1/6: Venn diagrams are commonly used in bioinformatics to visualize the overlap of different sets of genes or proteins. There are several R packages available for creating these diagrams, including VennDiagram, ggvenn, and ggVennDiagram. #rstats #datascience #bioinformatics 
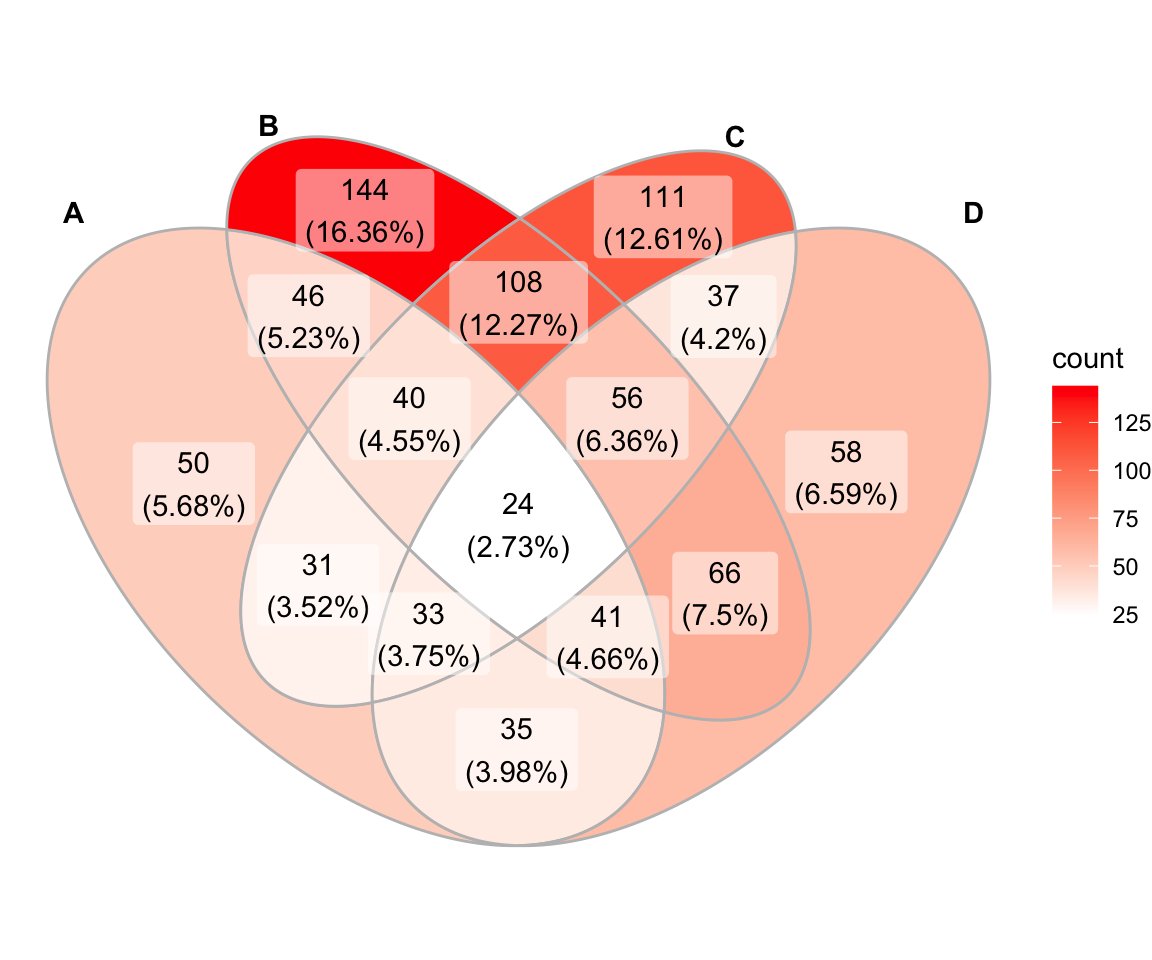
2/6: VennDiagram is a widely used package for creating classic Venn diagrams with up to six sets. It offers a range of options for customizing the appearance of the diagram, including font size, color, and label placement. #rstats #bioinformatics
3/6: One of the advantages of VennDiagram is the ability to easily incorporate statistical analyses. For example, you can calculate the significance of the overlap between different sets of genes or proteins and display this information on the diagram. #rstats #bioinformatics
4/6: ggvenn is another package for creating Venn diagrams in R. It uses the ggplot2 package to produce plots that are more customizable and aesthetically pleasing. ggvenn supports up to four sets, and allows for custom color palettes and label formatting. #rstats #bioinformatics
5/6: ggVennDiagram is a newer package that offers similar functionality to ggvenn, but with some additional features. For example, ggVennDiagram can handle up to seven sets and allows for more fine-grained control over the appearance of the diagram. #rstats #bioinformatics
6/6: When choosing which package to use for Venn diagrams in bioinformatics, it's important to consider factors such as the number of sets you need to visualize, the level of customization you require, and the statistical analyses you want to perform. #rstats #bioinformatics
• • •
Missing some Tweet in this thread? You can try to
force a refresh








