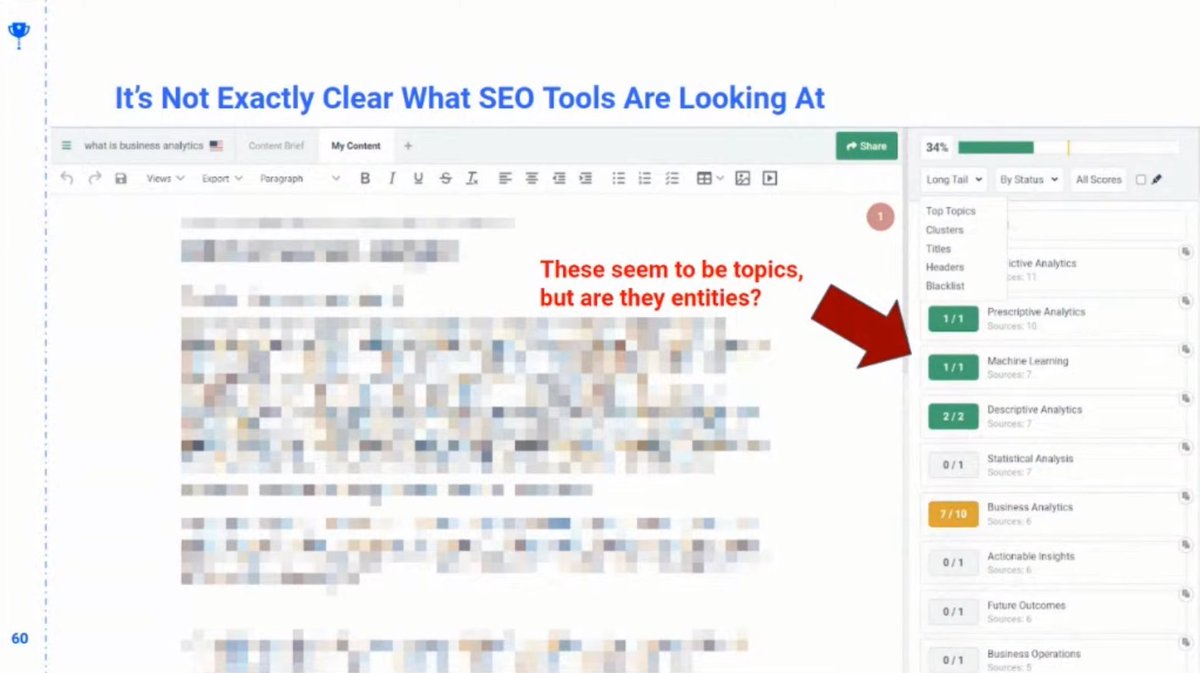
❯ Do Entity SEO Tools Fall short?
❯ A lot of content optimization tool say they’re doing entity related stuff, but there’s no evidence of that.
❯ If they are and I just don’t know, send email me at mike @ ipullrank.com I’ll recant my statement!
❯ A lot of content optimization tool say they’re doing entity related stuff, but there’s no evidence of that.
❯ If they are and I just don’t know, send email me at mike @ ipullrank.com I’ll recant my statement!

❯ Example: Frase is a great tool
❯ It encourages talking more about specific topics – but there’s no indication that it’s actually using entities
❯ Frase may be using entities, but it’s not clear at all
❯ It encourages talking more about specific topics – but there’s no indication that it’s actually using entities
❯ Frase may be using entities, but it’s not clear at all
❯ Ryte’s Content Success is also a great tool. It may get you there even if it’s not explicitly looking for entities
❯ These tools look vertically at a SERP but fail to look horizontally at the entities & their relationships
❯ Co-ocurring terms MAY overlap with entities
❯ These tools look vertically at a SERP but fail to look horizontally at the entities & their relationships
❯ Co-ocurring terms MAY overlap with entities

❯ SearchMetric’s Content Experience does look across the graph at the topics to find related terms
❯ But a topical cluster is not the same as entities
❯ But a topical cluster is not the same as entities
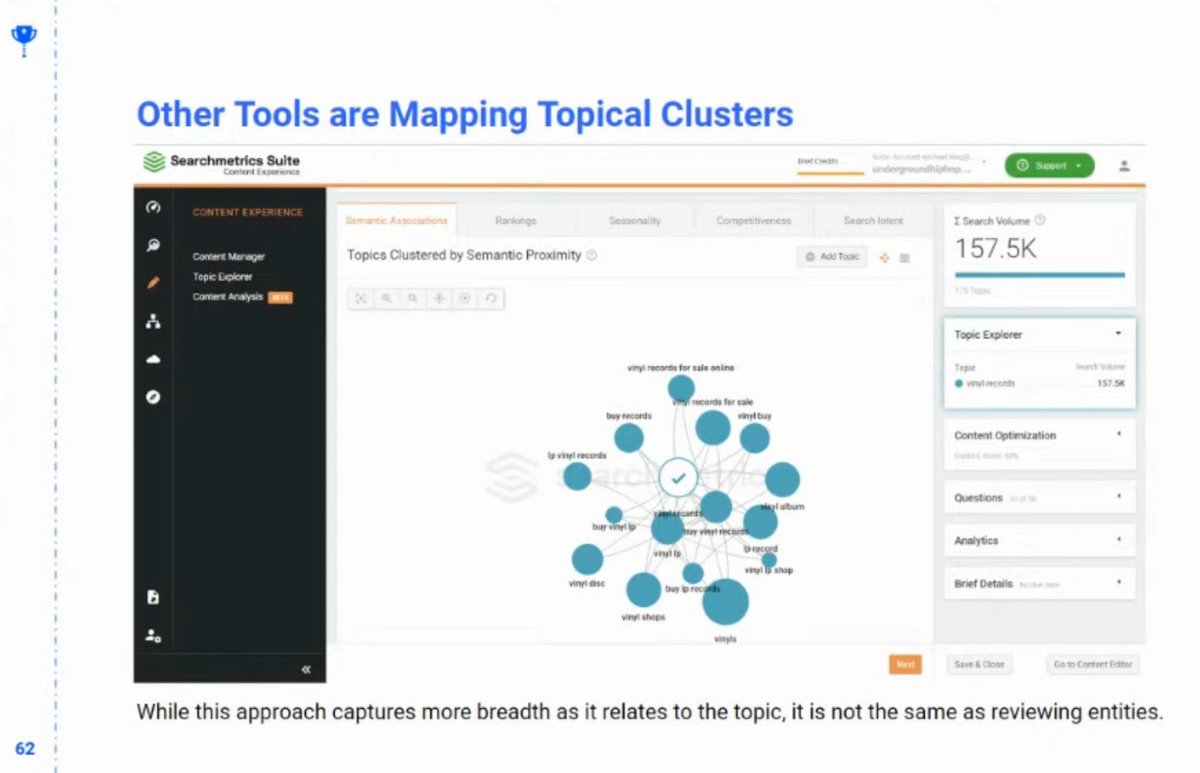
❯ There are tools that unearth what’s in the semantic web
❯ @EntitreeApp (entitree.com) gives you a "tree" of entities based on your prompt
❯ It pulls from WikiData & shows the other entities that are subclasses
❯ Look across all of these when researching
❯ @EntitreeApp (entitree.com) gives you a "tree" of entities based on your prompt
❯ It pulls from WikiData & shows the other entities that are subclasses
❯ Look across all of these when researching

❯ You can’t optimize for an entity if Google doesn’t know about it
❯ Use the NLP API to determine what entities are actually in Google’s data set
❯ Use the NLP API to determine what entities are actually in Google’s data set
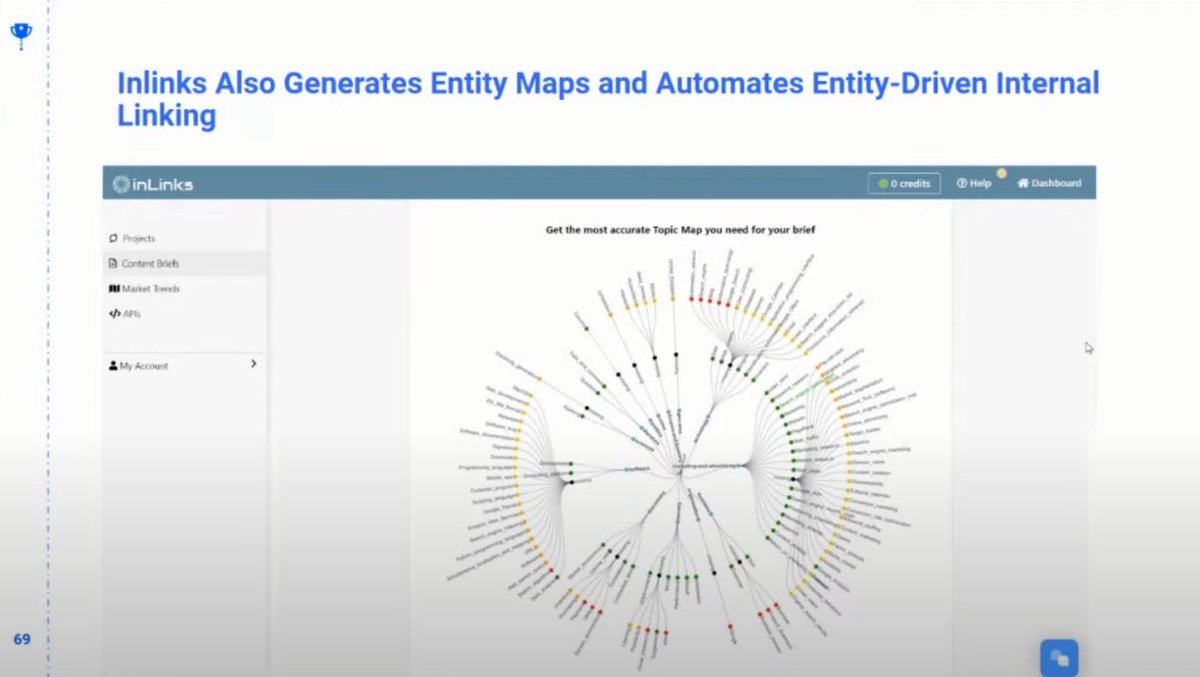
❯ @InLinks maps topics (but they’re actually entities)
❯ Crawls site and builds a taxonomy/entity map based on your content post-crawl
❯ Can generate internal links based on pages with common entities
❯ Can help you generate your schema
❯ Also have a readability tool
❯ Crawls site and builds a taxonomy/entity map based on your content post-crawl
❯ Can generate internal links based on pages with common entities
❯ Can help you generate your schema
❯ Also have a readability tool
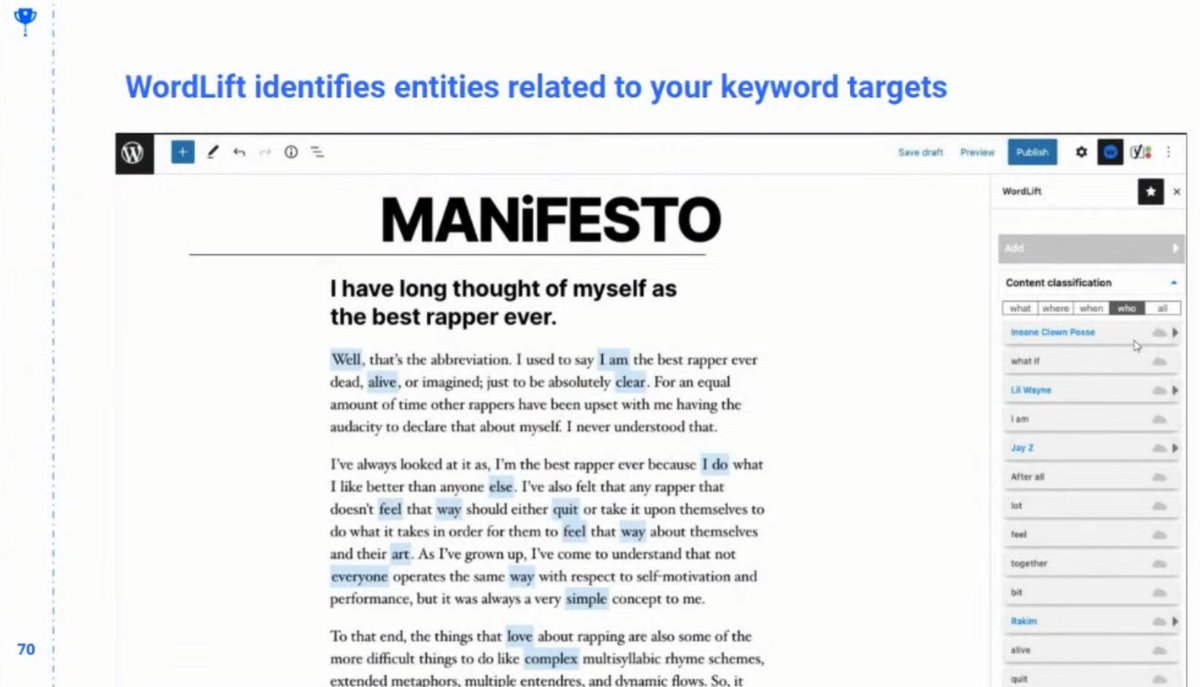
❯ @wordliftit Can do the same thing but it also has a WordPress plugin so you work directly in the website
❯ Wordlift can suggest additional entities that you might want to talk about
❯ Builds a knowledge graph based on your content
❯ Also has an internal knowledge graph
❯ Wordlift can suggest additional entities that you might want to talk about
❯ Builds a knowledge graph based on your content
❯ Also has an internal knowledge graph
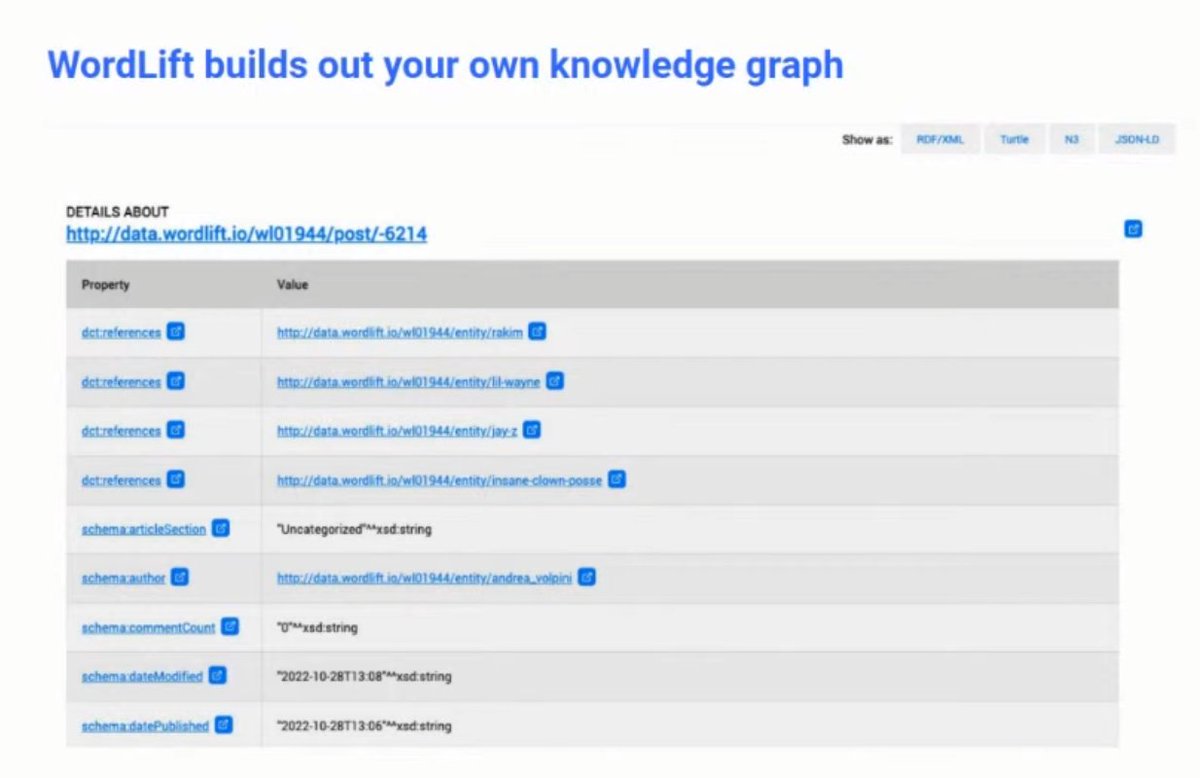
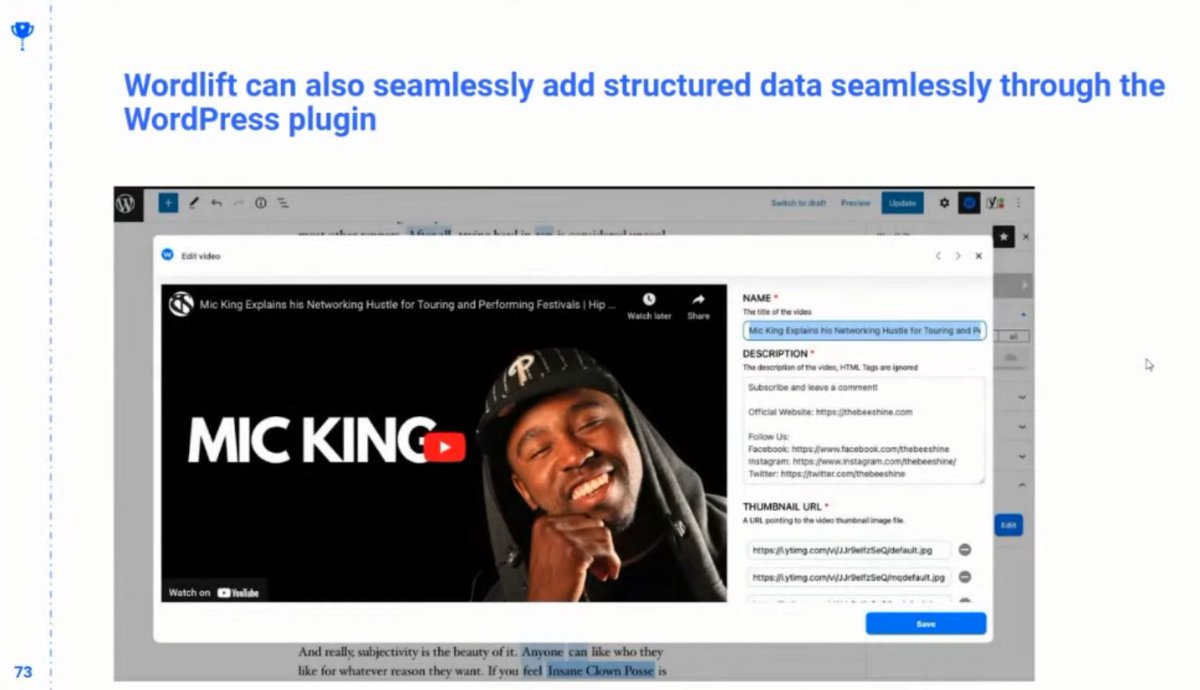
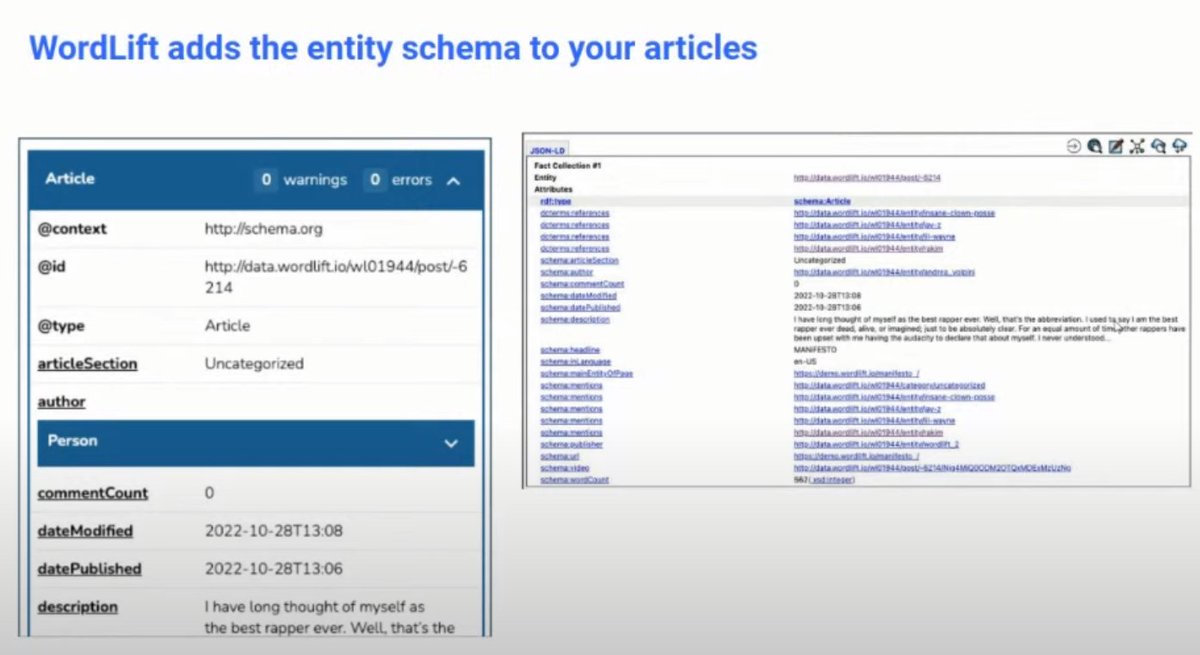
❯ Wordlift also adds schema directly and seamlessly to content
❯ @wordliftit also provides a connect to Looker/Google Data Studio, so you can track the actual performance of your topical clusters, entity optimization, and idetntify gaps
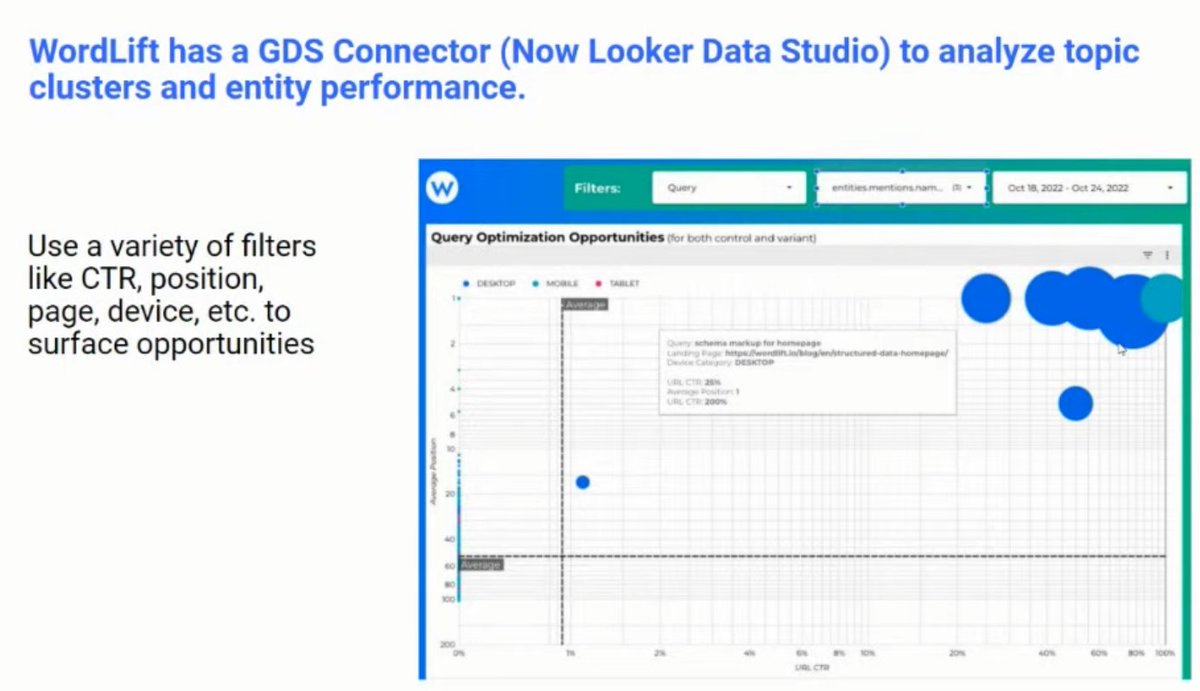
❯ Using free tools like SpaCy NLP (Python), you can use a Google Colab that @iPullRank set up, you can enter copy, provide a URL or upload a file
❯ Will show you the entities used in your copy right there
❯ Will show you the entities used in your copy right there
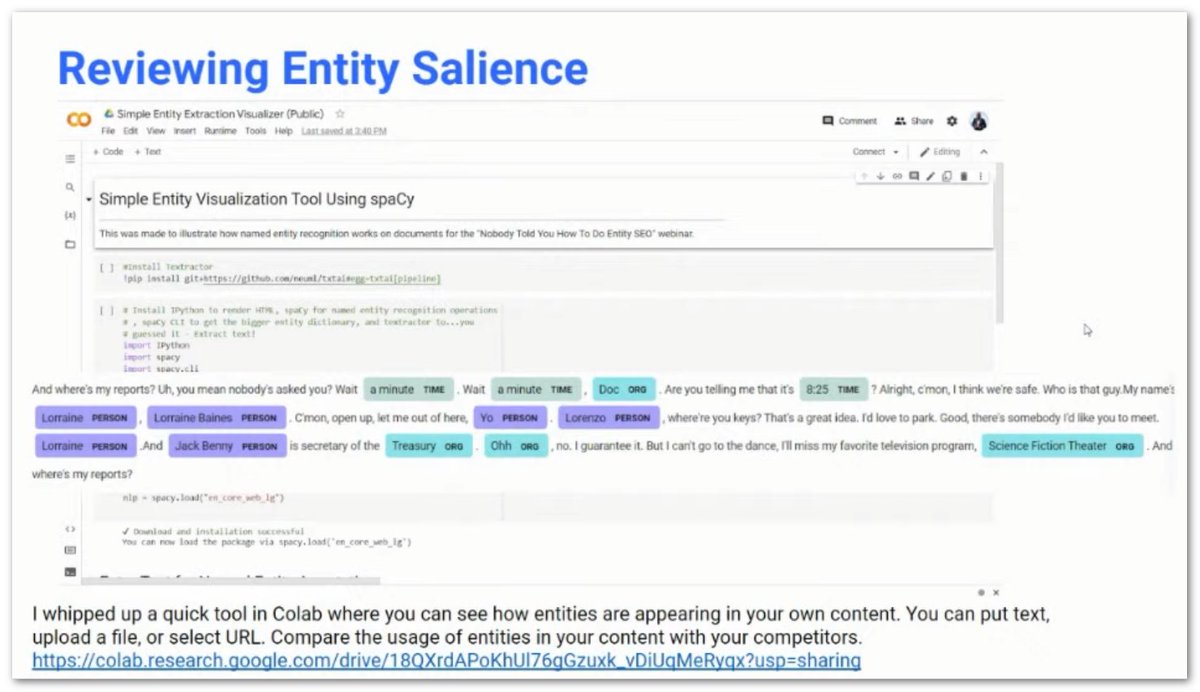
❝If you want to learn something, SpaCy is the next thing I’d suggest you learn.❞ – @ruthburr
Parting Thoughts:
Install GA4! lol Also look at your content where you’re ranking on page two and run it through Google’s NLP API and see what you can do to improve salience. – @ruthburr
Install GA4! lol Also look at your content where you’re ranking on page two and run it through Google’s NLP API and see what you can do to improve salience. – @ruthburr
Parting Thoughts:
Start with a tool like @InLinks or @ryte and start evaluating and getting benchmarks where you and your competitors are at so you can prioritize. – @Suzzicks
Start with a tool like @InLinks or @ryte and start evaluating and getting benchmarks where you and your competitors are at so you can prioritize. – @Suzzicks
Parting Thoughts:
@wordliftit, @InLinks, definitely. Also, just mess around with Wikidata, put in your queries and see what comes back so you get more familiar with them when you start your keyword research and start writing. – @iPullRank
@wordliftit, @InLinks, definitely. Also, just mess around with Wikidata, put in your queries and see what comes back so you get more familiar with them when you start your keyword research and start writing. – @iPullRank
• • •
Missing some Tweet in this thread? You can try to
force a refresh






