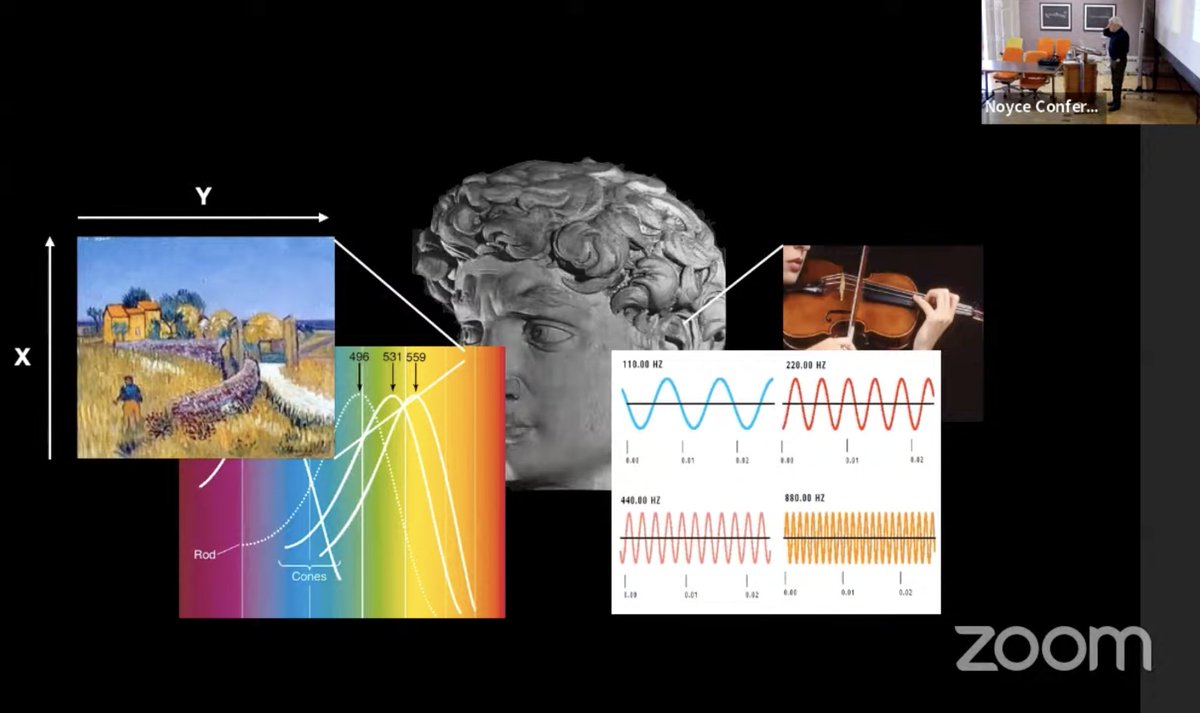
"Compositionality in Vector Space Models of Meaning"
Today's SFI Seminar by @marthaflinders, streaming:
Follow this 🧵 for highlights!
Today's SFI Seminar by @marthaflinders, streaming:
Follow this 🧵 for highlights!

"Scientists gather here
Santa Fe Institute, oh so near
Inquiring minds seek truth"
#haiku about SFI c/o @marthaflinders & #ChatGPT
...but still, #AI fails at simple tasks:
Santa Fe Institute, oh so near
Inquiring minds seek truth"
#haiku about SFI c/o @marthaflinders & #ChatGPT
...but still, #AI fails at simple tasks:


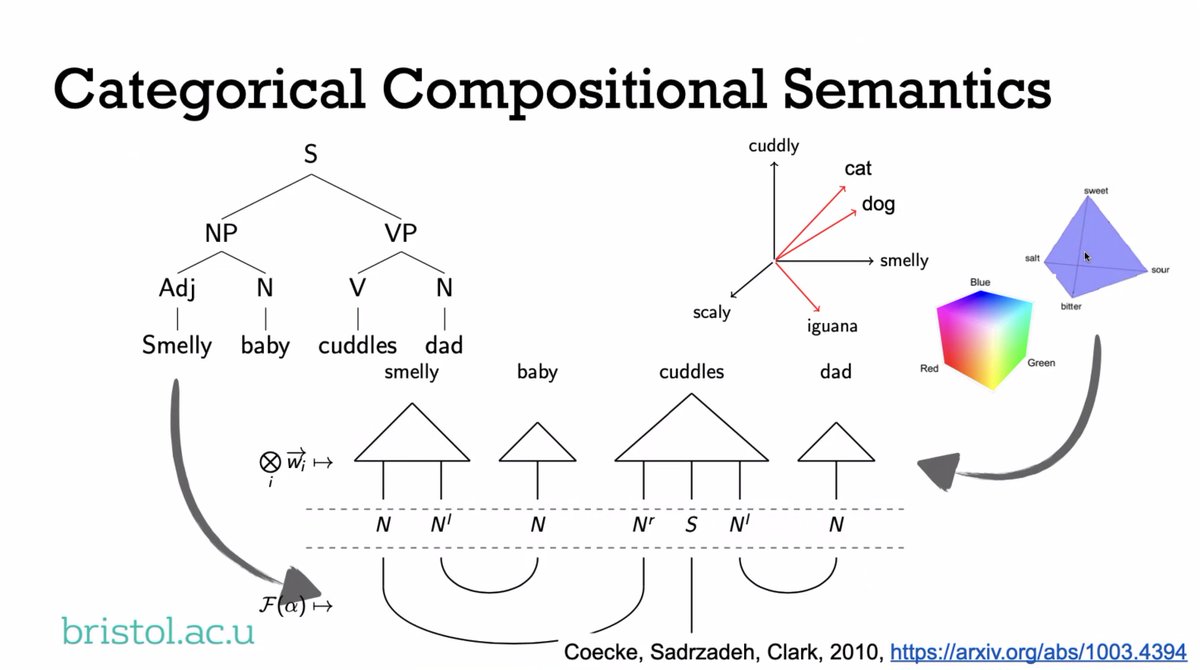
"One way to represent the kind of #compositionality we want to do is with this kind of breakdown...eventually a kind of representation of a sentence. On the other hand, vector space models of #meaning or set-theoretical models put into a space have been very successful..."

"We can take the grammatical structure of the sentence and build up word representations... We take pre-group grammar and build up functional words by concatenating...and then cancelling out the types."
Link to relevant pre-print:
arxiv.org/abs/1003.4394
Link to relevant pre-print:
arxiv.org/abs/1003.4394
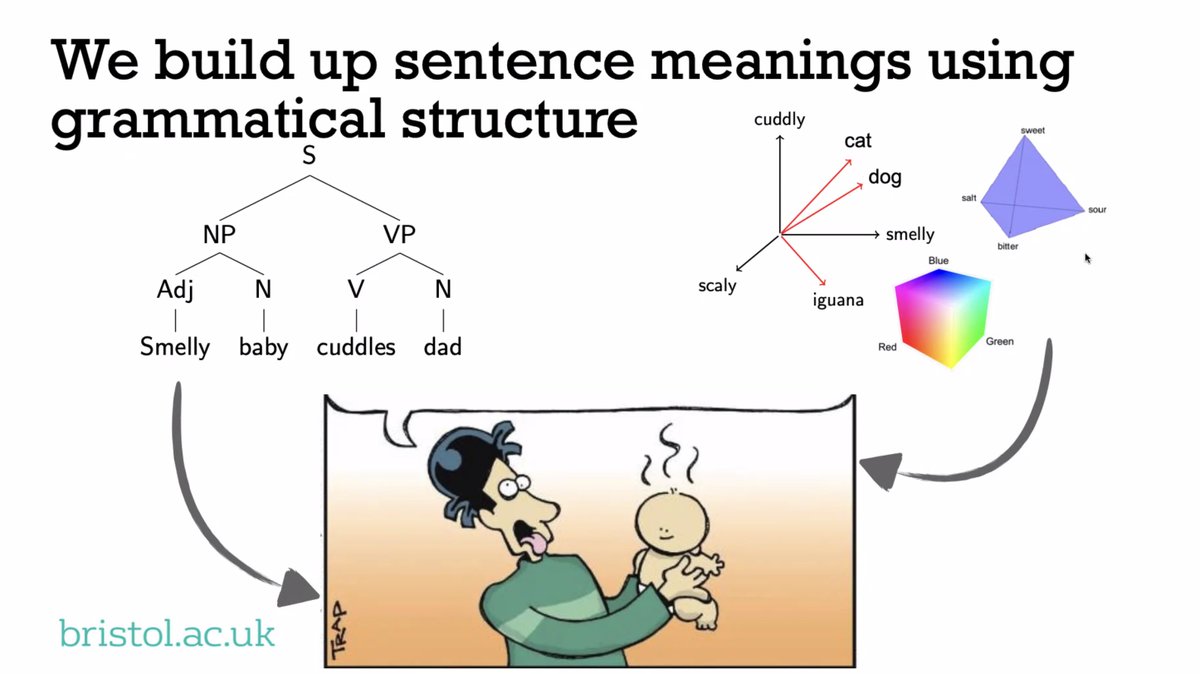


Alternatively, role-filler models view symbolic structure as a set of role and filler bindings, bringing together distinct vector spaces for each:


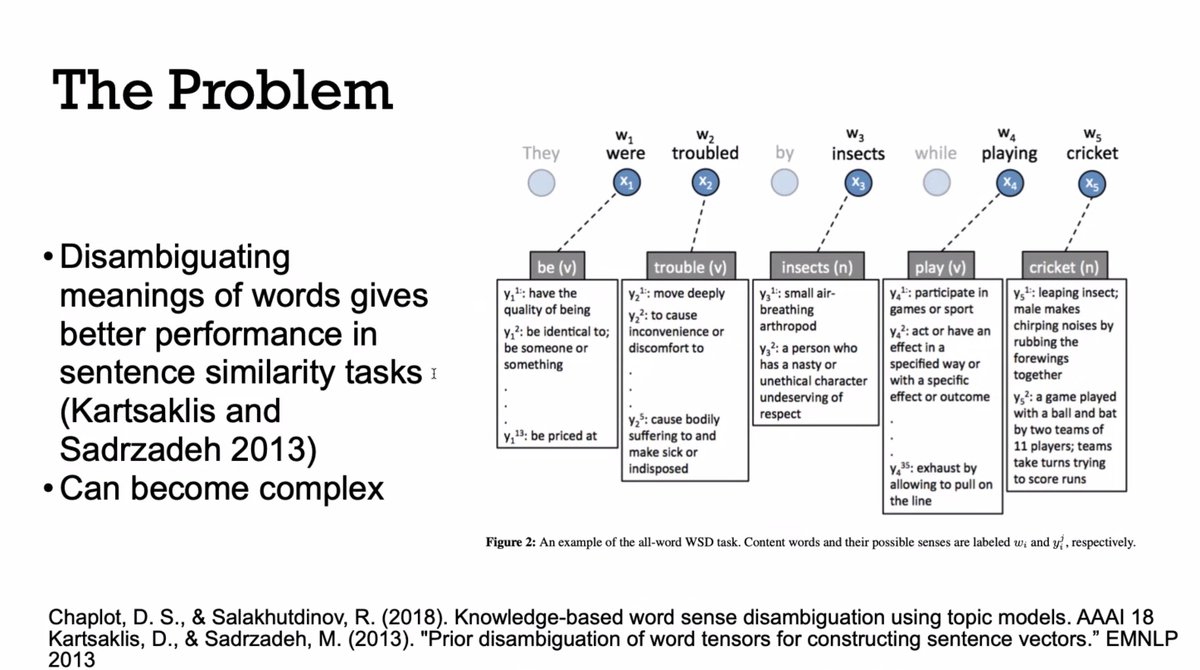
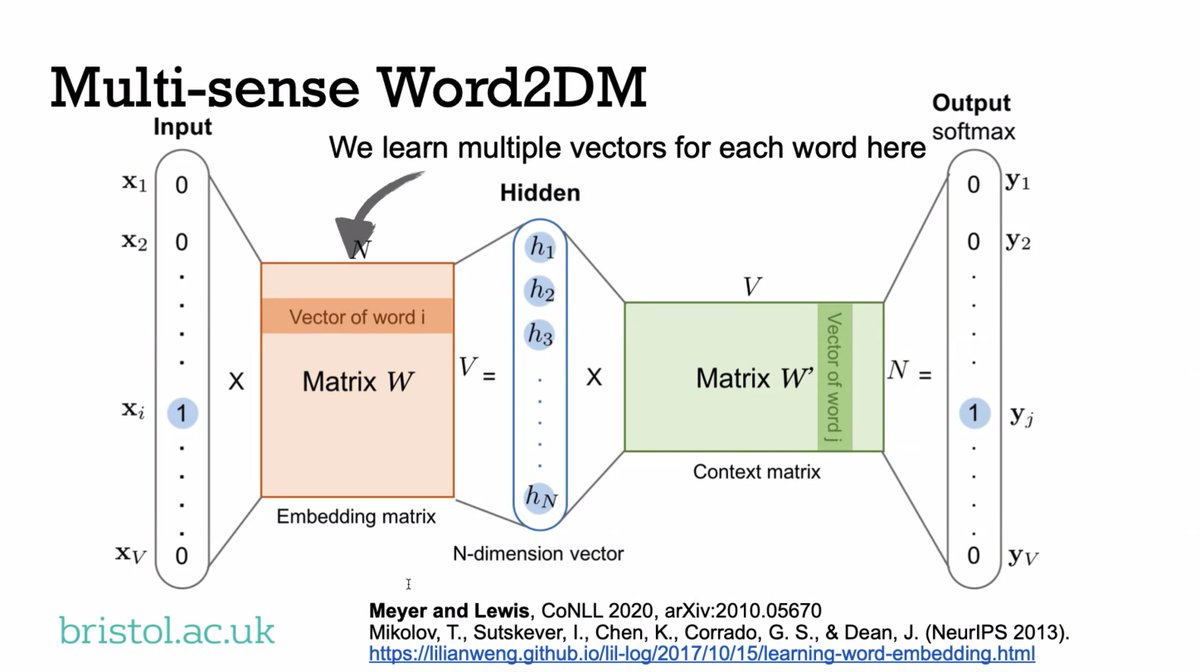
"One problem is that words have multiple meanings. If you want to work out the contextual meaning of a word you have to work out the contextual meaning of other words. It can become quite complex. We would like the ambiguity of words to resolve by using compositional approaches."

"If you have two different senses of a word — bed as in river and bed as in sleep — then you can represent it as a probabilistic mixture of these different senses."
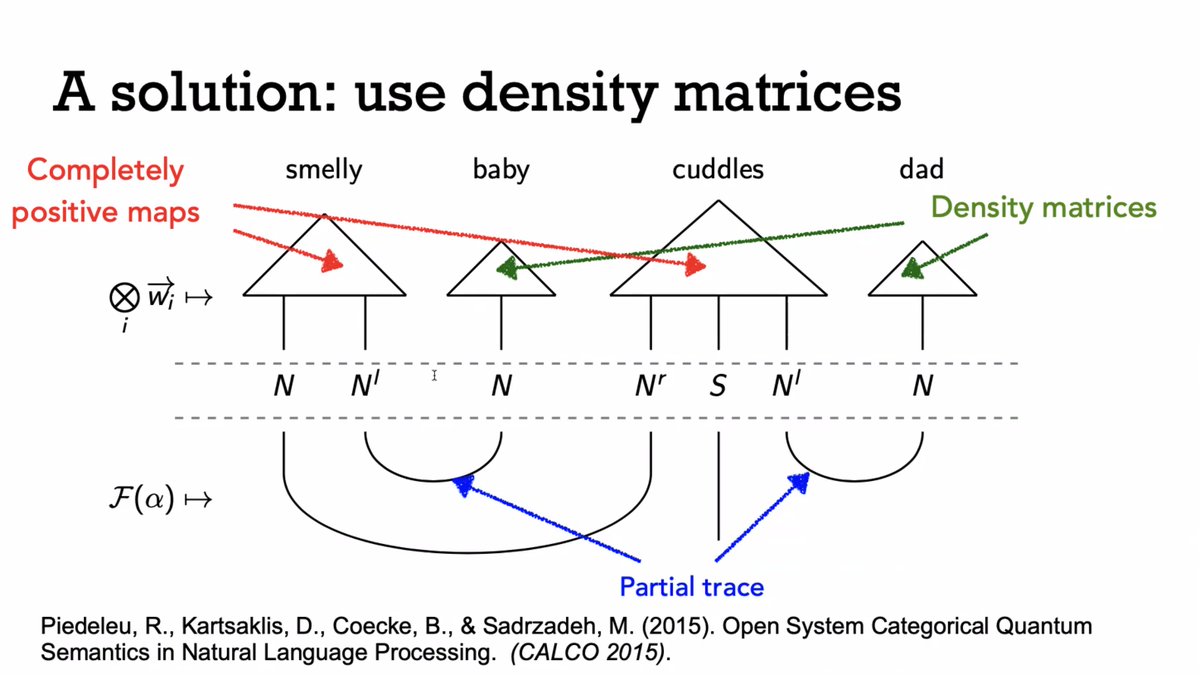


"When you use these representations, what you find is that the mixed-ness, the measure of the ambiguity of the phrase, goes down in comparison to the ambiguity of the noun."
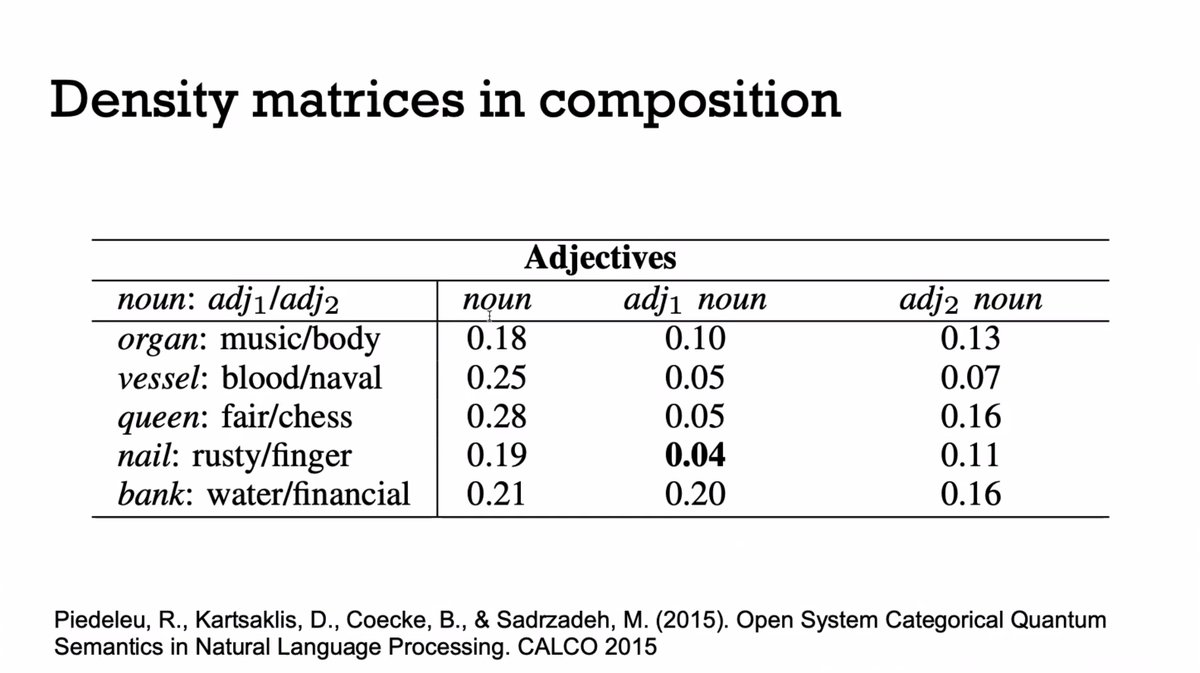
"So how do we build these things? I gave one way but it's kind of limited because you need word vectors."
"So how do we build these things? I gave one way but it's kind of limited because you need word vectors."


Another neural approach:
"The task is to build representations of each sentence and then measure which ones are most similar to each other."
"The task is to build representations of each sentence and then measure which ones are most similar to each other."
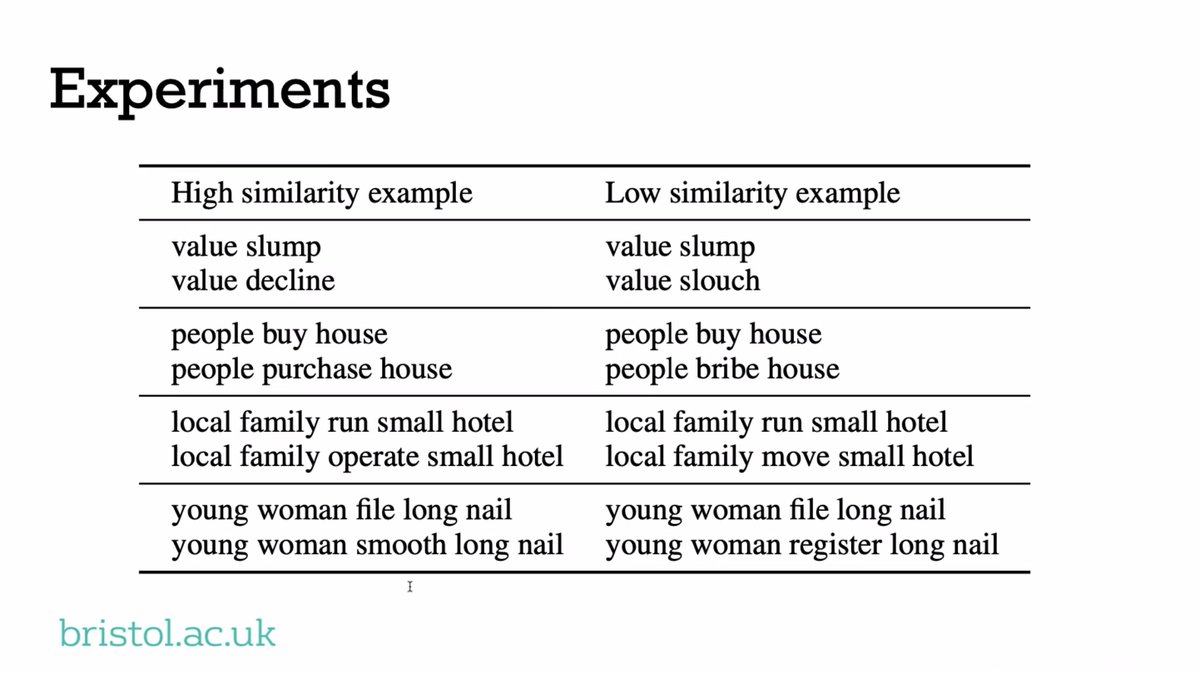
"In this work we created a data set that has specifically very metaphorical sentences, and ALL of the models found that harder."


"We feed images into an encoder, and then we train compositional image models to give us some vectors. The other possibilities are not in the image, so there isn't ambiguity."
"We give the system labels that are and are not in the image and it has to pull out the correct labels."
"We give the system labels that are and are not in the image and it has to pull out the correct labels."

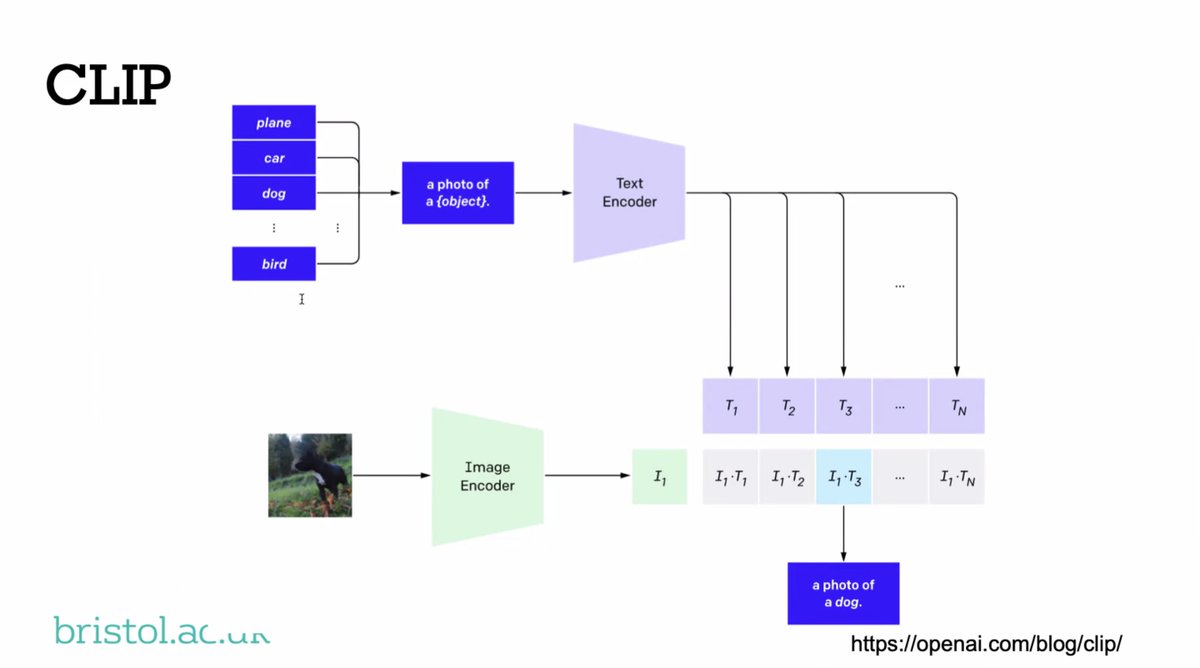


"The CLIP models and the role-filler models don't do very well. But type-logical models do — about 100% of the training set — but can't generalize... Even the compositional models are not fantastic."

1) Additional resources on whether LLMs can be trained for generalization.
2) "One thing I've been playing around with..."
3) "Actually, language is used in dialogue to describe things outside of the text. So how do we incorporate images into these compositional models?"
2) "One thing I've been playing around with..."
3) "Actually, language is used in dialogue to describe things outside of the text. So how do we incorporate images into these compositional models?"




• • •
Missing some Tweet in this thread? You can try to
force a refresh