😜¡No seas un inocente del #DataScience !
⚠️Aunque el #MachineLearning puede ser una herramienta poderosa, siempre es importante evaluar y validar tus modelos antes de confiar demasiado en ellos.
😱¿Cómo evaluar y validar modelos de #ML? 👉(Hilo 🧵)
#RStats #analytics #stats #IA
⚠️Aunque el #MachineLearning puede ser una herramienta poderosa, siempre es importante evaluar y validar tus modelos antes de confiar demasiado en ellos.
😱¿Cómo evaluar y validar modelos de #ML? 👉(Hilo 🧵)
#RStats #analytics #stats #IA

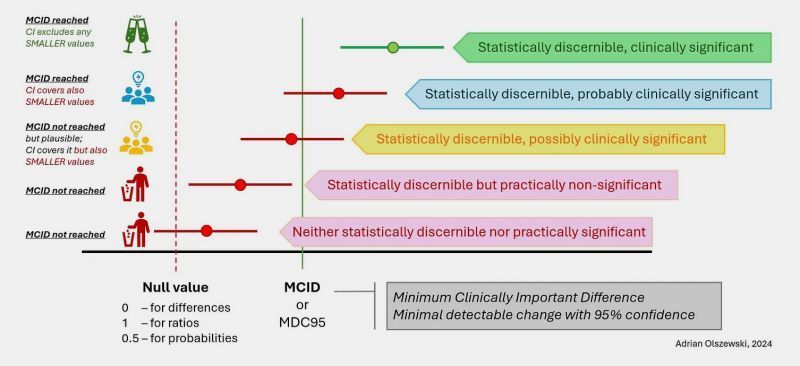
✅ Dividir los datos disponibles en dos (o más) conjuntos. Se entrena el modelo con un conjunto de entrenamiento y luego se mide su rendimiento en un conjunto de prueba. Así obtienes una estimación del rendimiento del modelo en datos que no ha visto antes
#ML #IA #DataScience
#ML #IA #DataScience
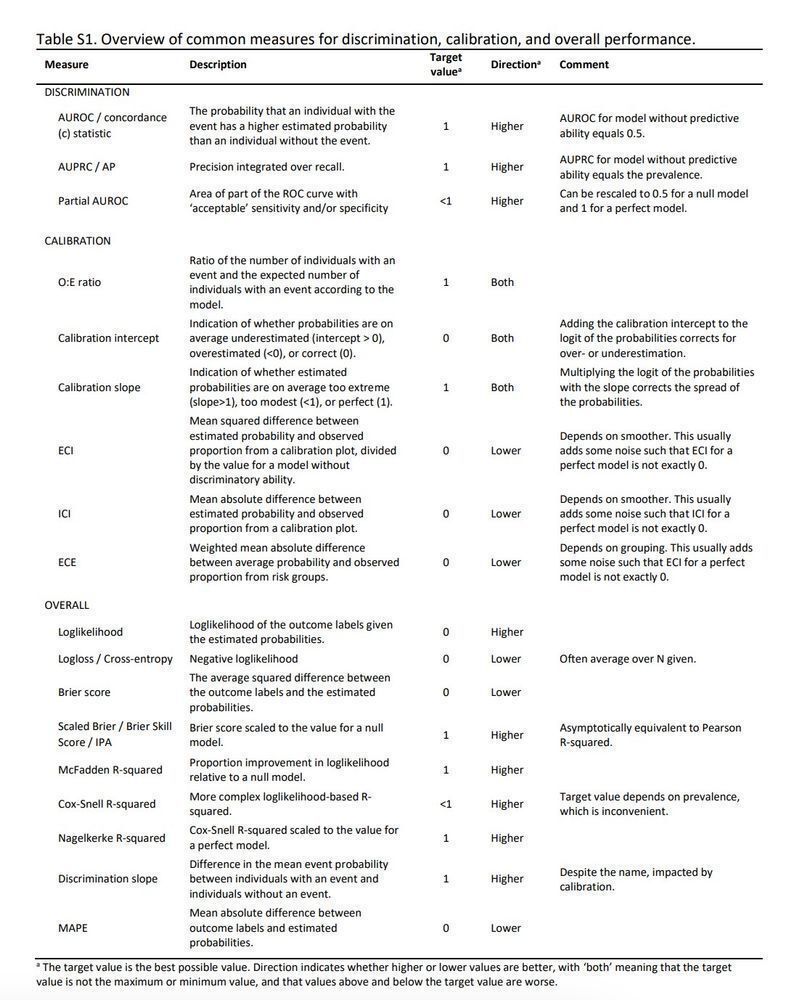
✅ Utilizar métricas de evaluación apropiadas: Dependiendo del tipo de problema y modelo, existen diferentes métricas que se pueden utilizar para evaluar el rendimiento del modelo.
E.g. para clasificación la precisión o recall, para regresión el error cuadrático medio o RMSE
#ML
E.g. para clasificación la precisión o recall, para regresión el error cuadrático medio o RMSE
#ML

✅ Validación cruzada: dividir los datos en varios conjuntos y entrenar y evaluar el modelo varias veces, cada vez utilizando un conjunto diferente como prueba y promediando los resultados. Da una estimación más robusta del rendimiento del modelo ya que utiliza más datos.
#ML #IA
#ML #IA
✅ Validación del rendimiento en el mundo real, una vez que se ha implementado. Esto puede incluir medir la precisión del modelo en tareas reales o monitorear el rendimiento del modelo a lo largo del tiempo para ver si mantiene su rendimiento
#DataScience #MachineLearning #ML #IA
#DataScience #MachineLearning #ML #IA
• • •
Missing some Tweet in this thread? You can try to
force a refresh